 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmory: Building Coherent Narrative-Driven Agent Memory through Agentic Reasoning
Jan 09, 2026Long-term conversational agents face a fundamental scalability challenge as interactions extend over time: repeatedly processing entire conversation histories becomes computationally prohibitive. Current approaches attempt to solve this through memory frameworks that predominantly fragment conversations into isolated embeddings or graph representations and retrieve relevant ones in a RAG style. While computationally efficient, these methods often treat memory formation minimally and fail to capture the subtlety and coherence of human memory. We introduce Amory, a working memory framework that actively constructs structured memory representations through enhancing agentic reasoning during offline time. Amory organizes conversational fragments into episodic narratives, consolidates memories with momentum, and semanticizes peripheral facts into semantic memory. At retrieval time, the system employs coherence-driven reasoning over narrative structures. Evaluated on the LOCOMO benchmark for long-term reasoning, Amory achieves considerable improvements over previous state-of-the-art, with performance comparable to full context reasoning while reducing response time by 50%. Analysis shows that momentum-aware consolidation significantly enhances response quality, while coherence-driven retrieval provides superior memory coverage compared to embedding-based approaches.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025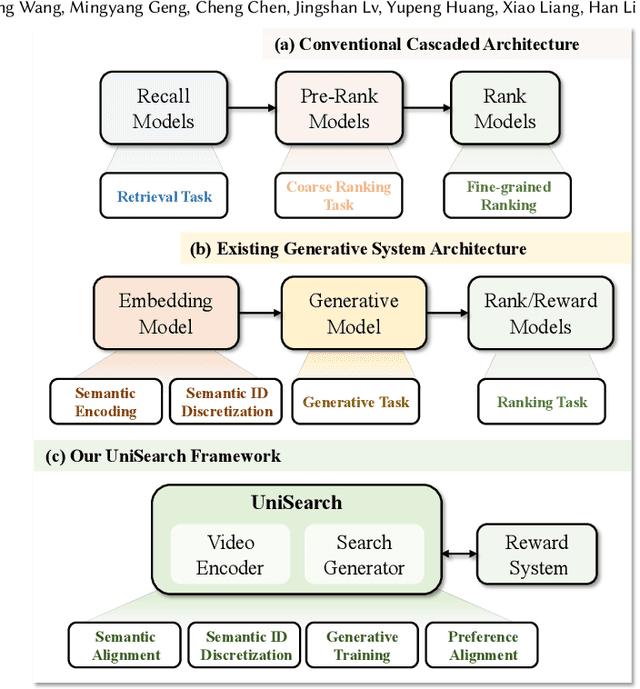
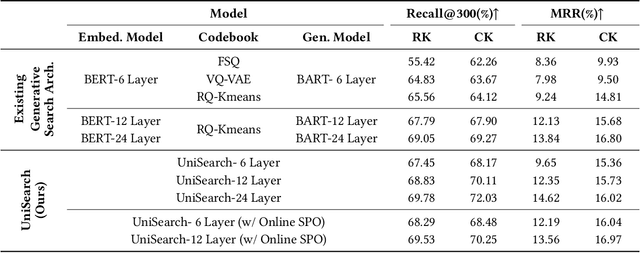
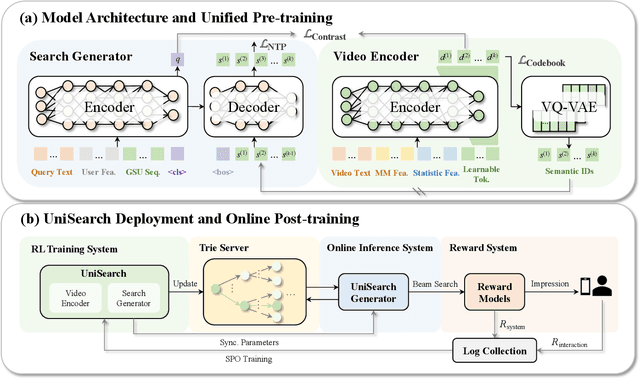
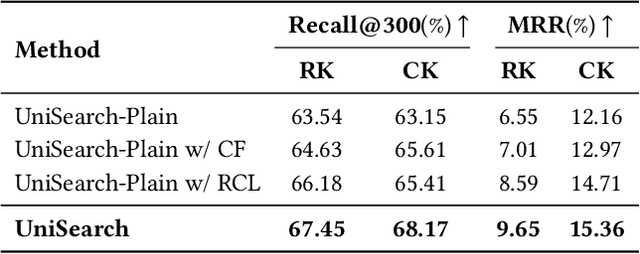
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Benchmarking AI scientists in omics data-driven biological research
May 13, 2025The rise of large language models and multi-agent systems has sparked growing interest in AI scientists capable of autonomous biological research. However, existing benchmarks either focus on reasoning without data or on data analysis with predefined statistical answers, lacking realistic, data-driven evaluation settings. Here, we introduce the Biological AI Scientist Benchmark (BaisBench), a benchmark designed to assess AI scientists' ability to generate biological discoveries through data analysis and reasoning with external knowledge. BaisBench comprises two tasks: cell type annotation on 31 expert-labeled single-cell datasets, and scientific discovery through answering 198 multiple-choice questions derived from the biological insights of 41 recent single-cell studies. Systematic experiments on state-of-the-art AI scientists and LLM agents showed that while promising, current models still substantially underperform human experts on both tasks. We hope BaisBench will fill this gap and serve as a foundation for advancing and evaluating AI models for scientific discovery. The benchmark can be found at: https://github.com/EperLuo/BaisBench.
The Computational Anatomy of Humility: Modeling Intellectual Humility in Online Public Discourse
Oct 19, 2024



The ability for individuals to constructively engage with one another across lines of difference is a critical feature of a healthy pluralistic society. This is also true in online discussion spaces like social media platforms. To date, much social media research has focused on preventing ills -- like political polarization and the spread of misinformation. While this is important, enhancing the quality of online public discourse requires not just reducing ills but also promoting foundational human virtues. In this study, we focus on one particular virtue: ``intellectual humility'' (IH), or acknowledging the potential limitations in one's own beliefs. Specifically, we explore the development of computational methods for measuring IH at scale. We manually curate and validate an IH codebook on 350 posts about religion drawn from subreddits and use them to develop LLM-based models for automating this measurement. Our best model achieves a Macro-F1 score of 0.64 across labels (and 0.70 when predicting IH/IA/Neutral at the coarse level), higher than an expected naive baseline of 0.51 (0.32 for IH/IA/Neutral) but lower than a human annotator-informed upper bound of 0.85 (0.83 for IH/IA/Neutral). Our results both highlight the challenging nature of detecting IH online -- opening the door to new directions in NLP research -- and also lay a foundation for computational social science researchers interested in analyzing and fostering more IH in online public discourse.
Enhanced Detection of Conversational Mental Manipulation Through Advanced Prompting Techniques
Aug 14, 2024

This study presents a comprehensive, long-term project to explore the effectiveness of various prompting techniques in detecting dialogical mental manipulation. We implement Chain-of-Thought prompting with Zero-Shot and Few-Shot settings on a binary mental manipulation detection task, building upon existing work conducted with Zero-Shot and Few- Shot prompting. Our primary objective is to decipher why certain prompting techniques display superior performance, so as to craft a novel framework tailored for detection of mental manipulation. Preliminary findings suggest that advanced prompting techniques may not be suitable for more complex models, if they are not trained through example-based learning.
Serial Position Effects of Large Language Models
Jun 23, 2024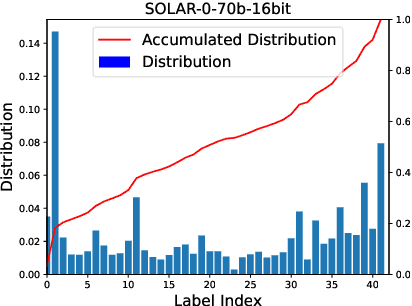
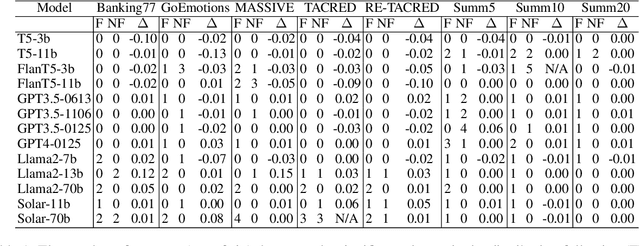

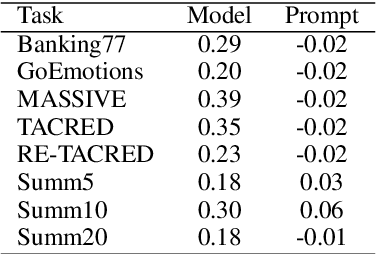
Large Language Models (LLMs) have shown remarkable capabilities in zero-shot learning applications, generating responses to queries using only pre-training information without the need for additional fine-tuning. This represents a significant departure from traditional machine learning approaches. Previous research has indicated that LLMs may exhibit serial position effects, such as primacy and recency biases, which are well-documented cognitive biases in human psychology. Our extensive testing across various tasks and models confirms the widespread occurrence of these effects, although their intensity varies. We also discovered that while carefully designed prompts can somewhat mitigate these biases, their effectiveness is inconsistent. These findings underscore the significance of serial position effects during the inference process, particularly in scenarios where there are no ground truth labels, highlighting the need for greater focus on addressing these effects in LLM applications.
MODABS: Multi-Objective Learning for Dynamic Aspect-Based Summarization
Jun 05, 2024
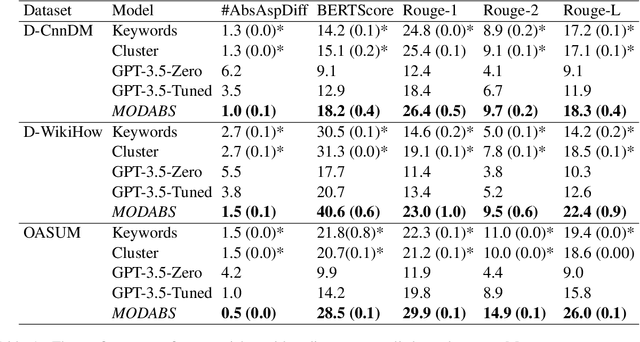
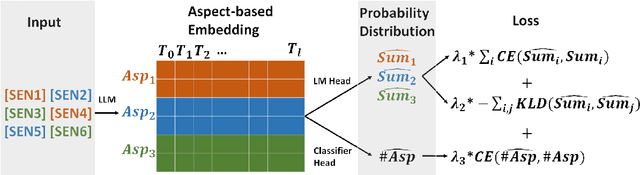
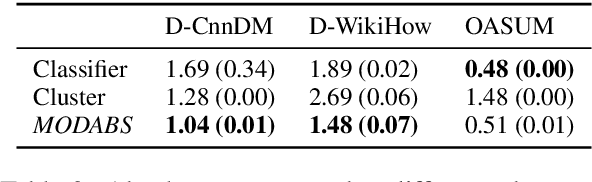
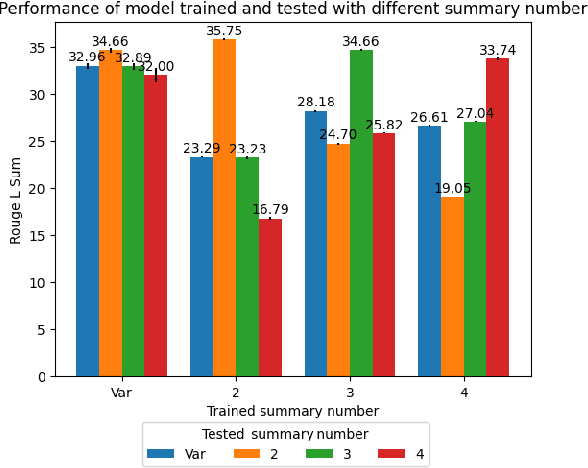
The rapid proliferation of online content necessitates effective summarization methods, among which dynamic aspect-based summarization stands out. Unlike its traditional counterpart, which assumes a fixed set of known aspects, this approach adapts to the varied aspects of the input text. We introduce a novel multi-objective learning framework employing a Longformer-Encoder-Decoder for this task. The framework optimizes aspect number prediction, minimizes disparity between generated and reference summaries for each aspect, and maximizes dissimilarity across aspect-specific summaries. Extensive experiments show our method significantly outperforms baselines on three diverse datasets, largely due to the effective alignment of generated and reference aspect counts without sacrificing single-aspect summarization quality.
LOLAMEME: Logic, Language, Memory, Mechanistic Framework
May 31, 2024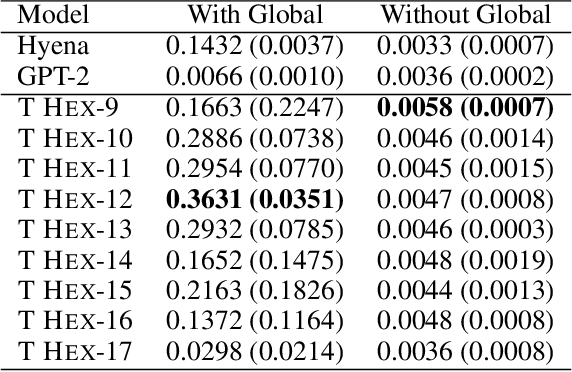
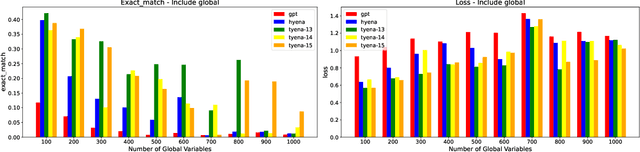
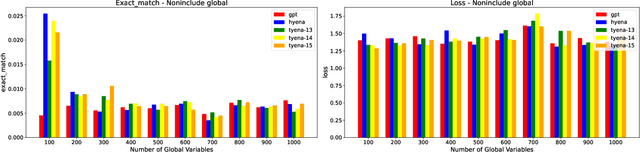

The performance of Large Language Models has achieved superhuman breadth with unprecedented depth. At the same time, the language models are mostly black box models and the underlying mechanisms for performance have been evaluated using synthetic or mechanistic schemes. We extend current mechanistic schemes to incorporate Logic, memory, and nuances of Language such as latent structure. The proposed framework is called LOLAMEME and we provide two instantiations of LOLAMEME: LoLa and MeMe languages. We then consider two generative language model architectures: transformer-based GPT-2 and convolution-based Hyena. We propose the hybrid architecture T HEX and use LOLAMEME framework is used to compare three architectures. T HEX outperforms GPT-2 and Hyena on select tasks.
JADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization
May 28, 2024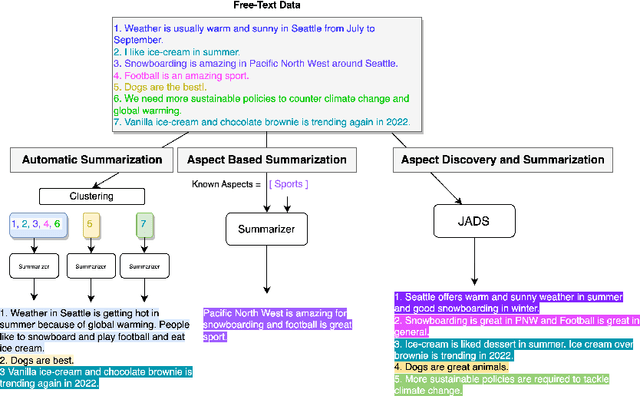
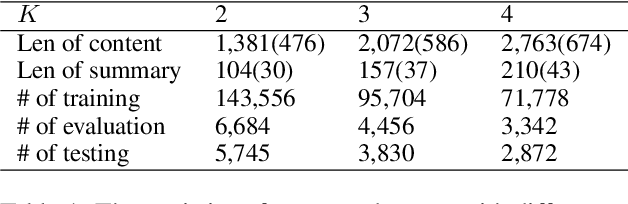
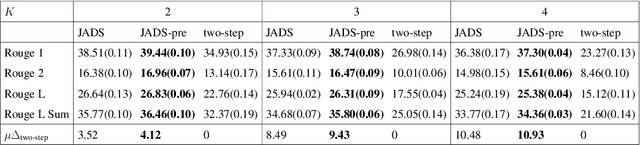
To generate summaries that include multiple aspects or topics for text documents, most approaches use clustering or topic modeling to group relevant sentences and then generate a summary for each group. These approaches struggle to optimize the summarization and clustering algorithms jointly. On the other hand, aspect-based summarization requires known aspects. Our solution integrates topic discovery and summarization into a single step. Given text data, our Joint Aspect Discovery and Summarization algorithm (JADS) discovers aspects from the input and generates a summary of the topics, in one step. We propose a self-supervised framework that creates a labeled dataset by first mixing sentences from multiple documents (e.g., CNN/DailyMail articles) as the input and then uses the article summaries from the mixture as the labels. The JADS model outperforms the two-step baselines. With pretraining, the model achieves better performance and stability. Furthermore, embeddings derived from JADS exhibit superior clustering capabilities. Our proposed method achieves higher semantic alignment with ground truth and is factual.
Disordered-DABS: A Benchmark for Dynamic Aspect-Based Summarization in Disordered Texts
Feb 16, 2024


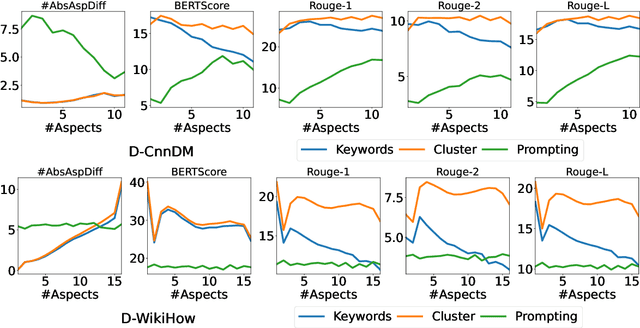
Aspect-based summarization has seen significant advancements, especially in structured text. Yet, summarizing disordered, large-scale texts, like those found in social media and customer feedback, remains a significant challenge. Current research largely targets predefined aspects within structured texts, neglecting the complexities of dynamic and disordered environments. Addressing this gap, we introduce Disordered-DABS, a novel benchmark for dynamic aspect-based summarization tailored to unstructured text. Developed by adapting existing datasets for cost-efficiency and scalability, our comprehensive experiments and detailed human evaluations reveal that Disordered-DABS poses unique challenges to contemporary summarization models, including state-of-the-art language models such as GPT-3.5.