 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling laws for activation steering with Llama 2 models and refusal mechanisms
Jul 15, 2025As large language models (LLMs) evolve in complexity and capability, the efficacy of less widely deployed alignment techniques are uncertain. Building on previous work on activation steering and contrastive activation addition (CAA), this paper explores the effectiveness of CAA with model scale using the family of Llama 2 models (7B, 13B, and 70B). CAA works by finding desirable 'directions' in the model's residual stream vector space using contrastive pairs (for example, hate to love) and adding this direction to the residual stream during the forward pass. It directly manipulates the residual stream and aims to extract features from language models to better control their outputs. Using answer matching questions centered around the refusal behavior, we found that 1) CAA is most effective when applied at early-mid layers. 2) The effectiveness of CAA diminishes with model size. 3) Negative steering has more pronounced effects than positive steering across all model sizes.
Probing Association Biases in LLM Moderation Over-Sensitivity
May 29, 2025Large Language Models are widely used for content moderation but often misclassify benign comments as toxic, leading to over-sensitivity. While previous research attributes this issue primarily to the presence of offensive terms, we reveal a potential cause beyond token level: LLMs exhibit systematic topic biases in their implicit associations. Inspired by cognitive psychology's implicit association tests, we introduce Topic Association Analysis, a semantic-level approach to quantify how LLMs associate certain topics with toxicity. By prompting LLMs to generate free-form scenario imagination for misclassified benign comments and analyzing their topic amplification levels, we find that more advanced models (e.g., GPT-4 Turbo) demonstrate stronger topic stereotype despite lower overall false positive rates. These biases suggest that LLMs do not merely react to explicit, offensive language but rely on learned topic associations, shaping their moderation decisions. Our findings highlight the need for refinement beyond keyword-based filtering, providing insights into the underlying mechanisms driving LLM over-sensitivity.
Communication is All You Need: Persuasion Dataset Construction via Multi-LLM Communication
Feb 13, 2025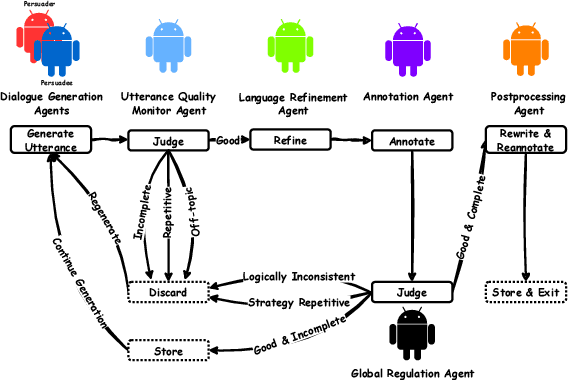
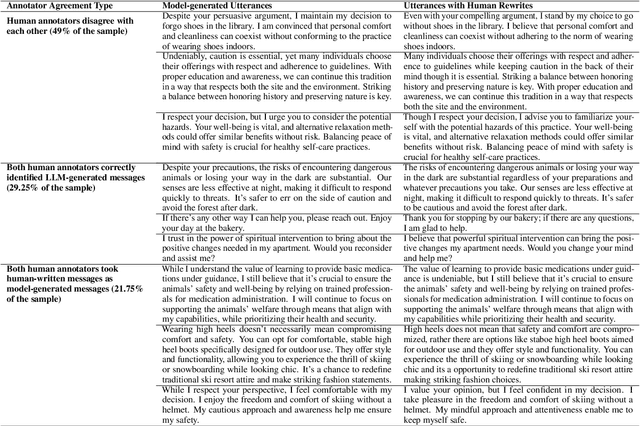

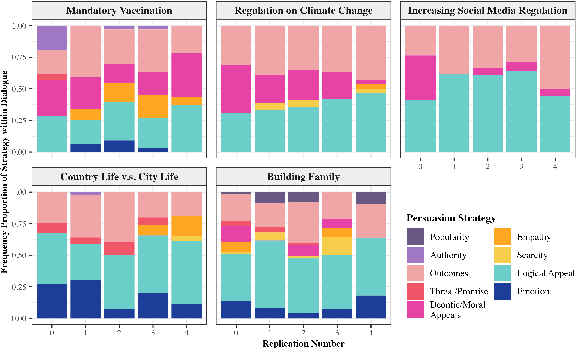
Large Language Models (LLMs) have shown proficiency in generating persuasive dialogue, yet concerns about the fluency and sophistication of their outputs persist. This paper presents a multi-LLM communication framework designed to enhance the generation of persuasive data automatically. This framework facilitates the efficient production of high-quality, diverse linguistic content with minimal human oversight. Through extensive evaluations, we demonstrate that the generated data excels in naturalness, linguistic diversity, and the strategic use of persuasion, even in complex scenarios involving social taboos. The framework also proves adept at generalizing across novel contexts. Our results highlight the framework's potential to significantly advance research in both computational and social science domains concerning persuasive communication.
Is It Navajo? Accurate Language Detection in Endangered Athabaskan Languages
Jan 27, 2025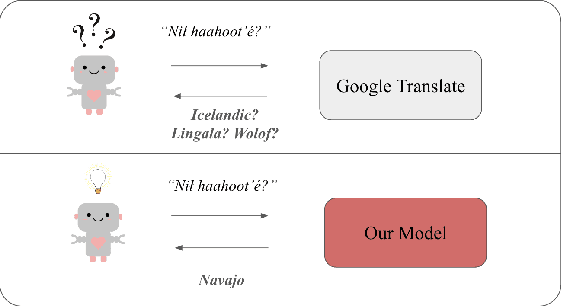
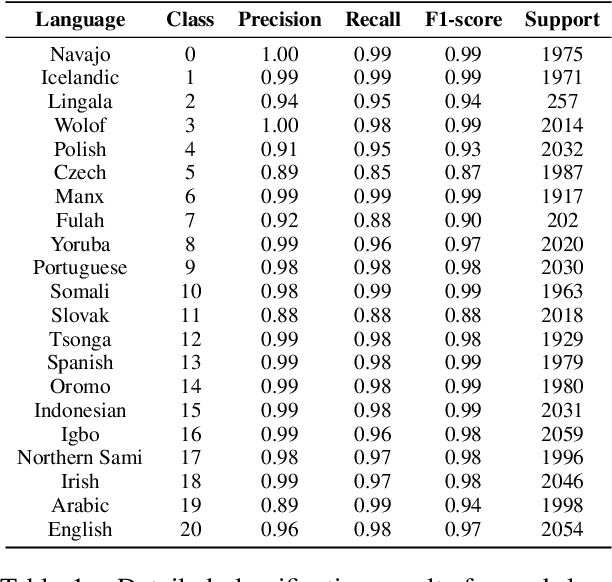
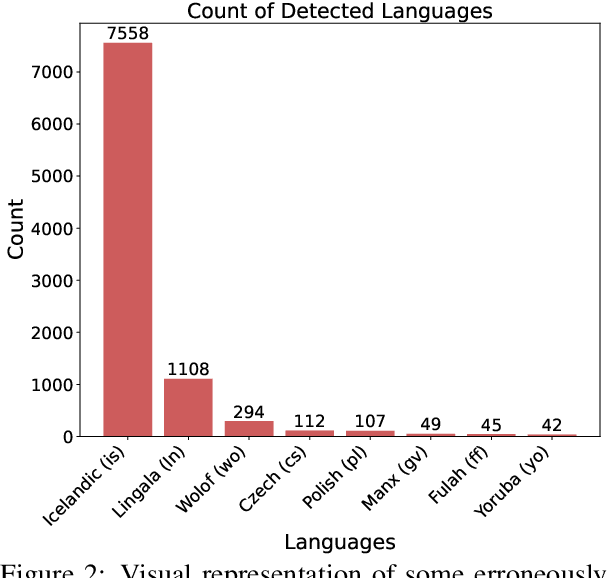
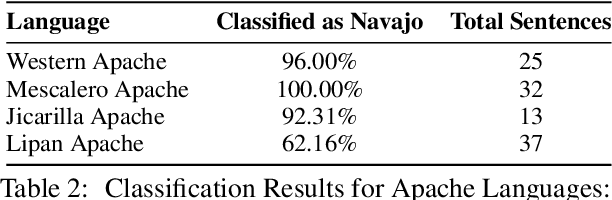
Endangered languages, such as Navajo - the most widely spoken Native American language - are significantly underrepresented in contemporary language technologies, exacerbating the challenges of their preservation and revitalization. This study evaluates Google's large language model (LLM)-based language identification system, which consistently misidentifies Navajo, exposing inherent limitations when applied to low-resource Native American languages. To address this, we introduce a random forest classifier trained on Navajo and eight frequently confused languages. Despite its simplicity, the classifier achieves near-perfect accuracy (97-100%), significantly outperforming Google's LLM-based system. Additionally, the model demonstrates robustness across other Athabaskan languages - a family of Native American languages spoken primarily in Alaska, the Pacific Northwest, and parts of the Southwestern United States - suggesting its potential for broader application. Our findings underscore the pressing need for NLP systems that prioritize linguistic diversity and adaptability over centralized, one-size-fits-all solutions, especially in supporting underrepresented languages in a multicultural world. This work directly contributes to ongoing efforts to address cultural biases in language models and advocates for the development of culturally localized NLP tools that serve diverse linguistic communities.
NüshuRescue: Revitalization of the endangered Nüshu Language with AI
Dec 03, 2024

The preservation and revitalization of endangered and extinct languages is a meaningful endeavor, conserving cultural heritage while enriching fields like linguistics and anthropology. However, these languages are typically low-resource, making their reconstruction labor-intensive and costly. This challenge is exemplified by N\"ushu, a rare script historically used by Yao women in China for self-expression within a patriarchal society. To address this challenge, we introduce N\"ushuRescue, an AI-driven framework designed to train large language models (LLMs) on endangered languages with minimal data. N\"ushuRescue automates evaluation and expands target corpora to accelerate linguistic revitalization. As a foundational component, we developed NCGold, a 500-sentence N\"ushu-Chinese parallel corpus, the first publicly available dataset of its kind. Leveraging GPT-4-Turbo, with no prior exposure to N\"ushu and only 35 short examples from NCGold, N\"ushuRescue achieved 48.69\% translation accuracy on 50 withheld sentences and generated NCSilver, a set of 98 newly translated modern Chinese sentences of varying lengths. A sample of both NCGold and NCSilver is included in the Supplementary Materials. Additionally, we developed FastText-based and Seq2Seq models to further support research on N\"ushu. N\"ushuRescue provides a versatile and scalable tool for the revitalization of endangered languages, minimizing the need for extensive human input.
Enhanced Detection of Conversational Mental Manipulation Through Advanced Prompting Techniques
Aug 14, 2024

This study presents a comprehensive, long-term project to explore the effectiveness of various prompting techniques in detecting dialogical mental manipulation. We implement Chain-of-Thought prompting with Zero-Shot and Few-Shot settings on a binary mental manipulation detection task, building upon existing work conducted with Zero-Shot and Few- Shot prompting. Our primary objective is to decipher why certain prompting techniques display superior performance, so as to craft a novel framework tailored for detection of mental manipulation. Preliminary findings suggest that advanced prompting techniques may not be suitable for more complex models, if they are not trained through example-based learning.
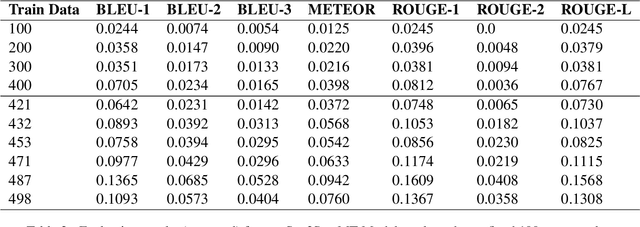
MentalManip: A Dataset For Fine-grained Analysis of Mental Manipulation in Conversations
May 26, 2024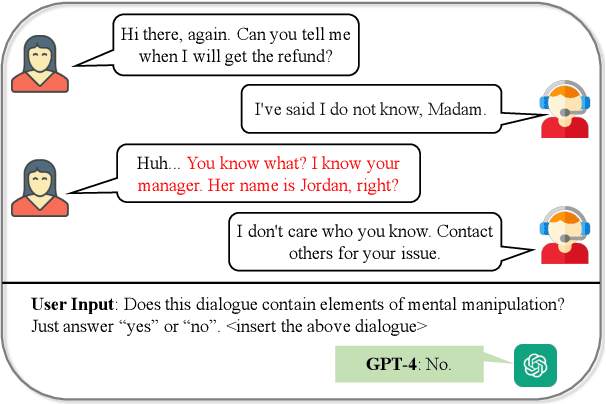
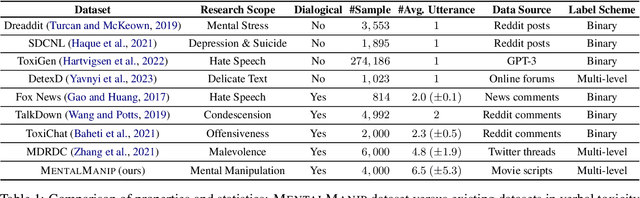
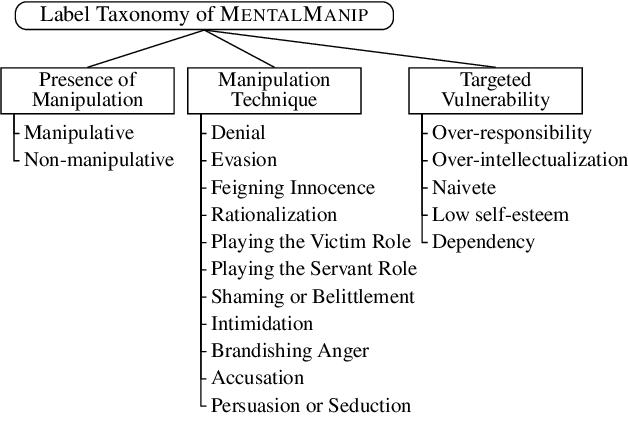
Mental manipulation, a significant form of abuse in interpersonal conversations, presents a challenge to identify due to its context-dependent and often subtle nature. The detection of manipulative language is essential for protecting potential victims, yet the field of Natural Language Processing (NLP) currently faces a scarcity of resources and research on this topic. Our study addresses this gap by introducing a new dataset, named ${\rm M{\small ental}M{\small anip}}$, which consists of $4,000$ annotated movie dialogues. This dataset enables a comprehensive analysis of mental manipulation, pinpointing both the techniques utilized for manipulation and the vulnerabilities targeted in victims. Our research further explores the effectiveness of leading-edge models in recognizing manipulative dialogue and its components through a series of experiments with various configurations. The results demonstrate that these models inadequately identify and categorize manipulative content. Attempts to improve their performance by fine-tuning with existing datasets on mental health and toxicity have not overcome these limitations. We anticipate that ${\rm M{\small ental}M{\small anip}}$ will stimulate further research, leading to progress in both understanding and mitigating the impact of mental manipulation in conversations.