 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoKV: Efficient KV Cache Compression via Similarity-Based Reconstruction
Mar 24, 2026The increasing memory demand of the Key-Value (KV) cache poses a significant bottleneck for Large Language Models (LLMs) in long-context applications. Existing low-rank compression methods often rely on irreversible parameter transformations, sacrificing the flexibility to switch back to full-precision inference when memory is abundant. In this paper, we propose EchoKV, a flexible KV cache compression scheme that enables on-demand transitions between standard and compressed inference. Unlike traditional compression-decompression paradigms, EchoKV utilizes a lightweight network to reconstruct the residual KV components from a partial subset, leveraging intrinsic inter-layer and intra-layer similarities among attention heads. We further introduce a two-stage fine-tuning strategy that allows for rapid, low-cost training (e.g., ~1 A100 GPU-hour for a 7B model). Experimental results on LongBench and RULER demonstrate that EchoKV consistently outperforms existing methods across various compression ratios while maintaining high throughput for short-context scenarios.
Seer Self-Consistency: Advance Budget Estimation for Adaptive Test-Time Scaling
Nov 12, 2025Test-time scaling improves the inference performance of Large Language Models (LLMs) but also incurs substantial computational costs. Although recent studies have reduced token consumption through dynamic self-consistency, they remain constrained by the high latency of sequential requests. In this paper, we propose SeerSC, a dynamic self-consistency framework that simultaneously improves token efficiency and latency by integrating System 1 and System 2 reasoning. Specifically, we utilize the rapid System 1 to compute the answer entropy for given queries. This score is then used to evaluate the potential of samples for scaling, enabling dynamic self-consistency under System 2. Benefiting from the advance and accurate estimation provided by System 1, the proposed method can reduce token usage while simultaneously achieving a significant decrease in latency through parallel generation. It outperforms existing methods, achieving up to a 47% reduction in token consumption and a 43% reduction in inference latency without significant performance loss.
Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query
May 24, 2025Large language models (LLMs) rely on key-value cache (KV cache) to accelerate decoding by reducing redundant computations. However, the KV cache memory usage grows substantially with longer text sequences, posing challenges for efficient deployment. Existing KV cache eviction methods prune tokens using prefilling-stage attention scores, causing inconsistency with actual inference queries, especially under tight memory budgets. In this paper, we propose Lookahead Q-Cache (LAQ), a novel eviction framework that generates low-cost pseudo lookahead queries to better approximate the true decoding-stage queries. By using these lookahead queries as the observation window for importance estimation, LAQ achieves more consistent and accurate KV cache eviction aligned with real inference scenarios. Experimental results on LongBench and Needle-in-a-Haystack benchmarks show that LAQ outperforms existing methods across various budget levels, achieving a 1 $\sim$ 4 point improvement on LongBench under limited cache budget. Moreover, LAQ is complementary to existing approaches and can be flexibly combined to yield further improvements.
Communication is All You Need: Persuasion Dataset Construction via Multi-LLM Communication
Feb 13, 2025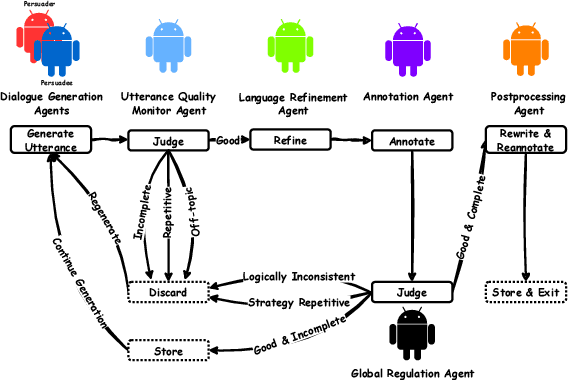
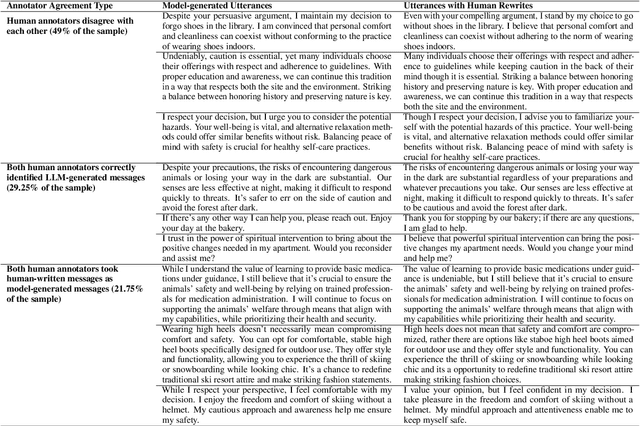

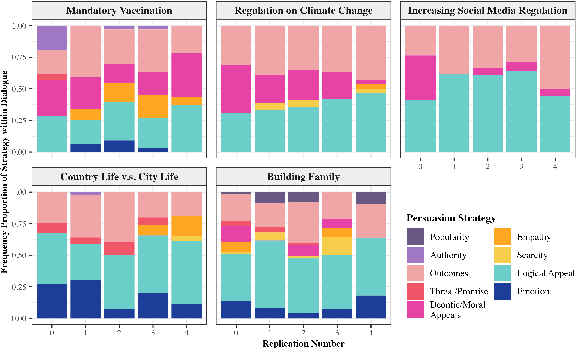
Large Language Models (LLMs) have shown proficiency in generating persuasive dialogue, yet concerns about the fluency and sophistication of their outputs persist. This paper presents a multi-LLM communication framework designed to enhance the generation of persuasive data automatically. This framework facilitates the efficient production of high-quality, diverse linguistic content with minimal human oversight. Through extensive evaluations, we demonstrate that the generated data excels in naturalness, linguistic diversity, and the strategic use of persuasion, even in complex scenarios involving social taboos. The framework also proves adept at generalizing across novel contexts. Our results highlight the framework's potential to significantly advance research in both computational and social science domains concerning persuasive communication.
CRVQ: Channel-relaxed Vector Quantization for Extreme Compression of LLMs
Dec 12, 2024



Powerful large language models (LLMs) are increasingly expected to be deployed with lower computational costs, enabling their capabilities on resource-constrained devices. Post-training quantization (PTQ) has emerged as a star approach to achieve this ambition, with best methods compressing weights to less than 2 bit on average. In this paper, we propose Channel-Relaxed Vector Quantization (CRVQ), a novel technique that significantly improves the performance of PTQ baselines at the cost of only minimal additional bits. This state-of-the-art extreme compression method achieves its results through two key innovations: (1) carefully selecting and reordering a very small subset of critical weight channels, and (2) leveraging multiple codebooks to relax the constraint of critical channels. With our method, we demonstrate a 38.9% improvement over the current strongest sub-2-bit PTQ baseline, enabling nearer lossless 1-bit compression. Furthermore, our approach offers flexible customization of quantization bit-width and performance, providing a wider range of deployment options for diverse hardware platforms.
New Insights on Relieving Task-Recency Bias for Online Class Incremental Learning
Feb 16, 2023To imitate the ability of keeping learning of human, continual learning which can learn from a never-ending data stream has attracted more interests recently. In all settings, the online class incremental learning (CIL), where incoming samples from data stream can be used only once, is more challenging and can be encountered more frequently in real world. Actually, the CIL faces a stability-plasticity dilemma, where the stability means the ability to preserve old knowledge while the plasticity denotes the ability to incorporate new knowledge. Although replay-based methods have shown exceptional promise, most of them concentrate on the strategy for updating and retrieving memory to keep stability at the expense of plasticity. To strike a preferable trade-off between stability and plasticity, we propose a Adaptive Focus Shifting algorithm (AFS), which dynamically adjusts focus to ambiguous samples and non-target logits in model learning. Through a deep analysis of the task-recency bias caused by class imbalance, we propose a revised focal loss to mainly keep stability. By utilizing a new weight function, the revised focal loss can pay more attention to current ambiguous samples, which can provide more information of the classification boundary. To promote plasticity, we introduce a virtual knowledge distillation. By designing a virtual teacher, it assigns more attention to non-target classes, which can surmount overconfidence and encourage model to focus on inter-class information. Extensive experiments on three popular datasets for CIL have shown the effectiveness of AFS. The code will be available at \url{https://github.com/czjghost/AFS}.