 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Insights on Relieving Task-Recency Bias for Online Class Incremental Learning
Feb 16, 2023To imitate the ability of keeping learning of human, continual learning which can learn from a never-ending data stream has attracted more interests recently. In all settings, the online class incremental learning (CIL), where incoming samples from data stream can be used only once, is more challenging and can be encountered more frequently in real world. Actually, the CIL faces a stability-plasticity dilemma, where the stability means the ability to preserve old knowledge while the plasticity denotes the ability to incorporate new knowledge. Although replay-based methods have shown exceptional promise, most of them concentrate on the strategy for updating and retrieving memory to keep stability at the expense of plasticity. To strike a preferable trade-off between stability and plasticity, we propose a Adaptive Focus Shifting algorithm (AFS), which dynamically adjusts focus to ambiguous samples and non-target logits in model learning. Through a deep analysis of the task-recency bias caused by class imbalance, we propose a revised focal loss to mainly keep stability. By utilizing a new weight function, the revised focal loss can pay more attention to current ambiguous samples, which can provide more information of the classification boundary. To promote plasticity, we introduce a virtual knowledge distillation. By designing a virtual teacher, it assigns more attention to non-target classes, which can surmount overconfidence and encourage model to focus on inter-class information. Extensive experiments on three popular datasets for CIL have shown the effectiveness of AFS. The code will be available at \url{https://github.com/czjghost/AFS}.
Active Deep Learning on Entity Resolution by Risk Sampling
Dec 23, 2020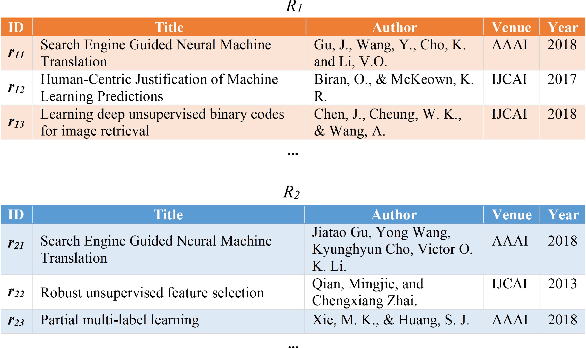

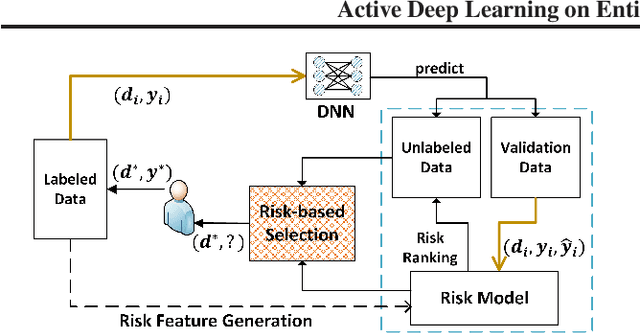
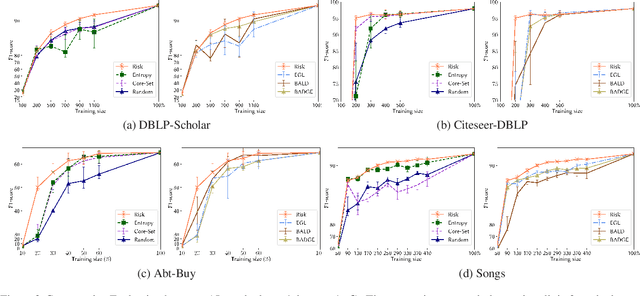
While the state-of-the-art performance on entity resolution (ER) has been achieved by deep learning, its effectiveness depends on large quantities of accurately labeled training data. To alleviate the data labeling burden, Active Learning (AL) presents itself as a feasible solution that focuses on data deemed useful for model training. Building upon the recent advances in risk analysis for ER, which can provide a more refined estimate on label misprediction risk than the simpler classifier outputs, we propose a novel AL approach of risk sampling for ER. Risk sampling leverages misprediction risk estimation for active instance selection. Based on the core-set characterization for AL, we theoretically derive an optimization model which aims to minimize core-set loss with non-uniform Lipschitz continuity. Since the defined weighted K-medoids problem is NP-hard, we then present an efficient heuristic algorithm. Finally, we empirically verify the efficacy of the proposed approach on real data by a comparative study. Our extensive experiments have shown that it outperforms the existing alternatives by considerable margins. Using ER as a test case, we demonstrate that risk sampling is a promising approach potentially applicable to other challenging classification tasks.
Risk-based Adaptive Deep Learning for Entity Resolution
Dec 10, 2020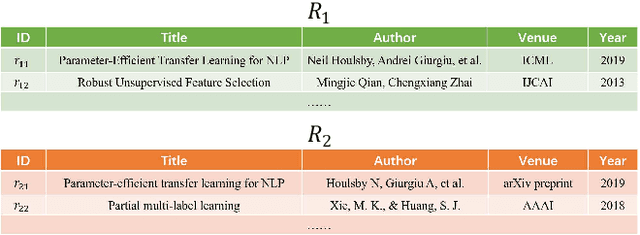

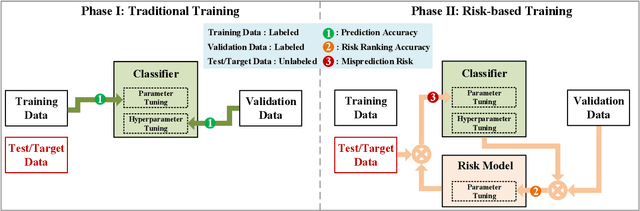
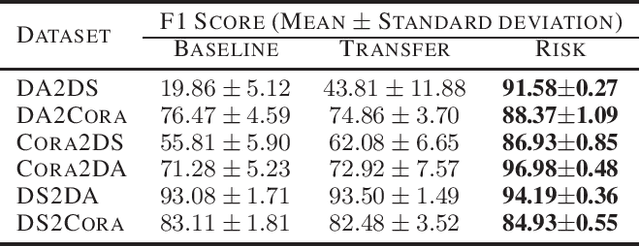
The state-of-the-art performance on entity resolution (ER) has been achieved by deep learning. However, deep models are usually trained on large quantities of accurately labeled training data, and can not be easily tuned towards a target workload. Unfortunately, in real scenarios, there may not be sufficient labeled training data, and even worse, their distribution is usually more or less different from the target workload even when they come from the same domain. To alleviate the said limitations, this paper proposes a novel risk-based approach to tune a deep model towards a target workload by its particular characteristics. Built on the recent advances on risk analysis for ER, the proposed approach first trains a deep model on labeled training data, and then fine-tunes it by minimizing its estimated misprediction risk on unlabeled target data. Our theoretical analysis shows that risk-based adaptive training can correct the label status of a mispredicted instance with a fairly good chance. We have also empirically validated the efficacy of the proposed approach on real benchmark data by a comparative study. Our extensive experiments show that it can considerably improve the performance of deep models. Furthermore, in the scenario of distribution misalignment, it can similarly outperform the state-of-the-art alternative of transfer learning by considerable margins. Using ER as a test case, we demonstrate that risk-based adaptive training is a promising approach potentially applicable to various challenging classification tasks.
Towards Interpretable and Learnable Risk Analysis for Entity Resolution
Dec 06, 2019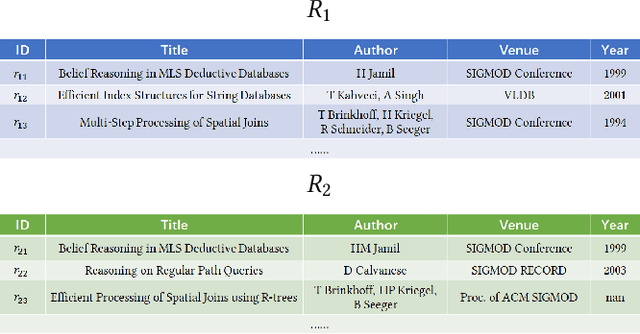
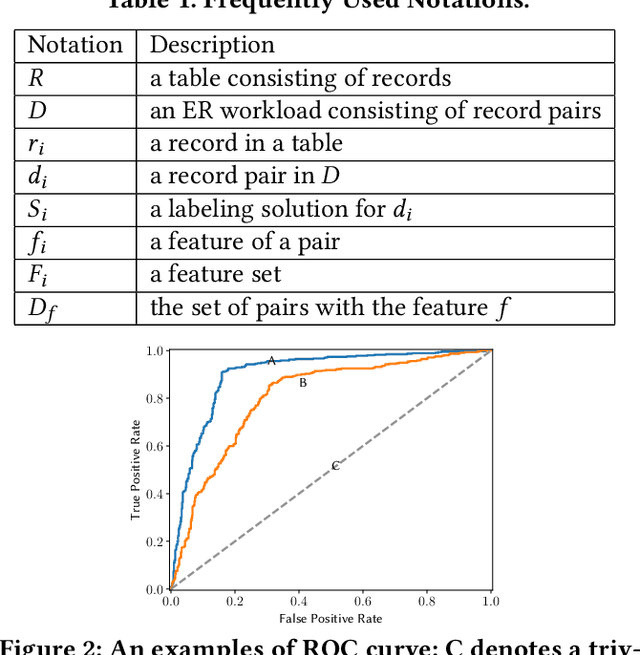
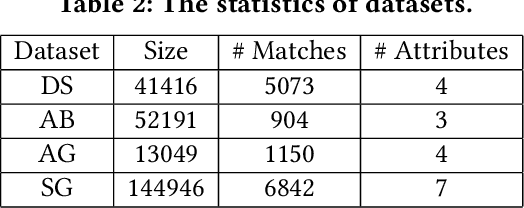
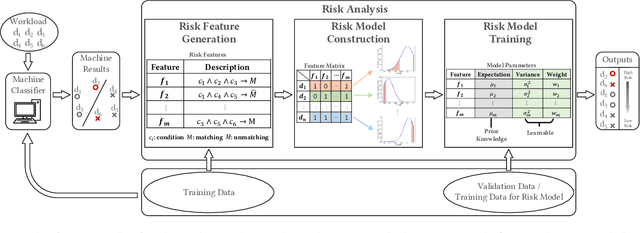
Machine-learning-based entity resolution has been widely studied. However, some entity pairs may be mislabeled by machine learning models and existing studies do not study the risk analysis problem -- predicting and interpreting which entity pairs are mislabeled. In this paper, we propose an interpretable and learnable framework for risk analysis, which aims to rank the labeled pairs based on their risks of being mislabeled. We first describe how to automatically generate interpretable risk features, and then present a learnable risk model and its training technique. Finally, we empirically evaluate the performance of the proposed approach on real data. Our extensive experiments have shown that the learning risk model can identify the mislabeled pairs with considerably higher accuracy than the existing alternatives.
Gradual Machine Learning for Entity Resolution
Oct 29, 2018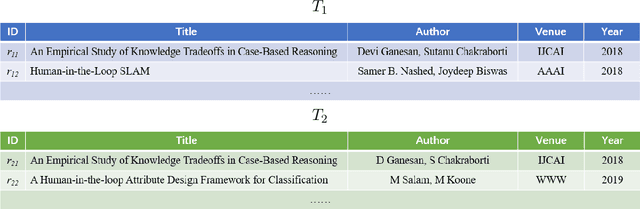

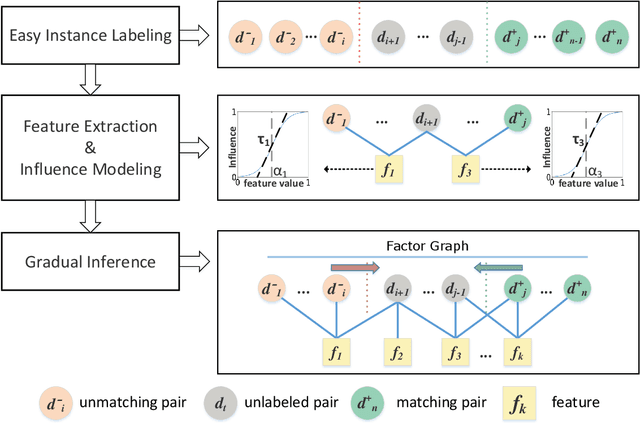
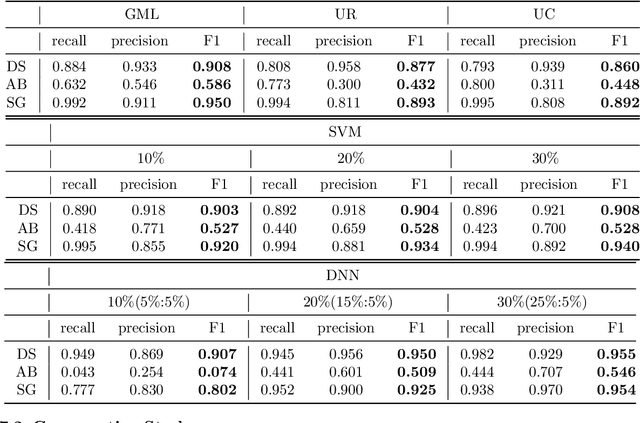
Usually considered as a classification problem, entity resolution can be very challenging on real data due to the prevalence of dirty values. The state-of-the-art solutions for ER were built on a variety of learning models (most notably deep neural networks), which require lots of accurately labeled training data. Unfortunately, high-quality labeled data usually require expensive manual work, and are therefore not readily available in many real scenarios. In this paper, we propose a novel learning paradigm for ER, called gradual machine learning, which aims to enable effective machine learning without the requirement for manual labeling effort. It begins with some easy instances in a task, which can be automatically labeled by the machine with high accuracy, and then gradually labels more challenging instances based on iterative factor graph inference. In gradual machine learning, the hard instances in a task are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on real data have shown that the proposed approach performs considerably better than its unsupervised alternatives, and it is highly competitive with the state-of-the-art supervised techniques. Using ER as a test case, we demonstrate that gradual machine learning is a promising paradigm potentially applicable to other challenging classification tasks requiring extensive labeling effort.