 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Deep Learning for Multiclass Breast Cancer Classification via Misprediction Risk Analysis
Mar 17, 2025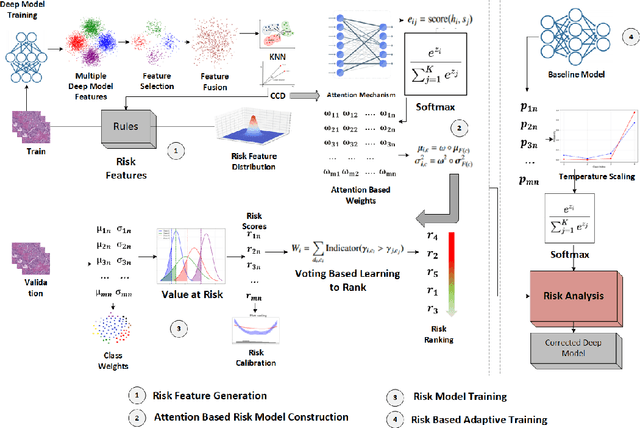

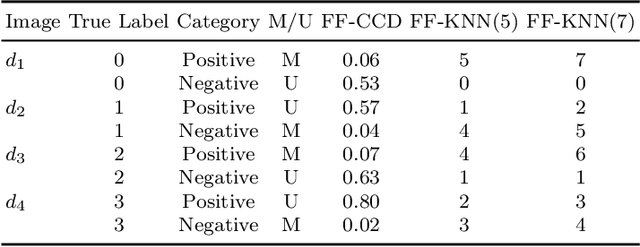
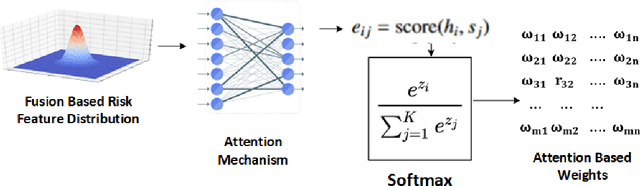
Breast cancer remains one of the leading causes of cancer-related deaths worldwide. Early detection is crucial for improving patient outcomes, yet the diagnostic process is often complex and prone to inconsistencies among pathologists. Computer-aided diagnostic approaches have significantly enhanced breast cancer detection, particularly in binary classification (benign vs. malignant). However, these methods face challenges in multiclass classification, leading to frequent mispredictions. In this work, we propose a novel adaptive learning approach for multiclass breast cancer classification using H&E-stained histopathology images. First, we introduce a misprediction risk analysis framework that quantifies and ranks the likelihood of an image being mislabeled by a classifier. This framework leverages an interpretable risk model that requires only a small number of labeled samples for training. Next, we present an adaptive learning strategy that fine-tunes classifiers based on the specific characteristics of a given dataset. This approach minimizes misprediction risk, allowing the classifier to adapt effectively to the target workload. We evaluate our proposed solutions on real benchmark datasets, demonstrating that our risk analysis framework more accurately identifies mispredictions compared to existing methods. Furthermore, our adaptive learning approach significantly improves the performance of state-of-the-art deep neural network classifiers.
Deep Clustering via Community Detection
Jan 03, 2025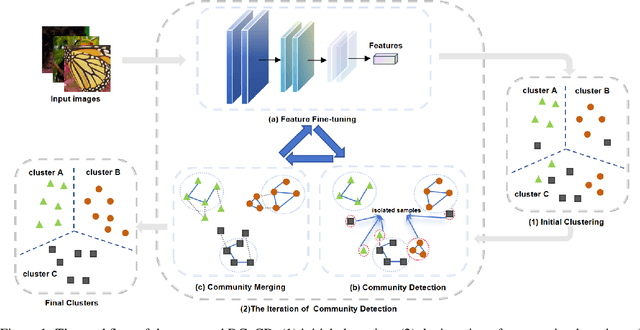
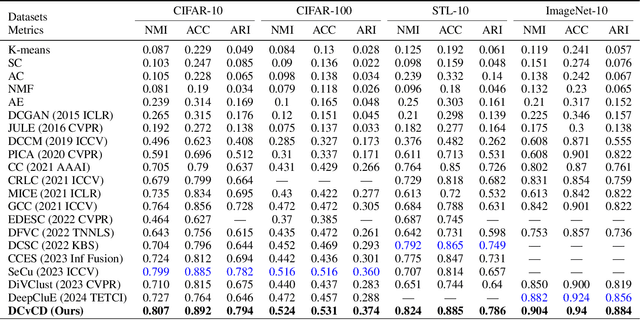
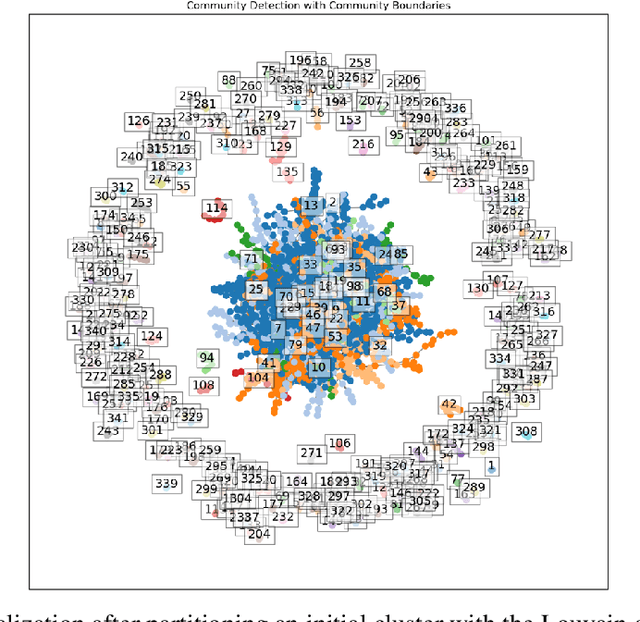

Deep clustering is an essential task in modern artificial intelligence, aiming to partition a set of data samples into a given number of homogeneous groups (i.e., clusters). Even though many Deep Neural Network (DNN) backbones and clustering strategies have been proposed for the task, achieving increasingly improved performance, deep clustering remains very challenging due to the lack of accurately labeled samples. In this paper, we propose a novel approach of deep clustering via community detection. It initializes clustering by detecting many communities, and then gradually expands clusters by community merging. Compared with the existing clustering strategies, community detection factors in the new perspective of cluster network analysis. As a result, it has the inherent benefit of high pseudo-label purity, which is critical to the performance of self-supervision. We have validated the efficacy of the proposed approach on benchmark image datasets. Our extensive experiments have shown that it can effectively improve the SOTA performance. Our ablation study also demonstrates that the new network perspective can effectively improve community pseudo-label purity, resulting in improved clustering performance.
Structure-Guided MR-to-CT Synthesis with Spatial and Semantic Alignments for Attenuation Correction of Whole-Body PET/MR Imaging
Nov 26, 2024Deep-learning-based MR-to-CT synthesis can estimate the electron density of tissues, thereby facilitating PET attenuation correction in whole-body PET/MR imaging. However, whole-body MR-to-CT synthesis faces several challenges including the issue of spatial misalignment and the complexity of intensity mapping, primarily due to the variety of tissues and organs throughout the whole body. Here we propose a novel whole-body MR-to-CT synthesis framework, which consists of three novel modules to tackle these challenges: (1) Structure-Guided Synthesis module leverages structure-guided attention gates to enhance synthetic image quality by diminishing unnecessary contours of soft tissues; (2) Spatial Alignment module yields precise registration between paired MR and CT images by taking into account the impacts of tissue volumes and respiratory movements, thus providing well-aligned ground-truth CT images during training; (3) Semantic Alignment module utilizes contrastive learning to constrain organ-related semantic information, thereby ensuring the semantic authenticity of synthetic CT images.We conduct extensive experiments to demonstrate that the proposed whole-body MR-to-CT framework can produce visually plausible and semantically realistic CT images, and validate its utility in PET attenuation correction.
Supervised Gradual Machine Learning for Aspect Category Detection
Apr 08, 2024Aspect Category Detection (ACD) aims to identify implicit and explicit aspects in a given review sentence. The state-of-the-art approaches for ACD use Deep Neural Networks (DNNs) to address the problem as a multi-label classification task. However, learning category-specific representations heavily rely on the amount of labeled examples, which may not readily available in real-world scenarios. In this paper, we propose a novel approach to tackle the ACD task by combining DNNs with Gradual Machine Learning (GML) in a supervised setting. we aim to leverage the strength of DNN in semantic relation modeling, which can facilitate effective knowledge transfer between labeled and unlabeled instances during the gradual inference of GML. To achieve this, we first analyze the learned latent space of the DNN to model the relations, i.e., similar or opposite, between instances. We then represent these relations as binary features in a factor graph to efficiently convey knowledge. Finally, we conduct a comparative study of our proposed solution on real benchmark datasets and demonstrate that the GML approach, in collaboration with DNNs for feature extraction, consistently outperforms pure DNN solutions.
Few-shot Image Classification based on Gradual Machine Learning
Jul 28, 2023
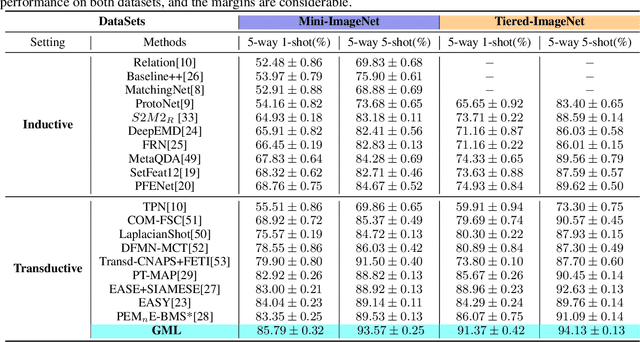
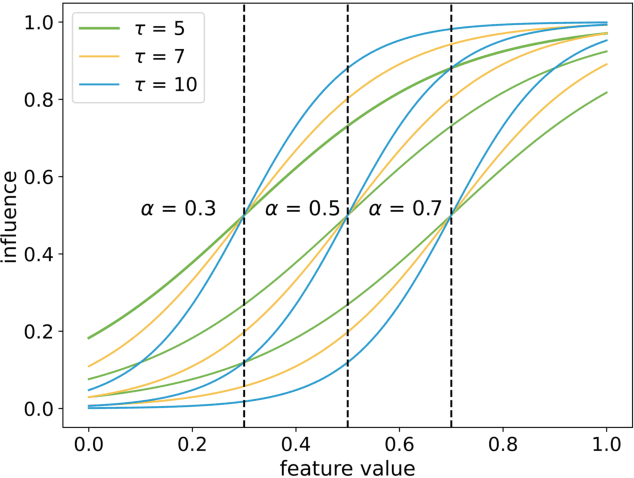
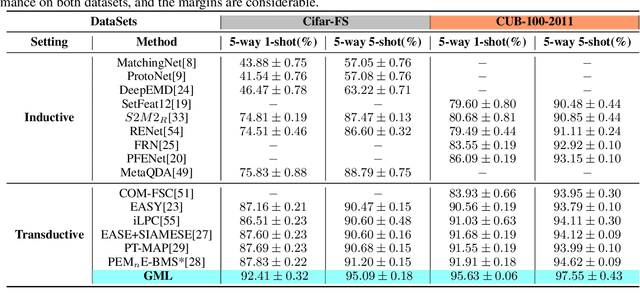
Few-shot image classification aims to accurately classify unlabeled images using only a few labeled samples. The state-of-the-art solutions are built by deep learning, which focuses on designing increasingly complex deep backbones. Unfortunately, the task remains very challenging due to the difficulty of transferring the knowledge learned in training classes to new ones. In this paper, we propose a novel approach based on the non-i.i.d paradigm of gradual machine learning (GML). It begins with only a few labeled observations, and then gradually labels target images in the increasing order of hardness by iterative factor inference in a factor graph. Specifically, our proposed solution extracts indicative feature representations by deep backbones, and then constructs both unary and binary factors based on the extracted features to facilitate gradual learning. The unary factors are constructed based on class center distance in an embedding space, while the binary factors are constructed based on k-nearest neighborhood. We have empirically validated the performance of the proposed approach on benchmark datasets by a comparative study. Our extensive experiments demonstrate that the proposed approach can improve the SOTA performance by 1-5% in terms of accuracy. More notably, it is more robust than the existing deep models in that its performance can consistently improve as the size of query set increases while the performance of deep models remains essentially flat or even becomes worse.
Active Deep Learning on Entity Resolution by Risk Sampling
Dec 23, 2020

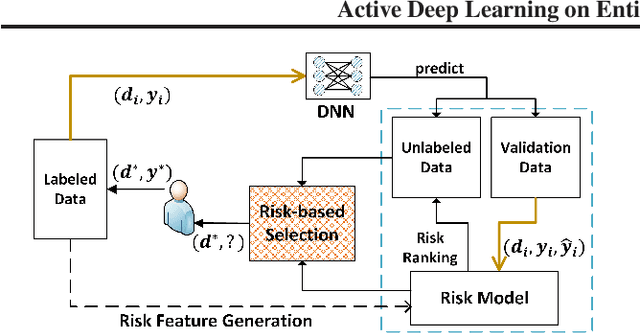
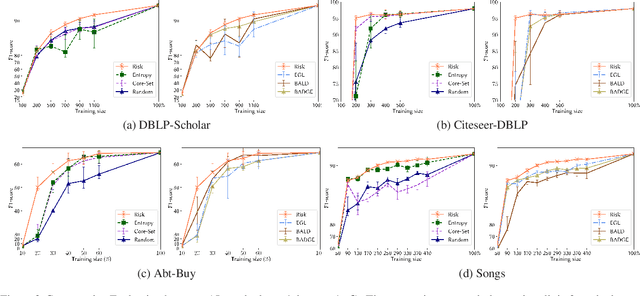
While the state-of-the-art performance on entity resolution (ER) has been achieved by deep learning, its effectiveness depends on large quantities of accurately labeled training data. To alleviate the data labeling burden, Active Learning (AL) presents itself as a feasible solution that focuses on data deemed useful for model training. Building upon the recent advances in risk analysis for ER, which can provide a more refined estimate on label misprediction risk than the simpler classifier outputs, we propose a novel AL approach of risk sampling for ER. Risk sampling leverages misprediction risk estimation for active instance selection. Based on the core-set characterization for AL, we theoretically derive an optimization model which aims to minimize core-set loss with non-uniform Lipschitz continuity. Since the defined weighted K-medoids problem is NP-hard, we then present an efficient heuristic algorithm. Finally, we empirically verify the efficacy of the proposed approach on real data by a comparative study. Our extensive experiments have shown that it outperforms the existing alternatives by considerable margins. Using ER as a test case, we demonstrate that risk sampling is a promising approach potentially applicable to other challenging classification tasks.
Risk-based Adaptive Deep Learning for Entity Resolution
Dec 10, 2020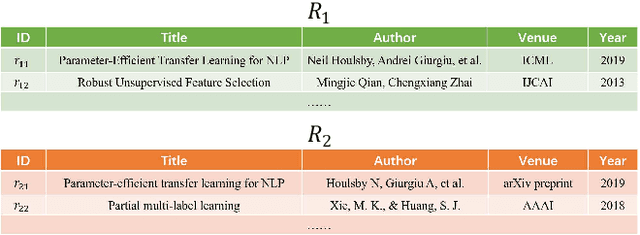

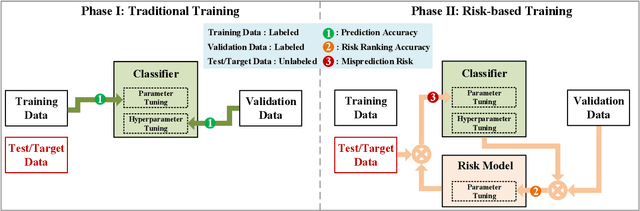
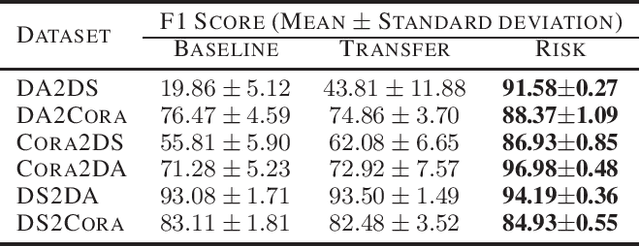
The state-of-the-art performance on entity resolution (ER) has been achieved by deep learning. However, deep models are usually trained on large quantities of accurately labeled training data, and can not be easily tuned towards a target workload. Unfortunately, in real scenarios, there may not be sufficient labeled training data, and even worse, their distribution is usually more or less different from the target workload even when they come from the same domain. To alleviate the said limitations, this paper proposes a novel risk-based approach to tune a deep model towards a target workload by its particular characteristics. Built on the recent advances on risk analysis for ER, the proposed approach first trains a deep model on labeled training data, and then fine-tunes it by minimizing its estimated misprediction risk on unlabeled target data. Our theoretical analysis shows that risk-based adaptive training can correct the label status of a mispredicted instance with a fairly good chance. We have also empirically validated the efficacy of the proposed approach on real benchmark data by a comparative study. Our extensive experiments show that it can considerably improve the performance of deep models. Furthermore, in the scenario of distribution misalignment, it can similarly outperform the state-of-the-art alternative of transfer learning by considerable margins. Using ER as a test case, we demonstrate that risk-based adaptive training is a promising approach potentially applicable to various challenging classification tasks.
Towards Interpretable and Learnable Risk Analysis for Entity Resolution
Dec 06, 2019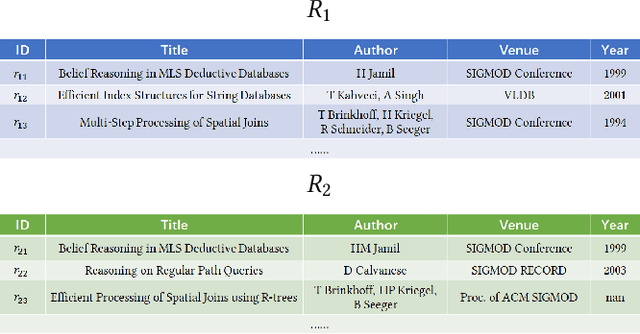
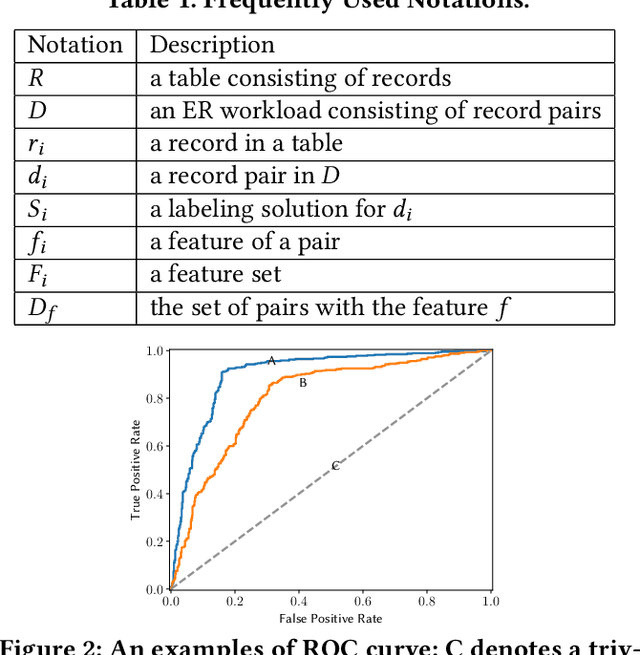
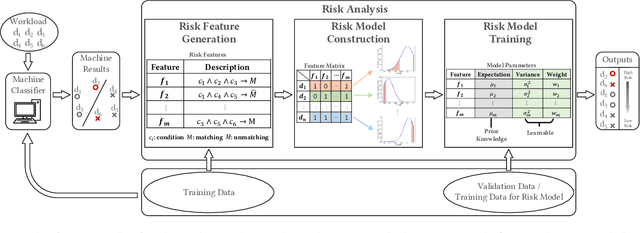
Machine-learning-based entity resolution has been widely studied. However, some entity pairs may be mislabeled by machine learning models and existing studies do not study the risk analysis problem -- predicting and interpreting which entity pairs are mislabeled. In this paper, we propose an interpretable and learnable framework for risk analysis, which aims to rank the labeled pairs based on their risks of being mislabeled. We first describe how to automatically generate interpretable risk features, and then present a learnable risk model and its training technique. Finally, we empirically evaluate the performance of the proposed approach on real data. Our extensive experiments have shown that the learning risk model can identify the mislabeled pairs with considerably higher accuracy than the existing alternatives.
Gradual Machine Learning for Aspect-level Sentiment Analysis
Jul 01, 2019
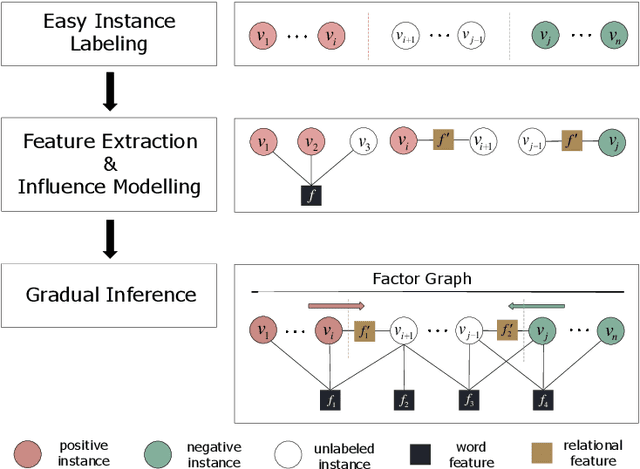

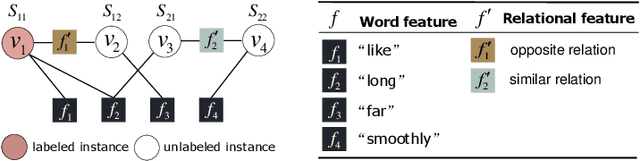
The state-of-the-art solutions for Aspect-Level Sentiment Analysis (ALSA) were built on a variety of deep neural networks (DNN), whose efficacy depends on large amounts of accurately labeled training data. Unfortunately, high-quality labeled training data usually require expensive manual work, and may thus not be readily available in real scenarios. In this paper, we propose a novel solution for ALSA based on the recently proposed paradigm of gradual machine learning, which can enable effective machine labeling without the requirement for manual labeling effort. It begins with some easy instances in an ALSA task, which can be automatically labeled by the machine with high accuracy, and then gradually labels the more challenging instances by iterative factor graph inference. In the process of gradual machine learning, the hard instances are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on the benchmark datasets have shown that the performance of the proposed solution is considerably better than its unsupervised alternatives, and also highly competitive compared to the state-of-the-art supervised DNN techniques.
Gradual Machine Learning for Entity Resolution
Oct 29, 2018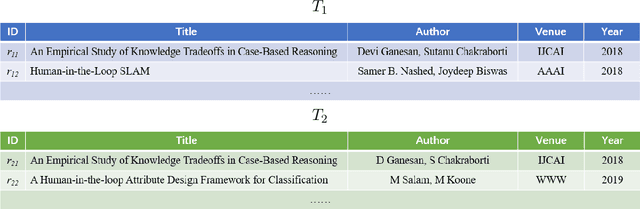

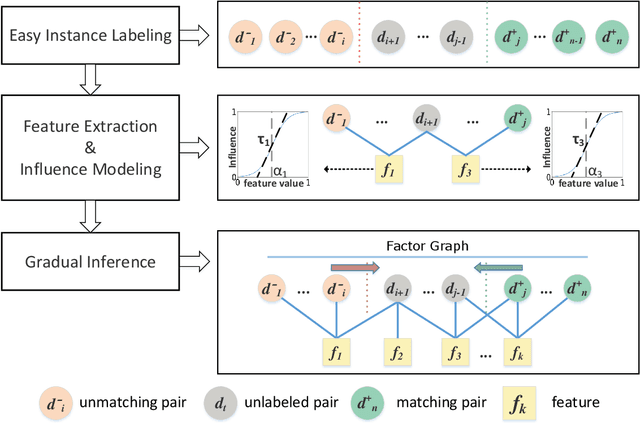
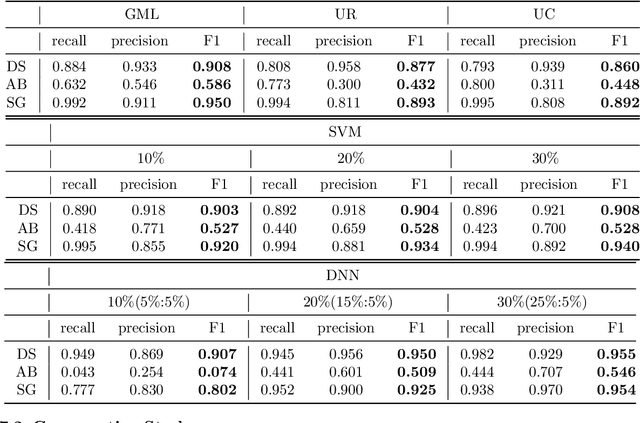
Usually considered as a classification problem, entity resolution can be very challenging on real data due to the prevalence of dirty values. The state-of-the-art solutions for ER were built on a variety of learning models (most notably deep neural networks), which require lots of accurately labeled training data. Unfortunately, high-quality labeled data usually require expensive manual work, and are therefore not readily available in many real scenarios. In this paper, we propose a novel learning paradigm for ER, called gradual machine learning, which aims to enable effective machine learning without the requirement for manual labeling effort. It begins with some easy instances in a task, which can be automatically labeled by the machine with high accuracy, and then gradually labels more challenging instances based on iterative factor graph inference. In gradual machine learning, the hard instances in a task are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on real data have shown that the proposed approach performs considerably better than its unsupervised alternatives, and it is highly competitive with the state-of-the-art supervised techniques. Using ER as a test case, we demonstrate that gradual machine learning is a promising paradigm potentially applicable to other challenging classification tasks requiring extensive labeling effort.