 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Deep Learning for Multiclass Breast Cancer Classification via Misprediction Risk Analysis
Mar 17, 2025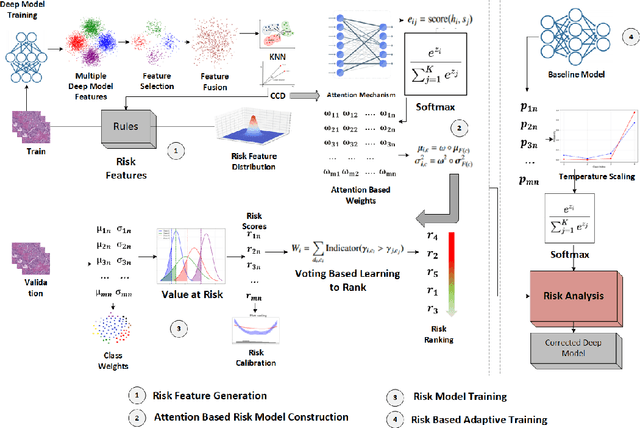

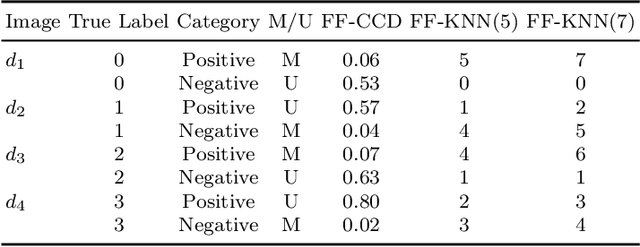
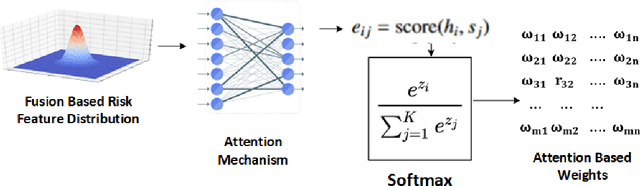
Breast cancer remains one of the leading causes of cancer-related deaths worldwide. Early detection is crucial for improving patient outcomes, yet the diagnostic process is often complex and prone to inconsistencies among pathologists. Computer-aided diagnostic approaches have significantly enhanced breast cancer detection, particularly in binary classification (benign vs. malignant). However, these methods face challenges in multiclass classification, leading to frequent mispredictions. In this work, we propose a novel adaptive learning approach for multiclass breast cancer classification using H&E-stained histopathology images. First, we introduce a misprediction risk analysis framework that quantifies and ranks the likelihood of an image being mislabeled by a classifier. This framework leverages an interpretable risk model that requires only a small number of labeled samples for training. Next, we present an adaptive learning strategy that fine-tunes classifiers based on the specific characteristics of a given dataset. This approach minimizes misprediction risk, allowing the classifier to adapt effectively to the target workload. We evaluate our proposed solutions on real benchmark datasets, demonstrating that our risk analysis framework more accurately identifies mispredictions compared to existing methods. Furthermore, our adaptive learning approach significantly improves the performance of state-of-the-art deep neural network classifiers.