 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Physical Attack against Face Recognition Systems via LED Illumination Modulation
Aug 07, 2023



Although face recognition starts to play an important role in our daily life, we need to pay attention that data-driven face recognition vision systems are vulnerable to adversarial attacks. However, the current two categories of adversarial attacks, namely digital attacks and physical attacks both have drawbacks, with the former ones impractical and the latter one conspicuous, high-computational and inexecutable. To address the issues, we propose a practical, executable, inconspicuous and low computational adversarial attack based on LED illumination modulation. To fool the systems, the proposed attack generates imperceptible luminance changes to human eyes through fast intensity modulation of scene LED illumination and uses the rolling shutter effect of CMOS image sensors in face recognition systems to implant luminance information perturbation to the captured face images. In summary,we present a denial-of-service (DoS) attack for face detection and a dodging attack for face verification. We also evaluate their effectiveness against well-known face detection models, Dlib, MTCNN and RetinaFace , and face verification models, Dlib, FaceNet,and ArcFace.The extensive experiments show that the success rates of DoS attacks against face detection models reach 97.67%, 100%, and 100%, respectively, and the success rates of dodging attacks against all face verification models reach 100%.
Non-exemplar Class-incremental Learning by Random Auxiliary Classes Augmentation and Mixed Features
Apr 16, 2023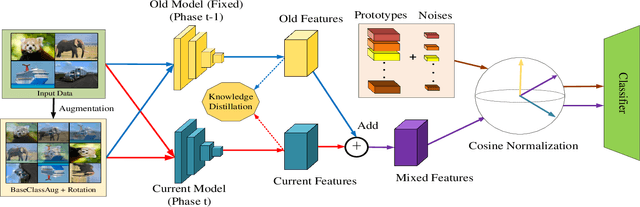
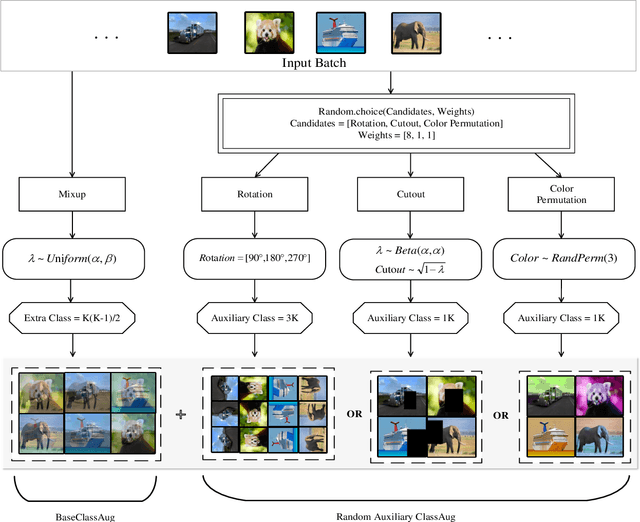
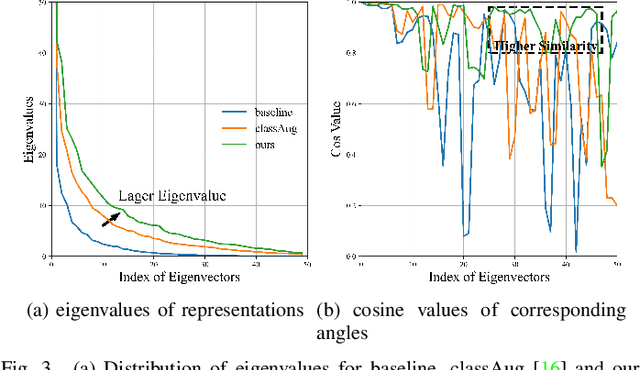
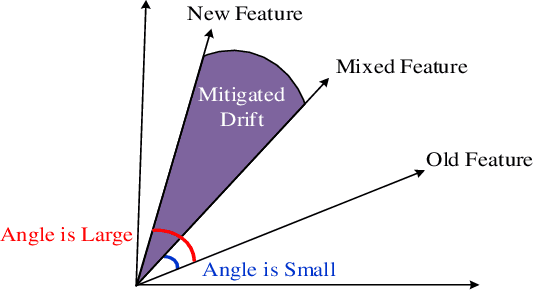
Non-exemplar class-incremental learning refers to classifying new and old classes without storing samples of old classes. Since only new class samples are available for optimization, it often occurs catastrophic forgetting of old knowledge. To alleviate this problem, many new methods are proposed such as model distillation, class augmentation. In this paper, we propose an effective non-exemplar method called RAMF consisting of Random Auxiliary classes augmentation and Mixed Feature. On the one hand, we design a novel random auxiliary classes augmentation method, where one augmentation is randomly selected from three augmentations and applied on the input to generate augmented samples and extra class labels. By extending data and label space, it allows the model to learn more diverse representations, which can prevent the model from being biased towards learning task-specific features. When learning new tasks, it will reduce the change of feature space and improve model generalization. On the other hand, we employ mixed feature to replace the new features since only using new feature to optimize the model will affect the representation that was previously embedded in the feature space. Instead, by mixing new and old features, old knowledge can be retained without increasing the computational complexity. Extensive experiments on three benchmarks demonstrate the superiority of our approach, which outperforms the state-of-the-art non-exemplar methods and is comparable to high-performance replay-based methods.
New Insights on Relieving Task-Recency Bias for Online Class Incremental Learning
Feb 16, 2023To imitate the ability of keeping learning of human, continual learning which can learn from a never-ending data stream has attracted more interests recently. In all settings, the online class incremental learning (CIL), where incoming samples from data stream can be used only once, is more challenging and can be encountered more frequently in real world. Actually, the CIL faces a stability-plasticity dilemma, where the stability means the ability to preserve old knowledge while the plasticity denotes the ability to incorporate new knowledge. Although replay-based methods have shown exceptional promise, most of them concentrate on the strategy for updating and retrieving memory to keep stability at the expense of plasticity. To strike a preferable trade-off between stability and plasticity, we propose a Adaptive Focus Shifting algorithm (AFS), which dynamically adjusts focus to ambiguous samples and non-target logits in model learning. Through a deep analysis of the task-recency bias caused by class imbalance, we propose a revised focal loss to mainly keep stability. By utilizing a new weight function, the revised focal loss can pay more attention to current ambiguous samples, which can provide more information of the classification boundary. To promote plasticity, we introduce a virtual knowledge distillation. By designing a virtual teacher, it assigns more attention to non-target classes, which can surmount overconfidence and encourage model to focus on inter-class information. Extensive experiments on three popular datasets for CIL have shown the effectiveness of AFS. The code will be available at \url{https://github.com/czjghost/AFS}.