 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoalition Formation in LLM Agent Networks: Stability Analysis and Convergence Guarantees
Apr 15, 2026Large Language Model (LLM) agents are increasingly deployed in multi-agent systems requiring strategic coordination. While recent work has analyzed LLM behavior in two-player games, coalition formation, where $n$ agents dynamically form cooperative groups, remains theoretically uncharacterized. We present the first framework grounding coalition formation in LLM agent networks in hedonic game theory with formal stability guarantees. We introduce the LLM Coalition Formation Game (LCFG), establish sufficient conditions for Nash-stable partitions, and prove complexity results. Our analysis reveals that LLM agents exhibit bounded rationality characterized by $ε$-rational preferences; we provide both deterministic existence guarantees and consistency-driven stability bounds whose predictions are consistent with empirical outcomes. Experiments with GPT-4, Claude-3, and Llama-3 across 2,400 episodes validate our framework: LLM coalitions achieve Nash stability in 73.2% of cases under our Coalition-of-Thought (CoalT) protocol, compared to 58.4% under chain-of-thought and 41.8% under standard prompting ($p < 0.001$). Our framework provides theoretical foundations for designing stable multi-agent LLM systems.
UniBioTransfer: A Unified Framework for Multiple Biometrics Transfer
Mar 20, 2026Deepface generation has traditionally followed a task-driven paradigm, where distinct tasks (e.g., face transfer and hair transfer) are addressed by task-specific models. Nevertheless, this single-task setting severely limits model generalization and scalability. A unified model capable of solving multiple deepface generation tasks in a single pass represents a promising and practical direction, yet remains challenging due to data scarcity and cross-task conflicts arising from heterogeneous attribute transformations. To this end, we propose UniBioTransfer, the first unified framework capable of handling both conventional deepface tasks (e.g., face transfer and face reenactment) and shape-varying transformations (e.g., hair transfer and head transfer). Besides, UniBioTransfer naturally generalizes to unseen tasks, like lip, eye, and glasses transfer, with minimal fine-tuning. Generally, UniBioTransfer addresses data insufficiency in multi-task generation through a unified data construction strategy, including a swapping-based corruption mechanism designed for spatially dynamic attributes like hair. It further mitigates cross-task interference via an innovative BioMoE, a mixture-of-experts based model coupled with a novel two-stage training strategy that effectively disentangles task-specific knowledge. Extensive experiments demonstrate the effectiveness, generalization, and scalability of UniBioTransfer, outperforming both existing unified models and task-specific methods across a wide range of deepface generation tasks. Project page is at https://scy639.github.io/UniBioTransfer.github.io/
MODE: Efficient Time Series Prediction with Mamba Enhanced by Low-Rank Neural ODEs
Jan 01, 2026Time series prediction plays a pivotal role across diverse domains such as finance, healthcare, energy systems, and environmental modeling. However, existing approaches often struggle to balance efficiency, scalability, and accuracy, particularly when handling long-range dependencies and irregularly sampled data. To address these challenges, we propose MODE, a unified framework that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with an Enhanced Mamba architecture. As illustrated in our framework, the input sequence is first transformed by a Linear Tokenization Layer and then processed through multiple Mamba Encoder blocks, each equipped with an Enhanced Mamba Layer that employs Causal Convolution, SiLU activation, and a Low-Rank Neural ODE enhancement to efficiently capture temporal dynamics. This low-rank formulation reduces computational overhead while maintaining expressive power. Furthermore, a segmented selective scanning mechanism, inspired by pseudo-ODE dynamics, adaptively focuses on salient subsequences to improve scalability and long-range sequence modeling. Extensive experiments on benchmark datasets demonstrate that MODE surpasses existing baselines in both predictive accuracy and computational efficiency. Overall, our contributions include: (1) a unified and efficient architecture for long-term time series modeling, (2) integration of Mamba's selective scanning with low-rank Neural ODEs for enhanced temporal representation, and (3) substantial improvements in efficiency and scalability enabled by low-rank approximation and dynamic selective scanning.
ConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
Nov 19, 2025Instruction-following is a critical capability of Large Language Models (LLMs). While existing works primarily focus on assessing how well LLMs adhere to user instructions, they often overlook scenarios where instructions contain conflicting constraints-a common occurrence in complex prompts. The behavior of LLMs under such conditions remains under-explored. To bridge this gap, we introduce ConInstruct, a benchmark specifically designed to assess LLMs' ability to detect and resolve conflicts within user instructions. Using this dataset, we evaluate LLMs' conflict detection performance and analyze their conflict resolution behavior. Our experiments reveal two key findings: (1) Most proprietary LLMs exhibit strong conflict detection capabilities, whereas among open-source models, only DeepSeek-R1 demonstrates similarly strong performance. DeepSeek-R1 and Claude-4.5-Sonnet achieve the highest average F1-scores at 91.5% and 87.3%, respectively, ranking first and second overall. (2) Despite their strong conflict detection abilities, LLMs rarely explicitly notify users about the conflicts or request clarification when faced with conflicting constraints. These results underscore a critical shortcoming in current LLMs and highlight an important area for future improvement when designing instruction-following LLMs.
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025
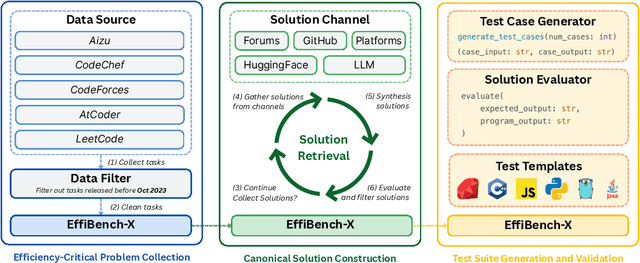


Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
HMamba: Hyperbolic Mamba for Sequential Recommendation
May 14, 2025Sequential recommendation systems have become a cornerstone of personalized services, adept at modeling the temporal evolution of user preferences by capturing dynamic interaction sequences. Existing approaches predominantly rely on traditional models, including RNNs and Transformers. Despite their success in local pattern recognition, Transformer-based methods suffer from quadratic computational complexity and a tendency toward superficial attention patterns, limiting their ability to infer enduring preference hierarchies in sequential recommendation data. Recent advances in Mamba-based sequential models introduce linear-time efficiency but remain constrained by Euclidean geometry, failing to leverage the intrinsic hyperbolic structure of recommendation data. To bridge this gap, we propose Hyperbolic Mamba, a novel architecture that unifies the efficiency of Mamba's selective state space mechanism with hyperbolic geometry's hierarchical representational power. Our framework introduces (1) a hyperbolic selective state space that maintains curvature-aware sequence modeling and (2) stabilized Riemannian operations to enable scalable training. Experiments across four benchmarks demonstrate that Hyperbolic Mamba achieves 3-11% improvement while retaining Mamba's linear-time efficiency, enabling real-world deployment. This work establishes a new paradigm for efficient, hierarchy-aware sequential modeling.
M2Rec: Multi-scale Mamba for Efficient Sequential Recommendation
May 07, 2025Sequential recommendation systems aim to predict users' next preferences based on their interaction histories, but existing approaches face critical limitations in efficiency and multi-scale pattern recognition. While Transformer-based methods struggle with quadratic computational complexity, recent Mamba-based models improve efficiency but fail to capture periodic user behaviors, leverage rich semantic information, or effectively fuse multimodal features. To address these challenges, we propose \model, a novel sequential recommendation framework that integrates multi-scale Mamba with Fourier analysis, Large Language Models (LLMs), and adaptive gating. First, we enhance Mamba with Fast Fourier Transform (FFT) to explicitly model periodic patterns in the frequency domain, separating meaningful trends from noise. Second, we incorporate LLM-based text embeddings to enrich sparse interaction data with semantic context from item descriptions. Finally, we introduce a learnable gate mechanism to dynamically balance temporal (Mamba), frequency (FFT), and semantic (LLM) features, ensuring harmonious multimodal fusion. Extensive experiments demonstrate that \model\ achieves state-of-the-art performance, improving Hit Rate@10 by 3.2\% over existing Mamba-based models while maintaining 20\% faster inference than Transformer baselines. Our results highlight the effectiveness of combining frequency analysis, semantic understanding, and adaptive fusion for sequential recommendation. Code and datasets are available at: https://anonymous.4open.science/r/M2Rec.
Graph Masked Autoencoder for Spatio-Temporal Graph Learning
Oct 14, 2024Effective spatio-temporal prediction frameworks play a crucial role in urban sensing applications, including traffic analysis, human mobility behavior modeling, and citywide crime prediction. However, the presence of data noise and label sparsity in spatio-temporal data presents significant challenges for existing neural network models in learning effective and robust region representations. To address these challenges, we propose a novel spatio-temporal graph masked autoencoder paradigm that explores generative self-supervised learning for effective spatio-temporal data augmentation. Our proposed framework introduces a spatial-temporal heterogeneous graph neural encoder that captures region-wise dependencies from heterogeneous data sources, enabling the modeling of diverse spatial dependencies. In our spatio-temporal self-supervised learning paradigm, we incorporate a masked autoencoding mechanism on node representations and structures. This mechanism automatically distills heterogeneous spatio-temporal dependencies across regions over time, enhancing the learning process of dynamic region-wise spatial correlations. To validate the effectiveness of our STGMAE framework, we conduct extensive experiments on various spatio-temporal mining tasks. We compare our approach against state-of-the-art baselines. The results of these evaluations demonstrate the superiority of our proposed framework in terms of performance and its ability to address the challenges of spatial and temporal data noise and sparsity in practical urban sensing scenarios.
TUBench: Benchmarking Large Vision-Language Models on Trustworthiness with Unanswerable Questions
Oct 05, 2024

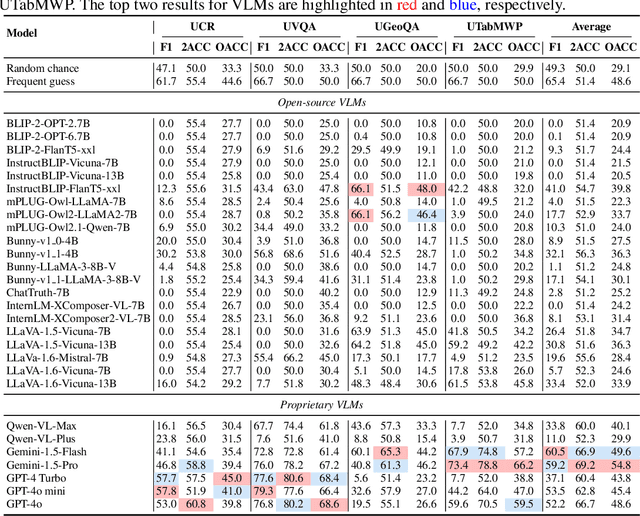

Large Vision-Language Models (LVLMs) have achieved remarkable progress on visual perception and linguistic interpretation. Despite their impressive capabilities across various tasks, LVLMs still suffer from the issue of hallucination, which involves generating content that is incorrect or unfaithful to the visual or textual inputs. Traditional benchmarks, such as MME and POPE, evaluate hallucination in LVLMs within the scope of Visual Question Answering (VQA) using answerable questions. However, some questions are unanswerable due to insufficient information in the images, and the performance of LVLMs on such unanswerable questions remains underexplored. To bridge this research gap, we propose TUBench, a benchmark specifically designed to evaluate the reliability of LVLMs using unanswerable questions. TUBench comprises an extensive collection of high-quality, unanswerable questions that are meticulously crafted using ten distinct strategies. To thoroughly evaluate LVLMs, the unanswerable questions in TUBench are based on images from four diverse domains as visual contexts: screenshots of code snippets, natural images, geometry diagrams, and screenshots of statistical tables. These unanswerable questions are tailored to test LVLMs' trustworthiness in code reasoning, commonsense reasoning, geometric reasoning, and mathematical reasoning related to tables, respectively. We conducted a comprehensive quantitative evaluation of 28 leading foundational models on TUBench, with Gemini-1.5-Pro, the top-performing model, achieving an average accuracy of 69.2%, and GPT-4o, the third-ranked model, reaching 66.7% average accuracy, in determining whether questions are answerable. TUBench is available at https://github.com/NLPCode/TUBench.
A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security
Oct 03, 2024



The widespread adoption of smartphones and Location-Based Social Networks has led to a massive influx of spatio-temporal data, creating unparalleled opportunities for enhancing Point-of-Interest (POI) recommendation systems. These advanced POI systems are crucial for enriching user experiences, enabling personalized interactions, and optimizing decision-making processes in the digital landscape. However, existing surveys tend to focus on traditional approaches and few of them delve into cutting-edge developments, emerging architectures, as well as security considerations in POI recommendations. To address this gap, our survey stands out by offering a comprehensive, up-to-date review of POI recommendation systems, covering advancements in models, architectures, and security aspects. We systematically examine the transition from traditional models to advanced techniques such as large language models. Additionally, we explore the architectural evolution from centralized to decentralized and federated learning systems, highlighting the improvements in scalability and privacy. Furthermore, we address the increasing importance of security, examining potential vulnerabilities and privacy-preserving approaches. Our taxonomy provides a structured overview of the current state of POI recommendation, while we also identify promising directions for future research in this rapidly advancing field.