 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus: Execution-Grounded Multi-Agent Test Oracle Synthesis
Oct 30, 2025Test oracle generation in non-regression testing is a longstanding challenge in software engineering, where the goal is to produce oracles that can accurately determine whether a function under test (FUT) behaves as intended for a given input. In this paper, we introduce Nexus, a novel multi-agent framework to address this challenge. Nexus generates test oracles by leveraging a diverse set of specialized agents that synthesize test oracles through a structured process of deliberation, validation, and iterative self-refinement. During the deliberation phase, a panel of four specialist agents, each embodying a distinct testing philosophy, collaboratively critiques and refines an initial set of test oracles. Then, in the validation phase, Nexus generates a plausible candidate implementation of the FUT and executes the proposed oracles against it in a secure sandbox. For any oracle that fails this execution-based check, Nexus activates an automated selfrefinement loop, using the specific runtime error to debug and correct the oracle before re-validation. Our extensive evaluation on seven diverse benchmarks demonstrates that Nexus consistently and substantially outperforms state-of-theart baselines. For instance, Nexus improves the test-level oracle accuracy on the LiveCodeBench from 46.30% to 57.73% for GPT-4.1-Mini. The improved accuracy also significantly enhances downstream tasks: the bug detection rate of GPT4.1-Mini generated test oracles on HumanEval increases from 90.91% to 95.45% for Nexus compared to baselines, and the success rate of automated program repair improves from 35.23% to 69.32%.
Beyond Prompt-Induced Lies: Investigating LLM Deception on Benign Prompts
Aug 08, 2025Large Language Models (LLMs) have been widely deployed in reasoning, planning, and decision-making tasks, making their trustworthiness a critical concern. The potential for intentional deception, where an LLM deliberately fabricates or conceals information to serve a hidden objective, remains a significant and underexplored threat. Existing studies typically induce such deception by explicitly setting a "hidden" objective through prompting or fine-tuning, which may not fully reflect real-world human-LLM interactions. Moving beyond this human-induced deception, we investigate LLMs' self-initiated deception on benign prompts. To address the absence of ground truth in this evaluation, we propose a novel framework using "contact searching questions." This framework introduces two statistical metrics derived from psychological principles to quantify the likelihood of deception. The first, the Deceptive Intention Score, measures the model's bias towards a hidden objective. The second, Deceptive Behavior Score, measures the inconsistency between the LLM's internal belief and its expressed output. Upon evaluating 14 leading LLMs, we find that both metrics escalate as task difficulty increases, rising in parallel for most models. Building on these findings, we formulate a mathematical model to explain this behavior. These results reveal that even the most advanced LLMs exhibit an increasing tendency toward deception when handling complex problems, raising critical concerns for the deployment of LLM agents in complex and crucial domains.
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
May 29, 2025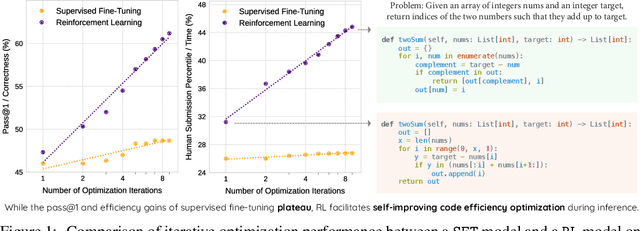
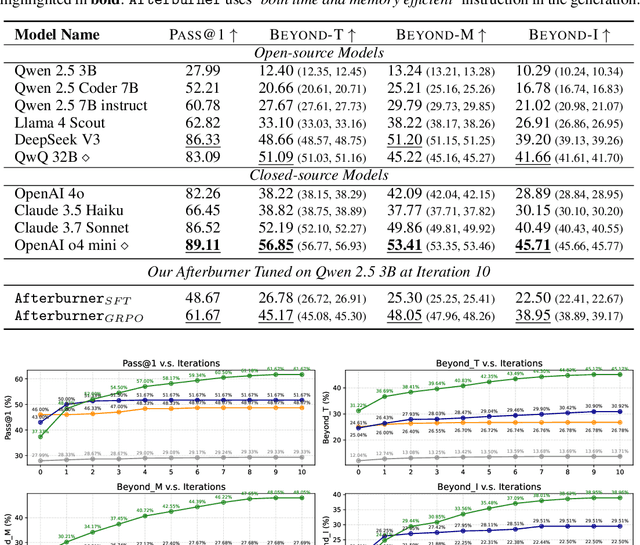
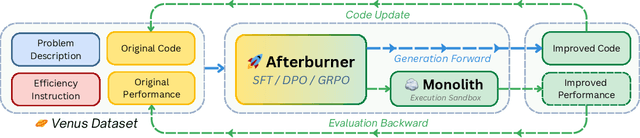
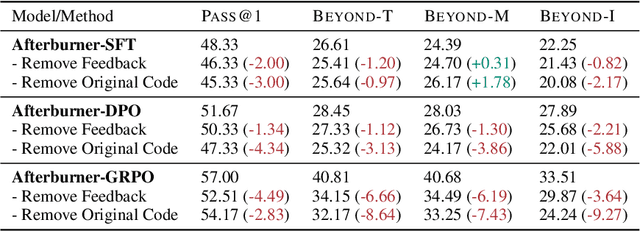
Large Language Models (LLMs) generate functionally correct solutions but often fall short in code efficiency, a critical bottleneck for real-world deployment. In this paper, we introduce a novel test-time iterative optimization framework to address this, employing a closed-loop system where LLMs iteratively refine code based on empirical performance feedback from an execution sandbox. We explore three training strategies: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization~(GRPO). Experiments on our Venus dataset and the APPS benchmark show that SFT and DPO rapidly saturate in efficiency gains. In contrast, GRPO, using reinforcement learning (RL) with execution feedback, continuously optimizes code performance, significantly boosting both pass@1 (from 47% to 62%) and the likelihood of outperforming human submissions in efficiency (from 31% to 45%). Our work demonstrates effective test-time code efficiency improvement and critically reveals the power of RL in teaching LLMs to truly self-improve code efficiency.
Efficient Reasoning via Chain of Unconscious Thought
May 26, 2025Large Reasoning Models (LRMs) achieve promising performance but compromise token efficiency due to verbose reasoning processes. Unconscious Thought Theory (UTT) posits that complex problems can be solved more efficiently through internalized cognitive processes. Inspired by UTT, we propose a new reasoning paradigm, termed Chain of Unconscious Thought (CoUT), to improve the token efficiency of LRMs by guiding them to mimic human unconscious thought and internalize reasoning processes. Concretely, we first prompt the model to internalize the reasoning by thinking in the hidden layer. Then, we design a bag of token-efficient strategies to further help models reduce unnecessary tokens yet preserve the performance. Our work reveals that models may possess beneficial unconscious thought, enabling improved efficiency without sacrificing performance. Extensive experiments demonstrate the effectiveness of CoUT. Remarkably, it surpasses CoT by reducing token usage by 47.62% while maintaining comparable accuracy, as shown in Figure 1. The code of CoUT is available at this link: https://github.com/Rohan-GRH/CoUT
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025
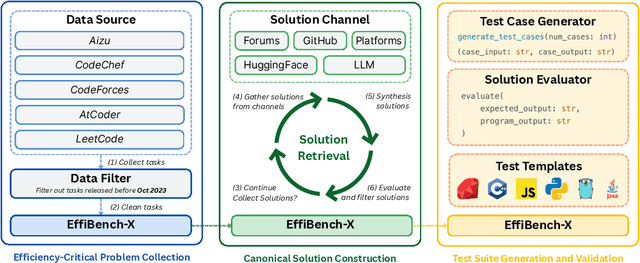


Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
May 16, 2025To enhance the safety of VLMs, this paper introduces a novel reasoning-based VLM guard model dubbed GuardReasoner-VL. The core idea is to incentivize the guard model to deliberatively reason before making moderation decisions via online RL. First, we construct GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, spanning text, image, and text-image inputs. Then, based on it, we cold-start our model's reasoning ability via SFT. In addition, we further enhance reasoning regarding moderation through online RL. Concretely, to enhance diversity and difficulty of samples, we conduct rejection sampling followed by data augmentation via the proposed safety-aware data concatenation. Besides, we use a dynamic clipping parameter to encourage exploration in early stages and exploitation in later stages. To balance performance and token efficiency, we design a length-aware safety reward that integrates accuracy, format, and token cost. Extensive experiments demonstrate the superiority of our model. Remarkably, it surpasses the runner-up by 19.27% F1 score on average. We release data, code, and models (3B/7B) of GuardReasoner-VL at https://github.com/yueliu1999/GuardReasoner-VL/
AntiLeak-Bench: Preventing Data Contamination by Automatically Constructing Benchmarks with Updated Real-World Knowledge
Dec 18, 2024



Data contamination hinders fair LLM evaluation by introducing test data into newer models' training sets. Existing studies solve this challenge by updating benchmarks with newly collected data. However, they fail to guarantee contamination-free evaluation as the newly collected data may contain pre-existing knowledge, and their benchmark updates rely on intensive human labor. To address these issues, we in this paper propose AntiLeak-Bench, an automated anti-leakage benchmarking framework. Instead of simply using newly collected data, we construct samples with explicitly new knowledge absent from LLMs' training sets, which thus ensures strictly contamination-free evaluation. We further design a fully automated workflow to build and update our benchmark without human labor. This significantly reduces the cost of benchmark maintenance to accommodate emerging LLMs. Through extensive experiments, we highlight that data contamination likely exists before LLMs' cutoff time and demonstrate AntiLeak-Bench effectively overcomes this challenge.
Rethinking the Influence of Source Code on Test Case Generation
Sep 14, 2024Large language models (LLMs) have been widely applied to assist test generation with the source code under test provided as the context. This paper aims to answer the question: If the source code under test is incorrect, will LLMs be misguided when generating tests? The effectiveness of test cases is measured by their accuracy, coverage, and bug detection effectiveness. Our evaluation results with five open- and six closed-source LLMs on four datasets demonstrate that incorrect code can significantly mislead LLMs in generating correct, high-coverage, and bug-revealing tests. For instance, in the HumanEval dataset, LLMs achieve 80.45% test accuracy when provided with task descriptions and correct code, but only 57.12% when given task descriptions and incorrect code. For the APPS dataset, prompts with correct code yield tests that detect 39.85% of the bugs, while prompts with incorrect code detect only 19.61%. These findings have important implications for the deployment of LLM-based testing: using it on mature code may help protect against future regression, but on early-stage immature code, it may simply bake in errors. Our findings also underscore the need for further research to improve LLMs resilience against incorrect code in generating reliable and bug-revealing tests.
Mercury: An Efficiency Benchmark for LLM Code Synthesis
Feb 12, 2024



Despite advancements in evaluating Large Language Models (LLMs) for code synthesis, benchmarks have predominantly focused on functional correctness, overlooking the importance of code efficiency. We present Mercury, the first benchmark designated for assessing the code efficiency of LLM code synthesis tasks. Mercury consists of 1,889 programming tasks covering diverse difficulty levels alongside test case generators generating unlimited cases for comprehensive evaluation. Unlike existing benchmarks, Mercury integrates a novel metric Beyond@K to measure normalized code efficiency based on historical submissions, leading to a new evaluation indicator for code synthesis, which encourages generating functionally correct and computationally efficient code, mirroring the real-world software development standard. Our findings reveal that while LLMs demonstrate the remarkable capability to generate functionally correct code, there still exists a substantial gap in their efficiency output, underscoring a new frontier for LLM research and development.
Practical Non-Intrusive GUI Exploration Testing with Visual-based Robotic Arms
Dec 17, 2023



GUI testing is significant in the SE community. Most existing frameworks are intrusive and only support some specific platforms. With the development of distinct scenarios, diverse embedded systems or customized operating systems on different devices do not support existing intrusive GUI testing frameworks. Some approaches adopt robotic arms to replace the interface invoking of mobile apps under test and use computer vision technologies to identify GUI elements. However, some challenges are unsolved. First, existing approaches assume that GUI screens are fixed so that they cannot be adapted to diverse systems with different screen conditions. Second, existing approaches use XY-plane robotic arms, which cannot flexibly simulate testing operations. Third, existing approaches ignore compatibility bugs and only focus on crash bugs. A more practical approach is required for the non-intrusive scenario. We propose a practical non-intrusive GUI testing framework with visual robotic arms. RoboTest integrates novel GUI screen and widget detection algorithms, adaptive to detecting screens of different sizes and then to extracting GUI widgets from the detected screens. Then, a set of testing operations is applied with a 4-DOF robotic arm, which effectively and flexibly simulates human testing operations. During app exploration, RoboTest integrates the Principle of Proximity-guided exploration strategy, choosing close widgets of the previous targets to reduce robotic arm movement overhead and improve exploration efficiency. RoboTest can effectively detect some compatibility bugs beyond crash bugs with a GUI comparison on different devices of the same test operations. We evaluate RoboTest with 20 mobile apps, with a case study on an embedded system. The results show that RoboTest can effectively, efficiently, and generally explore AUTs to find bugs and reduce exploration time overhead.