 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Harness for Real-World Compilers
Mar 20, 2026Compilers are critical to modern computing, yet fixing compiler bugs is difficult. While recent large language model (LLM) advancements enable automated bug repair, compiler bugs pose unique challenges due to their complexity, deep cross-domain expertise requirements, and sparse, non-descriptive bug reports, necessitating compiler-specific tools. To bridge the gap, we introduce llvm-autofix, the first agentic harness designed to assist LLM agents in understanding and fixing compiler bugs. Our focus is on LLVM, one of the most widely used compiler infrastructures. Central to llvm-autofix are agent-friendly LLVM tools, a benchmark llvm-bench of reproducible LLVM bugs, and a tailored minimal agent llvm-autofix-mini for fixing LLVM bugs. Our evaluation demonstrates a performance decline of 60% in frontier models when tackling compiler bugs compared with common software bugs. Our minimal agent llvm-autofix-mini also outperforms the state-of-the-art by approximately 22%. This emphasizes the necessity for specialized harnesses like ours to close the loop between LLMs and compiler engineering. We believe this work establishes a foundation for advancing LLM capabilities in complex systems like compilers. GitHub: https://github.com/dtcxzyw/llvm-autofix
Stepwise: Neuro-Symbolic Proof Search for Automated Systems Verification
Mar 20, 2026Formal verification via interactive theorem proving is increasingly used to ensure the correctness of critical systems, yet constructing large proof scripts remains highly manual and limits scalability. Advances in large language models (LLMs), especially in mathematical reasoning, make their integration into software verification increasingly promising. This paper introduces a neuro-symbolic proof generation framework designed to automate proof search for systems-level verification projects. The framework performs a best-first tree search over proof states, repeatedly querying an LLM for the next candidate proof step. On the neural side, we fine-tune LLMs using datasets of proof state-step pairs; on the symbolic side, we incorporate a range of ITP tools to repair rejected steps, filter and rank proof states, and automatically discharge subgoals when search progress stalls. This synergy enables data-efficient LLM adaptation and semantics-informed pruning of the search space. We implement the framework on a new Isabelle REPL that exposes fine-grained proof states and automation tools, and evaluate it on the FVEL seL4 benchmark and additional Isabelle developments. On seL4, the system proves up to 77.6\% of the theorems, substantially surpassing previous LLM-based approaches and standalone Sledgehammer, while solving significantly more multi-step proofs. Results across further benchmarks demonstrate strong generalization, indicating a viable path toward scalable automated software verification.
Learning to Disprove: Formal Counterexample Generation with Large Language Models
Mar 19, 2026Mathematical reasoning demands two critical, complementary skills: constructing rigorous proofs for true statements and discovering counterexamples that disprove false ones. However, current AI efforts in mathematics focus almost exclusively on proof construction, often neglecting the equally important task of finding counterexamples. In this paper, we address this gap by fine-tuning large language models (LLMs) to reason about and generate counterexamples. We formalize this task as formal counterexample generation, which requires LLMs not only to propose candidate counterexamples but also to produce formal proofs that can be automatically verified in the Lean 4 theorem prover. To enable effective learning, we introduce a symbolic mutation strategy that synthesizes diverse training data by systematically extracting theorems and discarding selected hypotheses, thereby producing diverse counterexample instances. Together with curated datasets, this strategy enables a multi-reward expert iteration framework that substantially enhances both the effectiveness and efficiency of training LLMs for counterexample generation and theorem proving. Experiments on three newly collected benchmarks validate the advantages of our approach, showing that the mutation strategy and training framework yield significant performance gains.
API-guided Dataset Synthesis to Finetune Large Code Models
Aug 15, 2024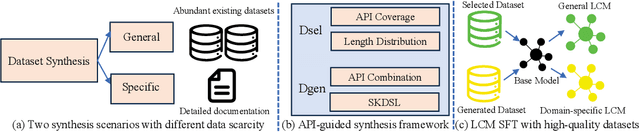
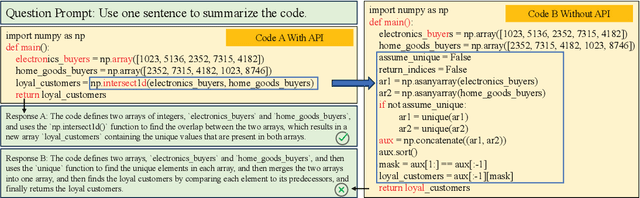
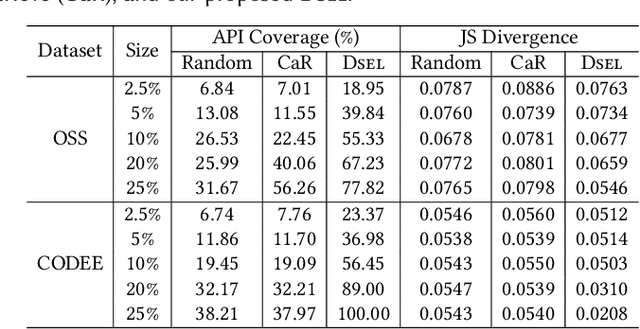
Large code models (LCMs), pre-trained on vast code corpora, have demonstrated remarkable performance across a wide array of code-related tasks. Supervised fine-tuning (SFT) plays a vital role in aligning these models with specific requirements and enhancing their performance in particular domains. However, synthesizing high-quality SFT datasets poses a significant challenge due to the uneven quality of datasets and the scarcity of domain-specific datasets. Inspired by APIs as high-level abstractions of code that encapsulate rich semantic information in a concise structure, we propose DataScope, an API-guided dataset synthesis framework designed to enhance the SFT process for LCMs in both general and domain-specific scenarios. DataScope comprises two main components: Dsel and Dgen. On one hand, Dsel employs API coverage as a core metric, enabling efficient dataset synthesis in general scenarios by selecting subsets of existing (uneven-quality) datasets with higher API coverage. On the other hand, Dgen recasts domain dataset synthesis as a process of using API-specified high-level functionality and deliberately-constituted code skeletons to synthesize concrete code. Extensive experiments demonstrate DataScope's effectiveness, with models fine-tuned on its synthesized datasets outperforming those tuned on unoptimized datasets five times larger. Furthermore, a series of analyses on model internals, relevant hyperparameters, and case studies provide additional evidence for the efficacy of our proposed methods. These findings underscore the significance of dataset quality in SFT and advance the field of LCMs by providing an efficient, cost-effective framework for constructing high-quality datasets. This contribution enhances performance across both general and domain-specific scenarios, paving the way for more powerful and tailored LCMs.
Practical Non-Intrusive GUI Exploration Testing with Visual-based Robotic Arms
Dec 17, 2023



GUI testing is significant in the SE community. Most existing frameworks are intrusive and only support some specific platforms. With the development of distinct scenarios, diverse embedded systems or customized operating systems on different devices do not support existing intrusive GUI testing frameworks. Some approaches adopt robotic arms to replace the interface invoking of mobile apps under test and use computer vision technologies to identify GUI elements. However, some challenges are unsolved. First, existing approaches assume that GUI screens are fixed so that they cannot be adapted to diverse systems with different screen conditions. Second, existing approaches use XY-plane robotic arms, which cannot flexibly simulate testing operations. Third, existing approaches ignore compatibility bugs and only focus on crash bugs. A more practical approach is required for the non-intrusive scenario. We propose a practical non-intrusive GUI testing framework with visual robotic arms. RoboTest integrates novel GUI screen and widget detection algorithms, adaptive to detecting screens of different sizes and then to extracting GUI widgets from the detected screens. Then, a set of testing operations is applied with a 4-DOF robotic arm, which effectively and flexibly simulates human testing operations. During app exploration, RoboTest integrates the Principle of Proximity-guided exploration strategy, choosing close widgets of the previous targets to reduce robotic arm movement overhead and improve exploration efficiency. RoboTest can effectively detect some compatibility bugs beyond crash bugs with a GUI comparison on different devices of the same test operations. We evaluate RoboTest with 20 mobile apps, with a case study on an embedded system. The results show that RoboTest can effectively, efficiently, and generally explore AUTs to find bugs and reduce exploration time overhead.
Precise and Generalized Robustness Certification for Neural Networks
Jun 11, 2023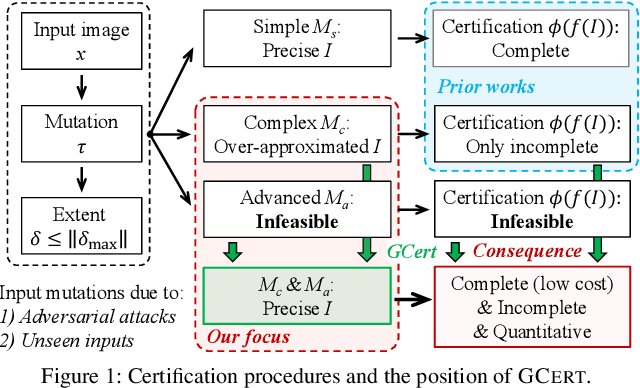
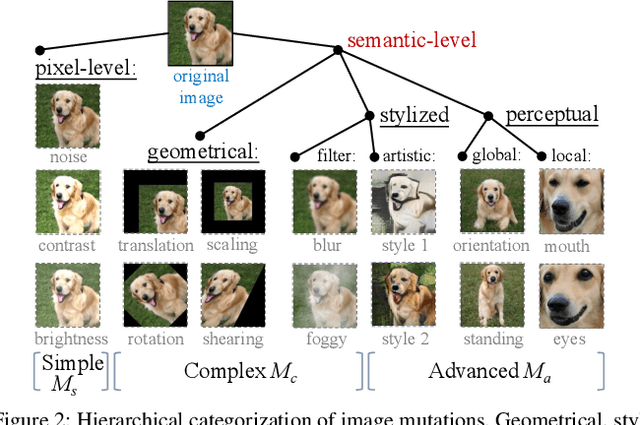
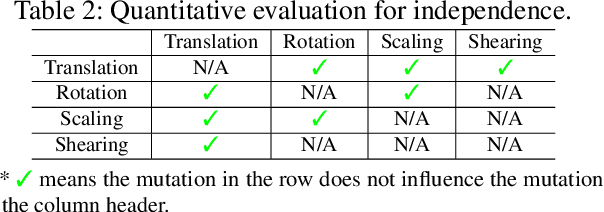
The objective of neural network (NN) robustness certification is to determine if a NN changes its predictions when mutations are made to its inputs. While most certification research studies pixel-level or a few geometrical-level and blurring operations over images, this paper proposes a novel framework, GCERT, which certifies NN robustness under a precise and unified form of diverse semantic-level image mutations. We formulate a comprehensive set of semantic-level image mutations uniformly as certain directions in the latent space of generative models. We identify two key properties, independence and continuity, that convert the latent space into a precise and analysis-friendly input space representation for certification. GCERT can be smoothly integrated with de facto complete, incomplete, or quantitative certification frameworks. With its precise input space representation, GCERT enables for the first time complete NN robustness certification with moderate cost under diverse semantic-level input mutations, such as weather-filter, style transfer, and perceptual changes (e.g., opening/closing eyes). We show that GCERT enables certifying NN robustness under various common and security-sensitive scenarios like autonomous driving.
ShapeFlow: Dynamic Shape Interpreter for TensorFlow
Nov 26, 2020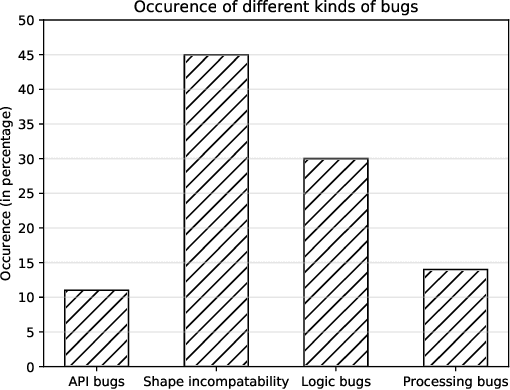
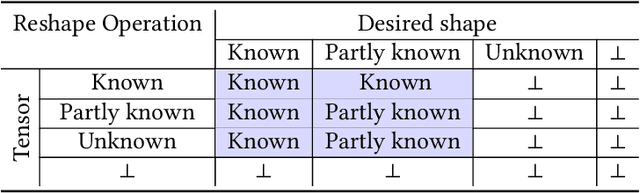


We present ShapeFlow, a dynamic abstract interpreter for TensorFlow which quickly catches tensor shape incompatibility errors, one of the most common bugs in deep learning code. ShapeFlow shares the same APIs as TensorFlow but only captures and emits tensor shapes, its abstract domain. ShapeFlow constructs a custom shape computational graph, similar to the computational graph used by TensorFlow. ShapeFlow requires no code annotation or code modification by the programmer, and therefore is convenient to use. We evaluate ShapeFlow on 52 programs collected by prior empirical studies to show how fast and accurately it can catch shape incompatibility errors compared to TensorFlow. We use two baselines: a worst-case training dataset size and a more realistic dataset size. ShapeFlow detects shape incompatibility errors highly accurately -- with no false positives and a single false negative -- and highly efficiently -- with an average speed-up of 499X and 24X for the first and second baseline, respectively. We believe ShapeFlow is a practical tool that benefits machine learning developers. We will open-source ShapeFlow on GitHub to make it publicly available to both the developer and research communities.
Testing Machine Translation via Referential Transparency
Apr 22, 2020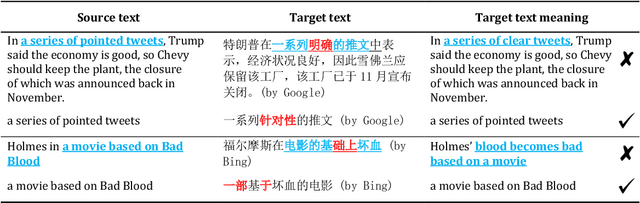
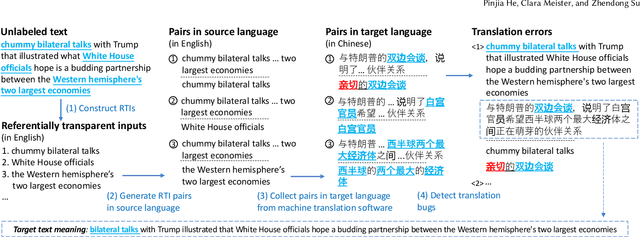

Machine translation software has seen rapid progress in recent years due to the advancement of deep neural networks. People routinely use machine translation software in their daily lives, such as ordering food in a foreign restaurant, receiving medical diagnosis and treatment from foreign doctors, and reading international political news online. However, due to the complexity and intractability of the underlying neural networks, modern machine translation software is still far from robust. To address this problem, we introduce referentially transparent inputs (RTIs), a simple, widely applicable methodology for validating machine translation software. A referentially transparent input is a piece of text that should have invariant translation when used in different contexts. Our practical implementation, Purity, detects when this invariance property is broken by a translation. To evaluate RTI, we use Purity to test Google Translate and Bing Microsoft Translator with 200 unlabeled sentences, which led to 123 and 142 erroneous translations with high precision (79.3\% and 78.3\%). The translation errors are diverse, including under-translation, over-translation, word/phrase mistranslation, incorrect modification, and unclear logic. These translation errors could lead to misunderstanding, financial loss, threats to personal safety and health, and political conflicts.
Metamorphic Testing for Object Detection Systems
Dec 19, 2019

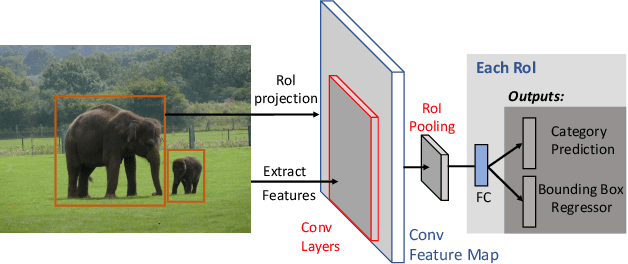

Recent advances in deep neural networks (DNNs) have led to object detectors that can rapidly process pictures or videos, and recognize the objects that they contain. Despite the promising progress by industrial manufacturers such as Amazon and Google in commercializing deep learning-based object detection as a standard computer vision service, object detection systems - similar to traditional software - may still produce incorrect results. These errors, in turn, can lead to severe negative outcomes for the users of these object detection systems. For instance, an autonomous driving system that fails to detect pedestrians can cause accidents or even fatalities. However, principled, systematic methods for testing object detection systems do not yet exist, despite their importance. To fill this critical gap, we introduce the design and realization of MetaOD, the first metamorphic testing system for object detectors to effectively reveal erroneous detection results by commercial object detectors. To this end, we (1) synthesize natural-looking images by inserting extra object instances into background images, and (2) design metamorphic conditions asserting the equivalence of object detection results between the original and synthetic images after excluding the prediction results on the inserted objects. MetaOD is designed as a streamlined workflow that performs object extraction, selection, and insertion. Evaluated on four commercial object detection services and four pretrained models provided by the TensorFlow API, MetaOD found tens of thousands of detection defects in these object detectors. To further demonstrate the practical usage of MetaOD, we use the synthetic images that cause erroneous detection results to retrain the model. Our results show that the model performance is increased significantly, from an mAP score of 9.3 to an mAP score of 10.5.
Structure-Invariant Testing for Machine Translation
Aug 24, 2019
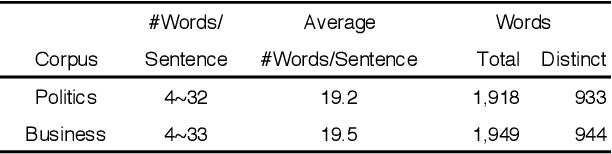
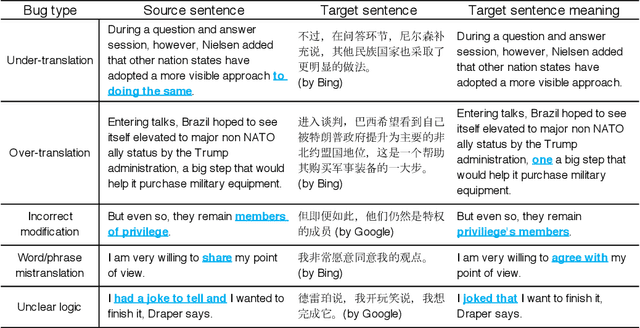
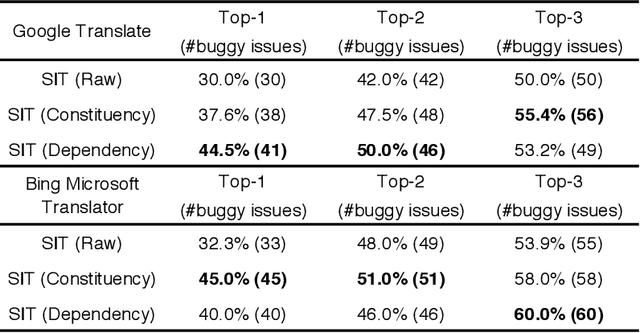
In recent years, machine translation software has increasingly been integrated into our daily lives. People routinely use machine translation for various applications, such as describing symptoms to a foreign doctor and reading political news in a foreign language. However, due to the complexity and intractability of neural machine translation (NMT) models that power modern machine translation systems, these systems are far from being robust. They can return inferior results that lead to misunderstanding, medical misdiagnoses, or threats to personal safety. Despite its apparent importance, validating the robustness of machine translation is very difficult and has, therefore, been much under-explored. To tackle this challenge, we introduce structure-invariant testing (SIT), a novel, widely applicable metamorphic testing methodology for validating machine translation software. Our key insight is that the translation results of similar source sentences should typically exhibit a similar sentence structure. SIT is designed to leverage this insight to test any machine translation system with unlabeled sentences; it specifically targets mistranslations that are difficult-to-find using state-of-the-art translation quality metrics such as BLEU. We have realized a practical implementation of SIT by (1) substituting one word in a given sentence with semantically similar, syntactically equivalent words to generate similar sentences, and (2) using syntax parse trees (obtained via constituency/dependency parsing) to represent sentence structure. To evaluate SIT, we have used it to test Google Translate and Bing Microsoft Translator with 200 unlabeled sentences as input, which led to 56 and 61 buggy translations with 60% and 61% top-1 accuracy, respectively. The bugs are diverse, including under-translation, over-translation, incorrect modification, word/phrase mistranslation, and unclear logic.