 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPI-guided Dataset Synthesis to Finetune Large Code Models
Paper and Code
Aug 15, 2024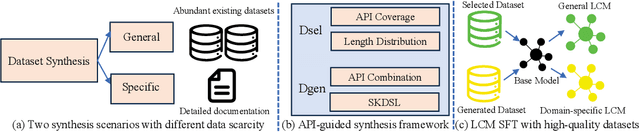
Large code models (LCMs), pre-trained on vast code corpora, have demonstrated remarkable performance across a wide array of code-related tasks. Supervised fine-tuning (SFT) plays a vital role in aligning these models with specific requirements and enhancing their performance in particular domains. However, synthesizing high-quality SFT datasets poses a significant challenge due to the uneven quality of datasets and the scarcity of domain-specific datasets. Inspired by APIs as high-level abstractions of code that encapsulate rich semantic information in a concise structure, we propose DataScope, an API-guided dataset synthesis framework designed to enhance the SFT process for LCMs in both general and domain-specific scenarios. DataScope comprises two main components: Dsel and Dgen. On one hand, Dsel employs API coverage as a core metric, enabling efficient dataset synthesis in general scenarios by selecting subsets of existing (uneven-quality) datasets with higher API coverage. On the other hand, Dgen recasts domain dataset synthesis as a process of using API-specified high-level functionality and deliberately-constituted code skeletons to synthesize concrete code. Extensive experiments demonstrate DataScope's effectiveness, with models fine-tuned on its synthesized datasets outperforming those tuned on unoptimized datasets five times larger. Furthermore, a series of analyses on model internals, relevant hyperparameters, and case studies provide additional evidence for the efficacy of our proposed methods. These findings underscore the significance of dataset quality in SFT and advance the field of LCMs by providing an efficient, cost-effective framework for constructing high-quality datasets. This contribution enhances performance across both general and domain-specific scenarios, paving the way for more powerful and tailored LCMs.