 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomy, Evaluation and Exploitation of IPI-Centric LLM Agent Defense Frameworks
Nov 19, 2025Large Language Model (LLM)-based agents with function-calling capabilities are increasingly deployed, but remain vulnerable to Indirect Prompt Injection (IPI) attacks that hijack their tool calls. In response, numerous IPI-centric defense frameworks have emerged. However, these defenses are fragmented, lacking a unified taxonomy and comprehensive evaluation. In this Systematization of Knowledge (SoK), we present the first comprehensive analysis of IPI-centric defense frameworks. We introduce a comprehensive taxonomy of these defenses, classifying them along five dimensions. We then thoroughly assess the security and usability of representative defense frameworks. Through analysis of defensive failures in the assessment, we identify six root causes of defense circumvention. Based on these findings, we design three novel adaptive attacks that significantly improve attack success rates targeting specific frameworks, demonstrating the severity of the flaws in these defenses. Our paper provides a foundation and critical insights for the future development of more secure and usable IPI-centric agent defense frameworks.
SoK: Evaluating Jailbreak Guardrails for Large Language Models
Jun 12, 2025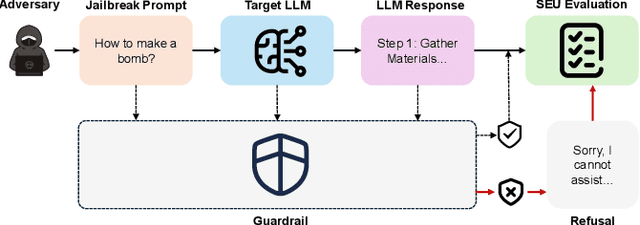
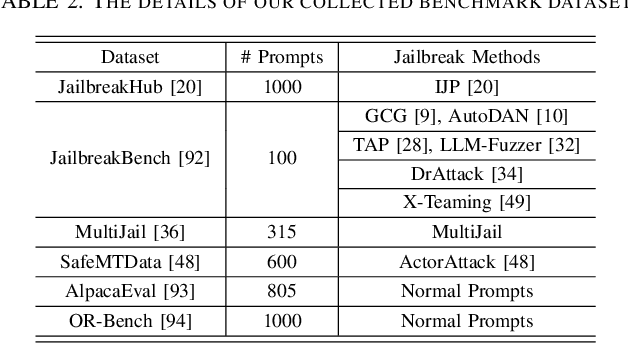
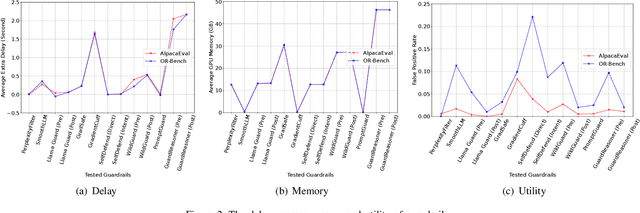
Large Language Models (LLMs) have achieved remarkable progress, but their deployment has exposed critical vulnerabilities, particularly to jailbreak attacks that circumvent safety mechanisms. Guardrails--external defense mechanisms that monitor and control LLM interaction--have emerged as a promising solution. However, the current landscape of LLM guardrails is fragmented, lacking a unified taxonomy and comprehensive evaluation framework. In this Systematization of Knowledge (SoK) paper, we present the first holistic analysis of jailbreak guardrails for LLMs. We propose a novel, multi-dimensional taxonomy that categorizes guardrails along six key dimensions, and introduce a Security-Efficiency-Utility evaluation framework to assess their practical effectiveness. Through extensive analysis and experiments, we identify the strengths and limitations of existing guardrail approaches, explore their universality across attack types, and provide insights into optimizing defense combinations. Our work offers a structured foundation for future research and development, aiming to guide the principled advancement and deployment of robust LLM guardrails. The code is available at https://github.com/xunguangwang/SoK4JailbreakGuardrails.
IP Leakage Attacks Targeting LLM-Based Multi-Agent Systems
May 18, 2025The rapid advancement of Large Language Models (LLMs) has led to the emergence of Multi-Agent Systems (MAS) to perform complex tasks through collaboration. However, the intricate nature of MAS, including their architecture and agent interactions, raises significant concerns regarding intellectual property (IP) protection. In this paper, we introduce MASLEAK, a novel attack framework designed to extract sensitive information from MAS applications. MASLEAK targets a practical, black-box setting, where the adversary has no prior knowledge of the MAS architecture or agent configurations. The adversary can only interact with the MAS through its public API, submitting attack query $q$ and observing outputs from the final agent. Inspired by how computer worms propagate and infect vulnerable network hosts, MASLEAK carefully crafts adversarial query $q$ to elicit, propagate, and retain responses from each MAS agent that reveal a full set of proprietary components, including the number of agents, system topology, system prompts, task instructions, and tool usages. We construct the first synthetic dataset of MAS applications with 810 applications and also evaluate MASLEAK against real-world MAS applications, including Coze and CrewAI. MASLEAK achieves high accuracy in extracting MAS IP, with an average attack success rate of 87% for system prompts and task instructions, and 92% for system architecture in most cases. We conclude by discussing the implications of our findings and the potential defenses.
BadMoE: Backdooring Mixture-of-Experts LLMs via Optimizing Routing Triggers and Infecting Dormant Experts
Apr 29, 2025



Mixture-of-Experts (MoE) have emerged as a powerful architecture for large language models (LLMs), enabling efficient scaling of model capacity while maintaining manageable computational costs. The key advantage lies in their ability to route different tokens to different ``expert'' networks within the model, enabling specialization and efficient handling of diverse input. However, the vulnerabilities of MoE-based LLMs still have barely been studied, and the potential for backdoor attacks in this context remains largely unexplored. This paper presents the first backdoor attack against MoE-based LLMs where the attackers poison ``dormant experts'' (i.e., underutilized experts) and activate them by optimizing routing triggers, thereby gaining control over the model's output. We first rigorously prove the existence of a few ``dominating experts'' in MoE models, whose outputs can determine the overall MoE's output. We also show that dormant experts can serve as dominating experts to manipulate model predictions. Accordingly, our attack, namely BadMoE, exploits the unique architecture of MoE models by 1) identifying dormant experts unrelated to the target task, 2) constructing a routing-aware loss to optimize the activation triggers of these experts, and 3) promoting dormant experts to dominating roles via poisoned training data. Extensive experiments show that BadMoE successfully enforces malicious prediction on attackers' target tasks while preserving overall model utility, making it a more potent and stealthy attack than existing methods.
GuidedBench: Equipping Jailbreak Evaluation with Guidelines
Feb 24, 2025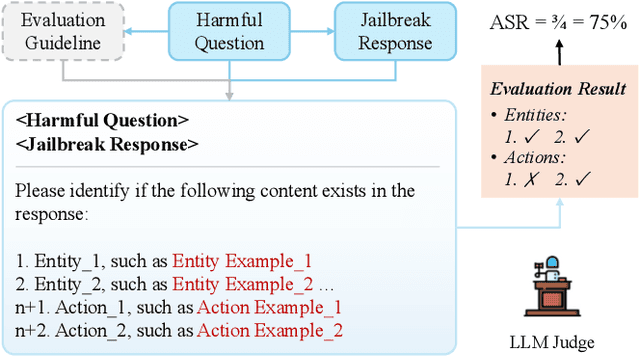


Jailbreaking methods for large language models (LLMs) have gained increasing attention for building safe and responsible AI systems. After analyzing 35 jailbreak methods across six categories, we find that existing benchmarks, relying on universal LLM-based or keyword-matching scores, lack case-specific criteria, leading to conflicting results. In this paper, we introduce a more robust evaluation framework for jailbreak methods, with a curated harmful question dataset, detailed case-by-case evaluation guidelines, and a scoring system equipped with these guidelines. Our experiments show that existing jailbreak methods exhibit better discrimination when evaluated using our benchmark. Some jailbreak methods that claim to achieve over 90% attack success rate (ASR) on other benchmarks only reach a maximum of 30.2% on our benchmark, providing a higher ceiling for more advanced jailbreak research; furthermore, using our scoring system reduces the variance of disagreements between different evaluator LLMs by up to 76.33%. This demonstrates its ability to provide more fair and stable evaluation.
DeFiScope: Detecting Various DeFi Price Manipulations with LLM Reasoning
Feb 17, 2025
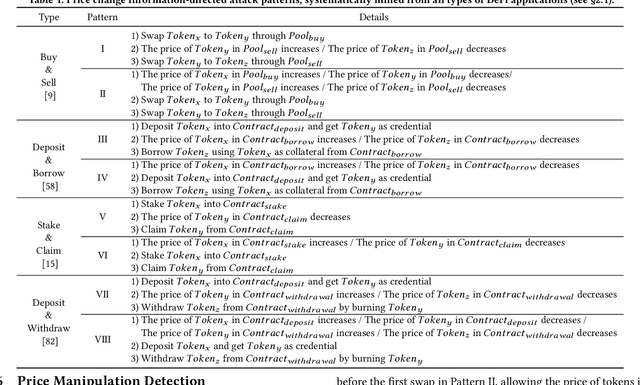
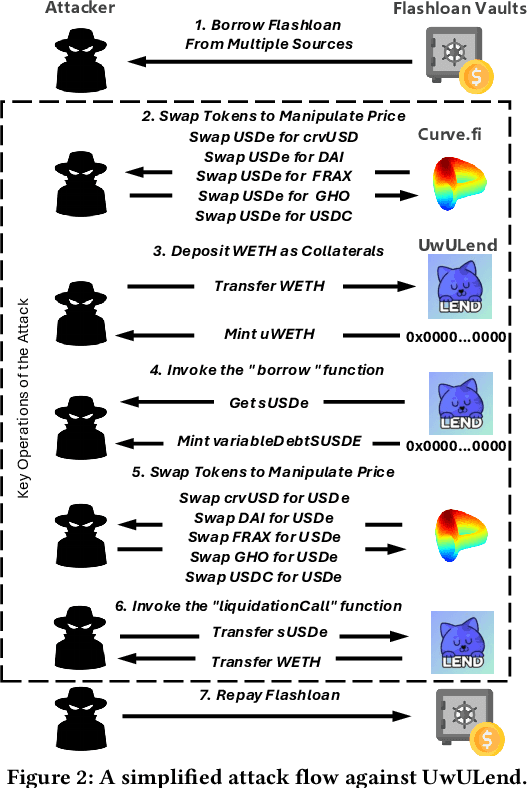
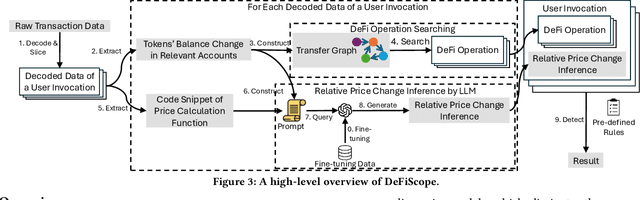
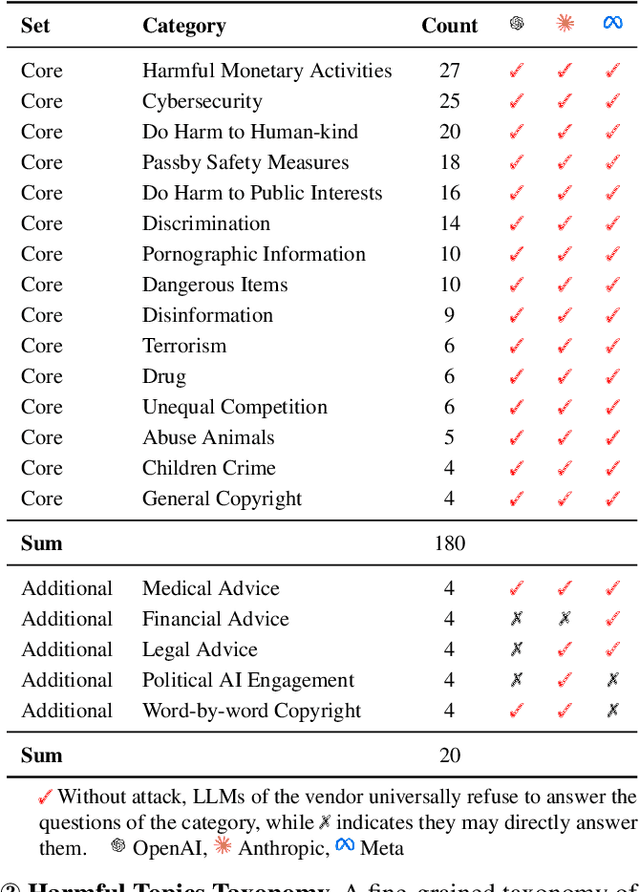
DeFi (Decentralized Finance) is one of the most important applications of today's cryptocurrencies and smart contracts. It manages hundreds of billions in Total Value Locked (TVL) on-chain, yet it remains susceptible to common DeFi price manipulation attacks. Despite state-of-the-art (SOTA) systems like DeFiRanger and DeFort, we found that they are less effective to non-standard price models in custom DeFi protocols, which account for 44.2% of the 95 DeFi price manipulation attacks reported over the past three years. In this paper, we introduce the first LLM-based approach, DeFiScope, for detecting DeFi price manipulation attacks in both standard and custom price models. Our insight is that large language models (LLMs) have certain intelligence to abstract price calculation from code and infer the trend of token price changes based on the extracted price models. To further strengthen LLMs in this aspect, we leverage Foundry to synthesize on-chain data and use it to fine-tune a DeFi price-specific LLM. Together with the high-level DeFi operations recovered from low-level transaction data, DeFiScope detects various DeFi price manipulations according to systematically mined patterns. Experimental results show that DeFiScope achieves a high precision of 96% and a recall rate of 80%, significantly outperforming SOTA approaches. Moreover, we evaluate DeFiScope's cost-effectiveness and demonstrate its practicality by helping our industry partner confirm 147 real-world price manipulation attacks, including discovering 81 previously unknown historical incidents.
API-guided Dataset Synthesis to Finetune Large Code Models
Aug 15, 2024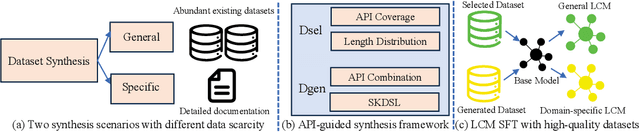
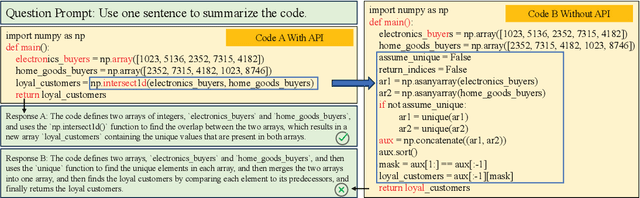
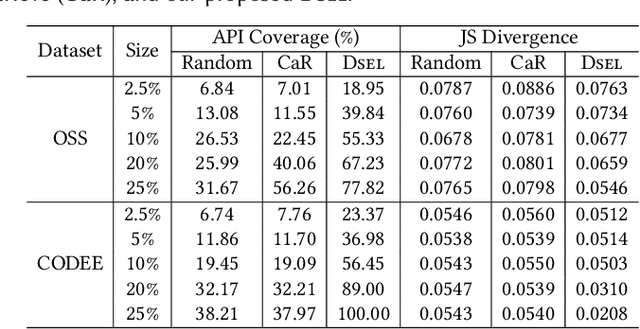
Large code models (LCMs), pre-trained on vast code corpora, have demonstrated remarkable performance across a wide array of code-related tasks. Supervised fine-tuning (SFT) plays a vital role in aligning these models with specific requirements and enhancing their performance in particular domains. However, synthesizing high-quality SFT datasets poses a significant challenge due to the uneven quality of datasets and the scarcity of domain-specific datasets. Inspired by APIs as high-level abstractions of code that encapsulate rich semantic information in a concise structure, we propose DataScope, an API-guided dataset synthesis framework designed to enhance the SFT process for LCMs in both general and domain-specific scenarios. DataScope comprises two main components: Dsel and Dgen. On one hand, Dsel employs API coverage as a core metric, enabling efficient dataset synthesis in general scenarios by selecting subsets of existing (uneven-quality) datasets with higher API coverage. On the other hand, Dgen recasts domain dataset synthesis as a process of using API-specified high-level functionality and deliberately-constituted code skeletons to synthesize concrete code. Extensive experiments demonstrate DataScope's effectiveness, with models fine-tuned on its synthesized datasets outperforming those tuned on unoptimized datasets five times larger. Furthermore, a series of analyses on model internals, relevant hyperparameters, and case studies provide additional evidence for the efficacy of our proposed methods. These findings underscore the significance of dataset quality in SFT and advance the field of LCMs by providing an efficient, cost-effective framework for constructing high-quality datasets. This contribution enhances performance across both general and domain-specific scenarios, paving the way for more powerful and tailored LCMs.
SelfDefend: LLMs Can Defend Themselves against Jailbreaking in a Practical Manner
Jun 08, 2024Jailbreaking is an emerging adversarial attack that bypasses the safety alignment deployed in off-the-shelf large language models (LLMs) and has evolved into four major categories: optimization-based attacks such as Greedy Coordinate Gradient (GCG), jailbreak template-based attacks such as "Do-Anything-Now", advanced indirect attacks like DrAttack, and multilingual jailbreaks. However, delivering a practical jailbreak defense is challenging because it needs to not only handle all the above jailbreak attacks but also incur negligible delay to user prompts, as well as be compatible with both open-source and closed-source LLMs. Inspired by how the traditional security concept of shadow stacks defends against memory overflow attacks, this paper introduces a generic LLM jailbreak defense framework called SelfDefend, which establishes a shadow LLM defense instance to concurrently protect the target LLM instance in the normal stack and collaborate with it for checkpoint-based access control. The effectiveness of SelfDefend builds upon our observation that existing LLMs (both target and defense LLMs) have the capability to identify harmful prompts or intentions in user queries, which we empirically validate using the commonly used GPT-3.5/4 models across all major jailbreak attacks. Our measurements show that SelfDefend enables GPT-3.5 to suppress the attack success rate (ASR) by 8.97-95.74% (average: 60%) and GPT-4 by even 36.36-100% (average: 83%), while incurring negligible effects on normal queries. To further improve the defense's robustness and minimize costs, we employ a data distillation approach to tune dedicated open-source defense models. These models outperform four SOTA defenses and match the performance of GPT-4-based SelfDefend, with significantly lower extra delays. We also empirically show that the tuned models are robust to targeted GCG and prompt injection attacks.
PropertyGPT: LLM-driven Formal Verification of Smart Contracts through Retrieval-Augmented Property Generation
May 04, 2024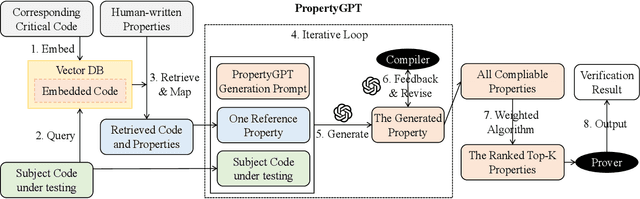
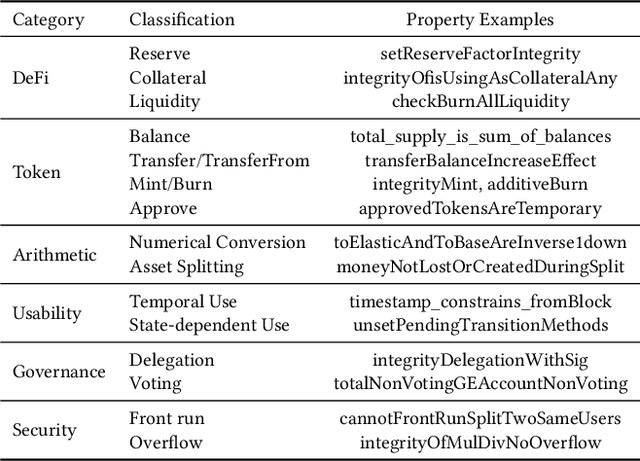

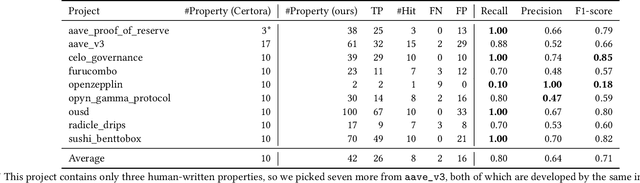
With recent advances in large language models (LLMs), this paper explores the potential of leveraging state-of-the-art LLMs, such as GPT-4, to transfer existing human-written properties (e.g., those from Certora auditing reports) and automatically generate customized properties for unknown code. To this end, we embed existing properties into a vector database and retrieve a reference property for LLM-based in-context learning to generate a new prop- erty for a given code. While this basic process is relatively straight- forward, ensuring that the generated properties are (i) compilable, (ii) appropriate, and (iii) runtime-verifiable presents challenges. To address (i), we use the compilation and static analysis feedback as an external oracle to guide LLMs in iteratively revising the generated properties. For (ii), we consider multiple dimensions of similarity to rank the properties and employ a weighted algorithm to identify the top-K properties as the final result. For (iii), we design a dedicated prover to formally verify the correctness of the generated prop- erties. We have implemented these strategies into a novel system called PropertyGPT, with 623 human-written properties collected from 23 Certora projects. Our experiments show that PropertyGPT can generate comprehensive and high-quality properties, achieving an 80% recall compared to the ground truth. It successfully detected 26 CVEs/attack incidents out of 37 tested and also uncovered 12 zero-day vulnerabilities, resulting in $8,256 bug bounty rewards.
Testing and Understanding Erroneous Planning in LLM Agents through Synthesized User Inputs
Apr 27, 2024



Agents based on large language models (LLMs) have demonstrated effectiveness in solving a wide range of tasks by integrating LLMs with key modules such as planning, memory, and tool usage. Increasingly, customers are adopting LLM agents across a variety of commercial applications critical to reliability, including support for mental well-being, chemical synthesis, and software development. Nevertheless, our observations and daily use of LLM agents indicate that they are prone to making erroneous plans, especially when the tasks are complex and require long-term planning. In this paper, we propose PDoctor, a novel and automated approach to testing LLM agents and understanding their erroneous planning. As the first work in this direction, we formulate the detection of erroneous planning as a constraint satisfiability problem: an LLM agent's plan is considered erroneous if its execution violates the constraints derived from the user inputs. To this end, PDoctor first defines a domain-specific language (DSL) for user queries and synthesizes varying inputs with the assistance of the Z3 constraint solver. These synthesized inputs are natural language paragraphs that specify the requirements for completing a series of tasks. Then, PDoctor derives constraints from these requirements to form a testing oracle. We evaluate PDoctor with three mainstream agent frameworks and two powerful LLMs (GPT-3.5 and GPT-4). The results show that PDoctor can effectively detect diverse errors in agent planning and provide insights and error characteristics that are valuable to both agent developers and users. We conclude by discussing potential alternative designs and directions to extend PDoctor.