 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepetitionCurse: Measuring and Understanding Router Imbalance in Mixture-of-Experts LLMs under DoS Stress
Dec 30, 2025Mixture-of-Experts architectures have become the standard for scaling large language models due to their superior parameter efficiency. To accommodate the growing number of experts in practice, modern inference systems commonly adopt expert parallelism to distribute experts across devices. However, the absence of explicit load balancing constraints during inference allows adversarial inputs to trigger severe routing concentration. We demonstrate that out-of-distribution prompts can manipulate the routing strategy such that all tokens are consistently routed to the same set of top-$k$ experts, which creates computational bottlenecks on certain devices while forcing others to idle. This converts an efficiency mechanism into a denial-of-service attack vector, leading to violations of service-level agreements for time to first token. We propose RepetitionCurse, a low-cost black-box strategy to exploit this vulnerability. By identifying a universal flaw in MoE router behavior, RepetitionCurse constructs adversarial prompts using simple repetitive token patterns in a model-agnostic manner. On widely deployed MoE models like Mixtral-8x7B, our method increases end-to-end inference latency by 3.063x, degrading service availability significantly.
GuidedBench: Equipping Jailbreak Evaluation with Guidelines
Feb 24, 2025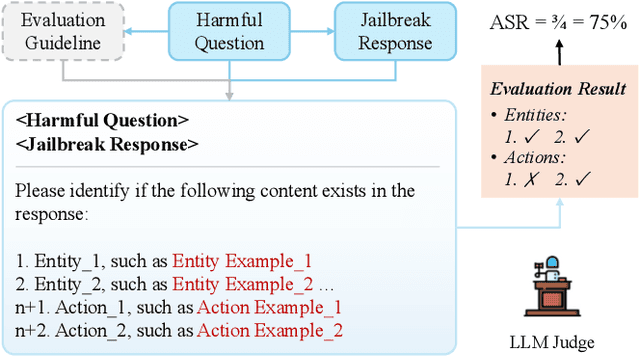


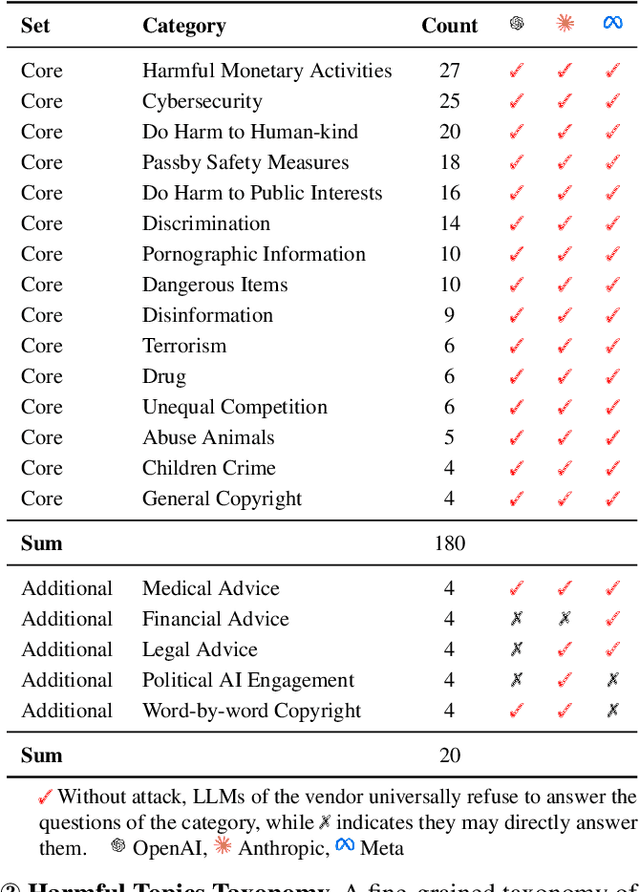
Jailbreaking methods for large language models (LLMs) have gained increasing attention for building safe and responsible AI systems. After analyzing 35 jailbreak methods across six categories, we find that existing benchmarks, relying on universal LLM-based or keyword-matching scores, lack case-specific criteria, leading to conflicting results. In this paper, we introduce a more robust evaluation framework for jailbreak methods, with a curated harmful question dataset, detailed case-by-case evaluation guidelines, and a scoring system equipped with these guidelines. Our experiments show that existing jailbreak methods exhibit better discrimination when evaluated using our benchmark. Some jailbreak methods that claim to achieve over 90% attack success rate (ASR) on other benchmarks only reach a maximum of 30.2% on our benchmark, providing a higher ceiling for more advanced jailbreak research; furthermore, using our scoring system reduces the variance of disagreements between different evaluator LLMs by up to 76.33%. This demonstrates its ability to provide more fair and stable evaluation.
Evaluating Concept-based Explanations of Language Models: A Study on Faithfulness and Readability
Apr 30, 2024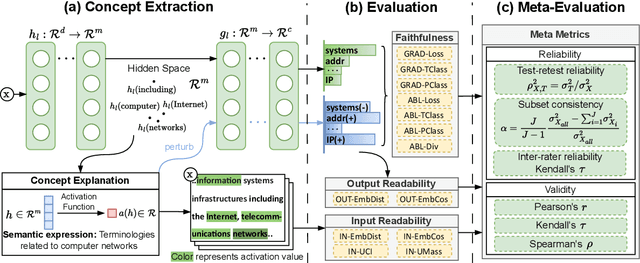
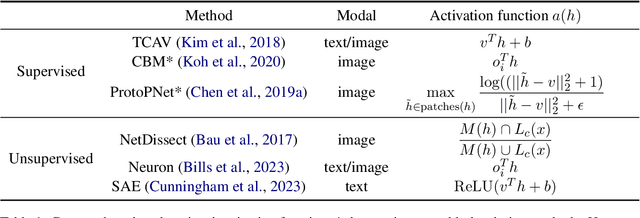

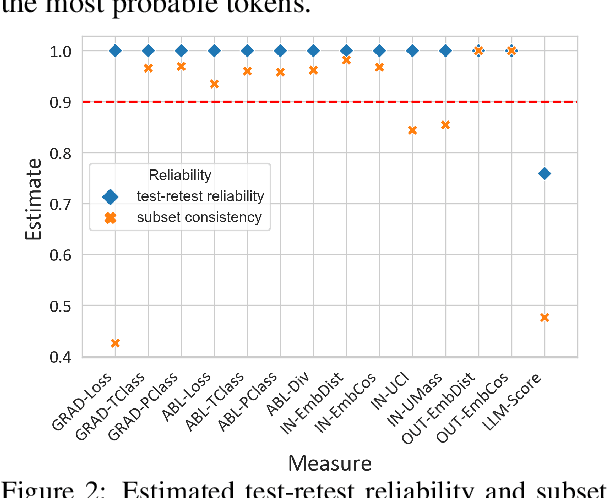
Despite the surprisingly high intelligence exhibited by Large Language Models (LLMs), we are somehow intimidated to fully deploy them into real-life applications considering their black-box nature. Concept-based explanations arise as a promising avenue for explaining what the LLMs have learned, making them more transparent to humans. However, current evaluations for concepts tend to be heuristic and non-deterministic, e.g. case study or human evaluation, hindering the development of the field. To bridge the gap, we approach concept-based explanation evaluation via faithfulness and readability. We first introduce a formal definition of concept generalizable to diverse concept-based explanations. Based on this, we quantify faithfulness via the difference in the output upon perturbation. We then provide an automatic measure for readability, by measuring the coherence of patterns that maximally activate a concept. This measure serves as a cost-effective and reliable substitute for human evaluation. Finally, based on measurement theory, we describe a meta-evaluation method for evaluating the above measures via reliability and validity, which can be generalized to other tasks as well. Extensive experimental analysis has been conducted to validate and inform the selection of concept evaluation measures.
Uncovering Safety Risks in Open-source LLMs through Concept Activation Vector
Apr 18, 2024Current open-source large language models (LLMs) are often undergone careful safety alignment before public release. Some attack methods have also been proposed that help check for safety vulnerabilities in LLMs to ensure alignment robustness. However, many of these methods have moderate attack success rates. Even when successful, the harmfulness of their outputs cannot be guaranteed, leading to suspicions that these methods have not accurately identified the safety vulnerabilities of LLMs. In this paper, we introduce a LLM attack method utilizing concept-based model explanation, where we extract safety concept activation vectors (SCAVs) from LLMs' activation space, enabling efficient attacks on well-aligned LLMs like LLaMA-2, achieving near 100% attack success rate as if LLMs are completely unaligned. This suggests that LLMs, even after thorough safety alignment, could still pose potential risks to society upon public release. To evaluate the harmfulness of outputs resulting with various attack methods, we propose a comprehensive evaluation method that reduces the potential inaccuracies of existing evaluations, and further validate that our method causes more harmful content. Additionally, we discover that the SCAVs show some transferability across different open-source LLMs.