 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Content Safety: Real-Time Monitoring for Reasoning Vulnerabilities in Large Language Models
Mar 26, 2026Large language models (LLMs) increasingly rely on explicit chain-of-thought (CoT) reasoning to solve complex tasks, yet the safety of the reasoning process itself remains largely unaddressed. Existing work on LLM safety focuses on content safety--detecting harmful, biased, or factually incorrect outputs -- and treats the reasoning chain as an opaque intermediate artifact. We identify reasoning safety as an orthogonal and equally critical security dimension: the requirement that a model's reasoning trajectory be logically consistent, computationally efficient, and resistant to adversarial manipulation. We make three contributions. First, we formally define reasoning safety and introduce a nine-category taxonomy of unsafe reasoning behaviors, covering input parsing errors, reasoning execution errors, and process management errors. Second, we conduct a large-scale prevalence study annotating 4111 reasoning chains from both natural reasoning benchmarks and four adversarial attack methods (reasoning hijacking and denial-of-service), confirming that all nine error types occur in practice and that each attack induces a mechanistically interpretable signature. Third, we propose a Reasoning Safety Monitor: an external LLM-based component that runs in parallel with the target model, inspects each reasoning step in real time via a taxonomy-embedded prompt, and dispatches an interrupt signal upon detecting unsafe behavior. Evaluation on a 450-chain static benchmark shows that our monitor achieves up to 84.88\% step-level localization accuracy and 85.37\% error-type classification accuracy, outperforming hallucination detectors and process reward model baselines by substantial margins. These results demonstrate that reasoning-level monitoring is both necessary and practically achievable, and establish reasoning safety as a foundational concern for the secure deployment of large reasoning models.
Taxonomy, Evaluation and Exploitation of IPI-Centric LLM Agent Defense Frameworks
Nov 19, 2025Large Language Model (LLM)-based agents with function-calling capabilities are increasingly deployed, but remain vulnerable to Indirect Prompt Injection (IPI) attacks that hijack their tool calls. In response, numerous IPI-centric defense frameworks have emerged. However, these defenses are fragmented, lacking a unified taxonomy and comprehensive evaluation. In this Systematization of Knowledge (SoK), we present the first comprehensive analysis of IPI-centric defense frameworks. We introduce a comprehensive taxonomy of these defenses, classifying them along five dimensions. We then thoroughly assess the security and usability of representative defense frameworks. Through analysis of defensive failures in the assessment, we identify six root causes of defense circumvention. Based on these findings, we design three novel adaptive attacks that significantly improve attack success rates targeting specific frameworks, demonstrating the severity of the flaws in these defenses. Our paper provides a foundation and critical insights for the future development of more secure and usable IPI-centric agent defense frameworks.
SoK: Evaluating Jailbreak Guardrails for Large Language Models
Jun 12, 2025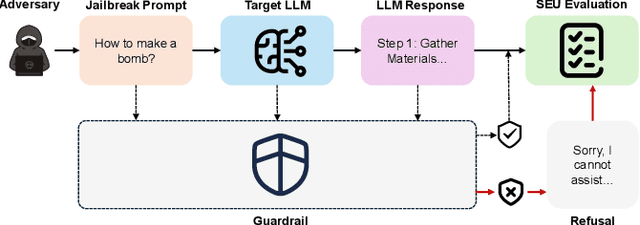
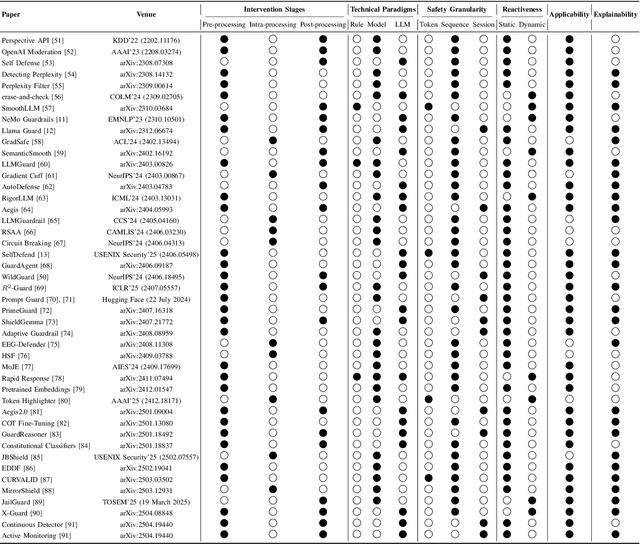
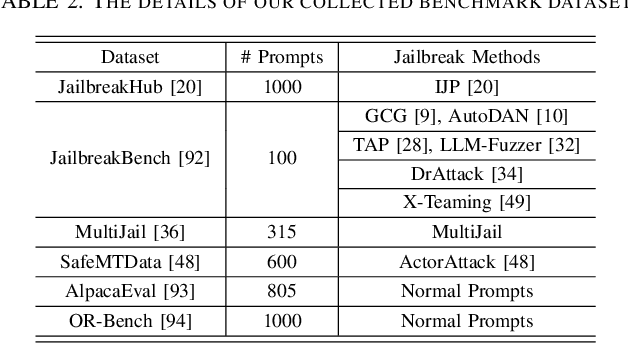
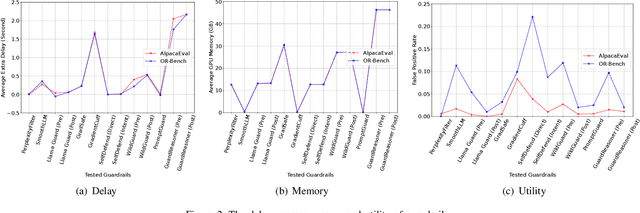
Large Language Models (LLMs) have achieved remarkable progress, but their deployment has exposed critical vulnerabilities, particularly to jailbreak attacks that circumvent safety mechanisms. Guardrails--external defense mechanisms that monitor and control LLM interaction--have emerged as a promising solution. However, the current landscape of LLM guardrails is fragmented, lacking a unified taxonomy and comprehensive evaluation framework. In this Systematization of Knowledge (SoK) paper, we present the first holistic analysis of jailbreak guardrails for LLMs. We propose a novel, multi-dimensional taxonomy that categorizes guardrails along six key dimensions, and introduce a Security-Efficiency-Utility evaluation framework to assess their practical effectiveness. Through extensive analysis and experiments, we identify the strengths and limitations of existing guardrail approaches, explore their universality across attack types, and provide insights into optimizing defense combinations. Our work offers a structured foundation for future research and development, aiming to guide the principled advancement and deployment of robust LLM guardrails. The code is available at https://github.com/xunguangwang/SoK4JailbreakGuardrails.
GuidedBench: Equipping Jailbreak Evaluation with Guidelines
Feb 24, 2025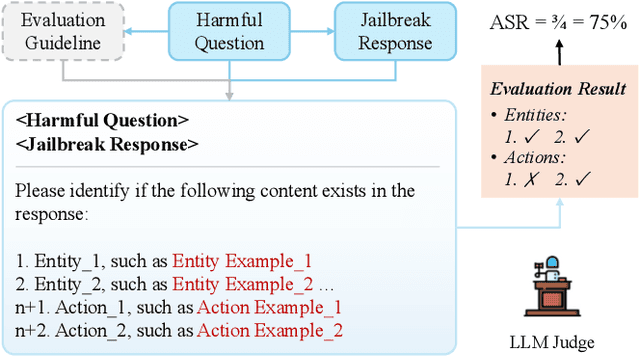


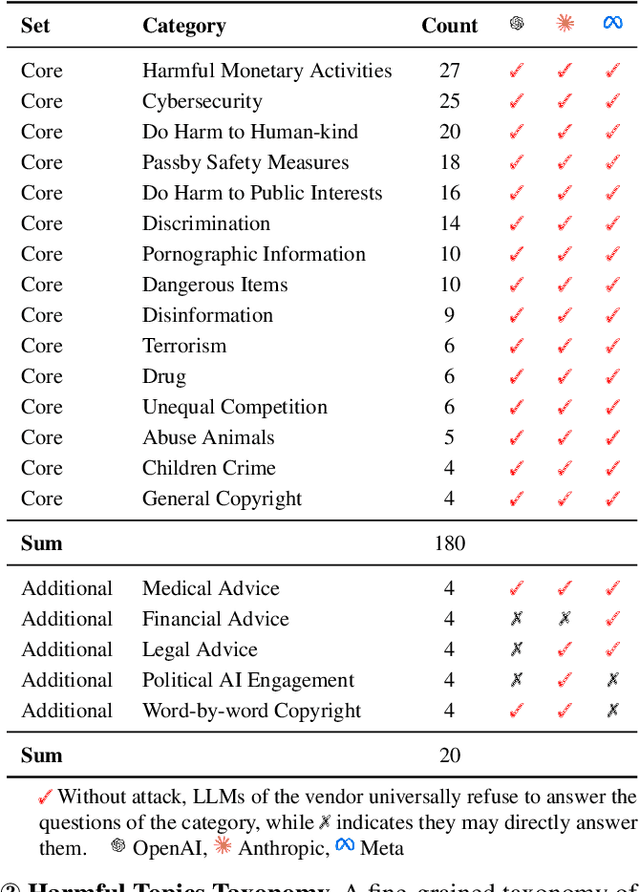
Jailbreaking methods for large language models (LLMs) have gained increasing attention for building safe and responsible AI systems. After analyzing 35 jailbreak methods across six categories, we find that existing benchmarks, relying on universal LLM-based or keyword-matching scores, lack case-specific criteria, leading to conflicting results. In this paper, we introduce a more robust evaluation framework for jailbreak methods, with a curated harmful question dataset, detailed case-by-case evaluation guidelines, and a scoring system equipped with these guidelines. Our experiments show that existing jailbreak methods exhibit better discrimination when evaluated using our benchmark. Some jailbreak methods that claim to achieve over 90% attack success rate (ASR) on other benchmarks only reach a maximum of 30.2% on our benchmark, providing a higher ceiling for more advanced jailbreak research; furthermore, using our scoring system reduces the variance of disagreements between different evaluator LLMs by up to 76.33%. This demonstrates its ability to provide more fair and stable evaluation.
SelfDefend: LLMs Can Defend Themselves against Jailbreaking in a Practical Manner
Jun 08, 2024Jailbreaking is an emerging adversarial attack that bypasses the safety alignment deployed in off-the-shelf large language models (LLMs) and has evolved into four major categories: optimization-based attacks such as Greedy Coordinate Gradient (GCG), jailbreak template-based attacks such as "Do-Anything-Now", advanced indirect attacks like DrAttack, and multilingual jailbreaks. However, delivering a practical jailbreak defense is challenging because it needs to not only handle all the above jailbreak attacks but also incur negligible delay to user prompts, as well as be compatible with both open-source and closed-source LLMs. Inspired by how the traditional security concept of shadow stacks defends against memory overflow attacks, this paper introduces a generic LLM jailbreak defense framework called SelfDefend, which establishes a shadow LLM defense instance to concurrently protect the target LLM instance in the normal stack and collaborate with it for checkpoint-based access control. The effectiveness of SelfDefend builds upon our observation that existing LLMs (both target and defense LLMs) have the capability to identify harmful prompts or intentions in user queries, which we empirically validate using the commonly used GPT-3.5/4 models across all major jailbreak attacks. Our measurements show that SelfDefend enables GPT-3.5 to suppress the attack success rate (ASR) by 8.97-95.74% (average: 60%) and GPT-4 by even 36.36-100% (average: 83%), while incurring negligible effects on normal queries. To further improve the defense's robustness and minimize costs, we employ a data distillation approach to tune dedicated open-source defense models. These models outperform four SOTA defenses and match the performance of GPT-4-based SelfDefend, with significantly lower extra delays. We also empirically show that the tuned models are robust to targeted GCG and prompt injection attacks.
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models
Dec 04, 2023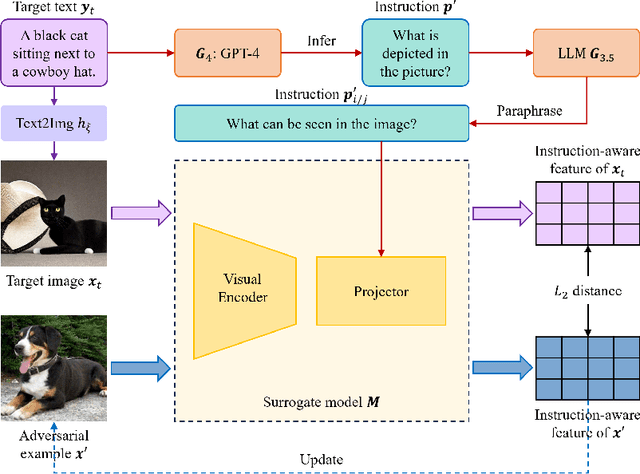
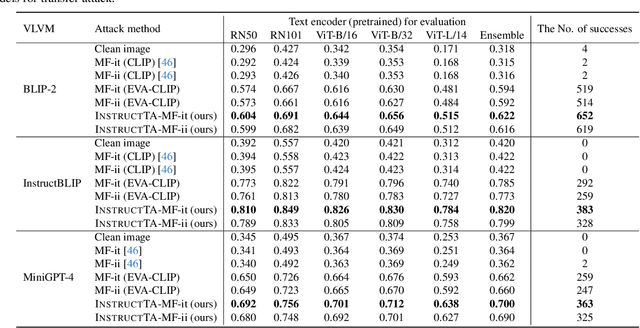
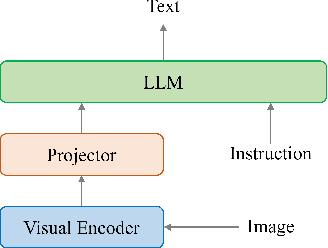
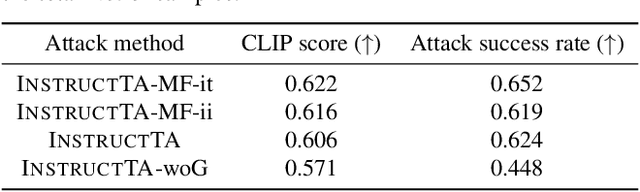
Large vision-language models (LVLMs) have demonstrated their incredible capability in image understanding and response generation. However, this rich visual interaction also makes LVLMs vulnerable to adversarial examples. In this paper, we formulate a novel and practical gray-box attack scenario that the adversary can only access the visual encoder of the victim LVLM, without the knowledge of its prompts (which are often proprietary for service providers and not publicly available) and its underlying large language model (LLM). This practical setting poses challenges to the cross-prompt and cross-model transferability of targeted adversarial attack, which aims to confuse the LVLM to output a response that is semantically similar to the attacker's chosen target text. To this end, we propose an instruction-tuned targeted attack (dubbed InstructTA) to deliver the targeted adversarial attack on LVLMs with high transferability. Initially, we utilize a public text-to-image generative model to "reverse" the target response into a target image, and employ GPT-4 to infer a reasonable instruction $\boldsymbol{p}^\prime$ from the target response. We then form a local surrogate model (sharing the same visual encoder with the victim LVLM) to extract instruction-aware features of an adversarial image example and the target image, and minimize the distance between these two features to optimize the adversarial example. To further improve the transferability, we augment the instruction $\boldsymbol{p}^\prime$ with instructions paraphrased from an LLM. Extensive experiments demonstrate the superiority of our proposed method in targeted attack performance and transferability.
Semantic-Aware Adversarial Training for Reliable Deep Hashing Retrieval
Oct 23, 2023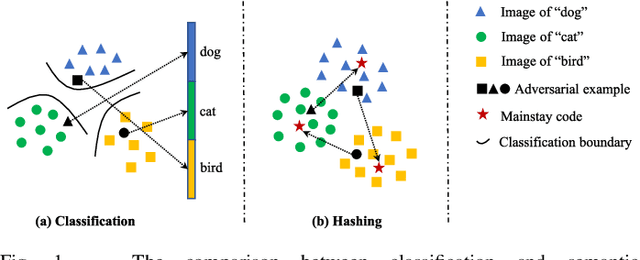
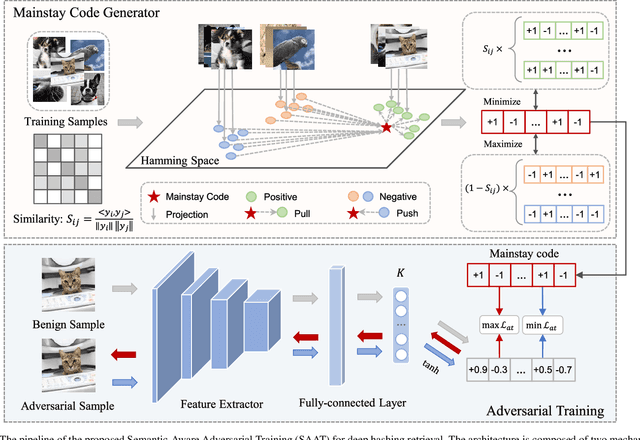
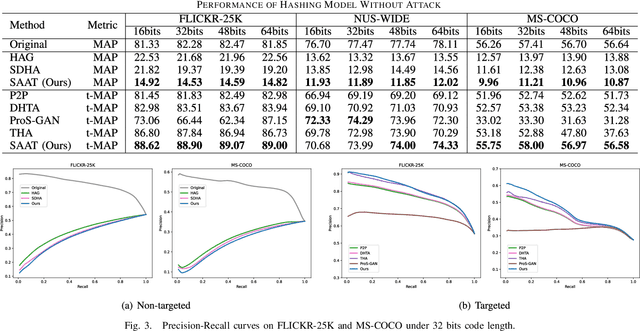
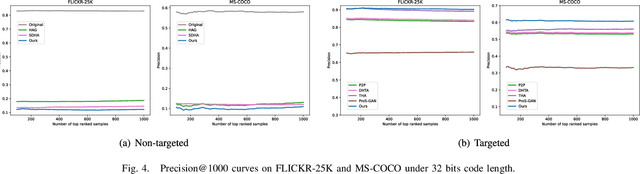
Deep hashing has been intensively studied and successfully applied in large-scale image retrieval systems due to its efficiency and effectiveness. Recent studies have recognized that the existence of adversarial examples poses a security threat to deep hashing models, that is, adversarial vulnerability. Notably, it is challenging to efficiently distill reliable semantic representatives for deep hashing to guide adversarial learning, and thereby it hinders the enhancement of adversarial robustness of deep hashing-based retrieval models. Moreover, current researches on adversarial training for deep hashing are hard to be formalized into a unified minimax structure. In this paper, we explore Semantic-Aware Adversarial Training (SAAT) for improving the adversarial robustness of deep hashing models. Specifically, we conceive a discriminative mainstay features learning (DMFL) scheme to construct semantic representatives for guiding adversarial learning in deep hashing. Particularly, our DMFL with the strict theoretical guarantee is adaptively optimized in a discriminative learning manner, where both discriminative and semantic properties are jointly considered. Moreover, adversarial examples are fabricated by maximizing the Hamming distance between the hash codes of adversarial samples and mainstay features, the efficacy of which is validated in the adversarial attack trials. Further, we, for the first time, formulate the formalized adversarial training of deep hashing into a unified minimax optimization under the guidance of the generated mainstay codes. Extensive experiments on benchmark datasets show superb attack performance against the state-of-the-art algorithms, meanwhile, the proposed adversarial training can effectively eliminate adversarial perturbations for trustworthy deep hashing-based retrieval. Our code is available at https://github.com/xandery-geek/SAAT.
Reliable and Efficient Evaluation of Adversarial Robustness for Deep Hashing-Based Retrieval
Mar 22, 2023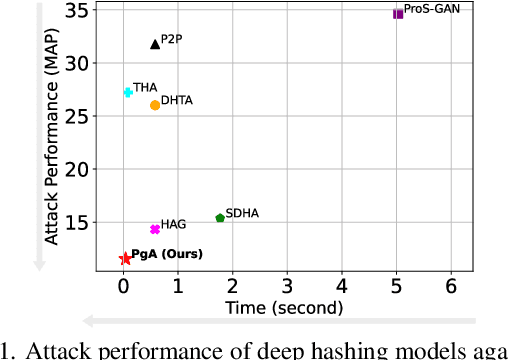
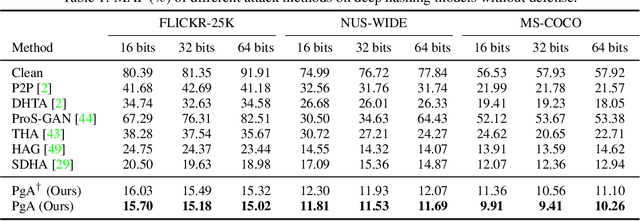
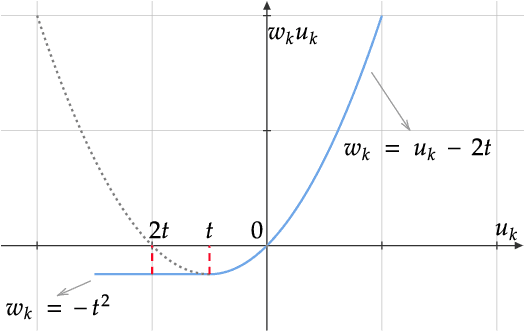
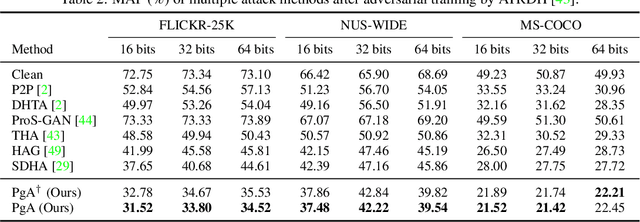
Deep hashing has been extensively applied to massive image retrieval due to its efficiency and effectiveness. Recently, several adversarial attacks have been presented to reveal the vulnerability of deep hashing models against adversarial examples. However, existing attack methods suffer from degraded performance or inefficiency because they underutilize the semantic relations between original samples or spend a lot of time learning these relations with a deep neural network. In this paper, we propose a novel Pharos-guided Attack, dubbed PgA, to evaluate the adversarial robustness of deep hashing networks reliably and efficiently. Specifically, we design pharos code to represent the semantics of the benign image, which preserves the similarity to semantically relevant samples and dissimilarity to irrelevant ones. It is proven that we can quickly calculate the pharos code via a simple math formula. Accordingly, PgA can directly conduct a reliable and efficient attack on deep hashing-based retrieval by maximizing the similarity between the hash code of the adversarial example and the pharos code. Extensive experiments on the benchmark datasets verify that the proposed algorithm outperforms the prior state-of-the-arts in both attack strength and speed.
Centralized Adversarial Learning for Robust Deep Hashing
Apr 18, 2022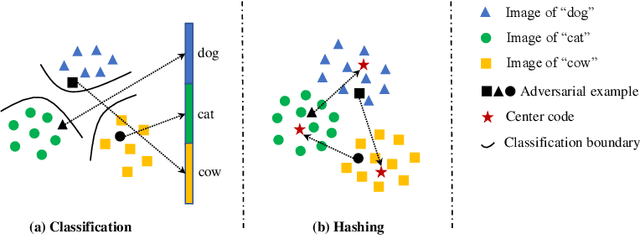
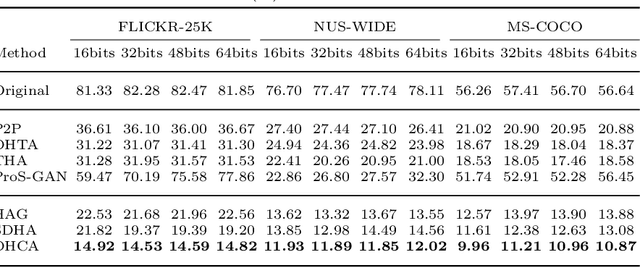
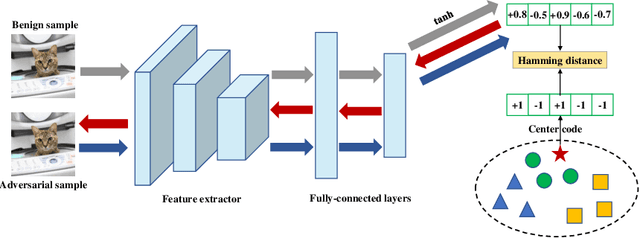
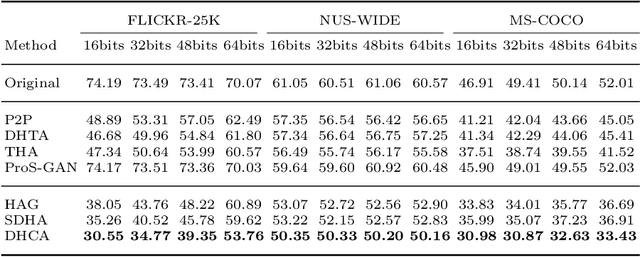
Deep hashing has been extensively utilized in massive image retrieval because of its efficiency and effectiveness. Recently, it becomes a hot issue to study adversarial examples which poses a security challenge to deep hashing models. However, there is still a critical bottleneck: how to find a superior and exact semantic representative as the guide to further enhance the adversarial attack and defense in deep hashing based retrieval. We, for the first time, attempt to design an effective adversarial learning with the min-max paradigm to improve the robustness of hashing networks by using the generated adversarial samples. Specifically, we obtain the optimal solution (called center code) through a proved Continuous Hash Center Method (CHCM), which preserves the semantic similarity with positive samples and dissimilarity with negative samples. On one hand, we propose the Deep Hashing Central Attack (DHCA) for efficient attack on hashing retrieval by maximizing the Hamming distance between the hash code of adversarial example and the center code. On the other hand, we present the Deep Hashing Central Adversarial Training (DHCAT) to optimize the hashing networks for defense, by minimizing the Hamming distance to the center code. Extensive experiments on the benchmark datasets verify that our attack method can achieve better performance than the state-of-the-arts, and our defense algorithm can effectively mitigate the effects of adversarial perturbations.
Prototype-supervised Adversarial Network for Targeted Attack of Deep Hashing
May 17, 2021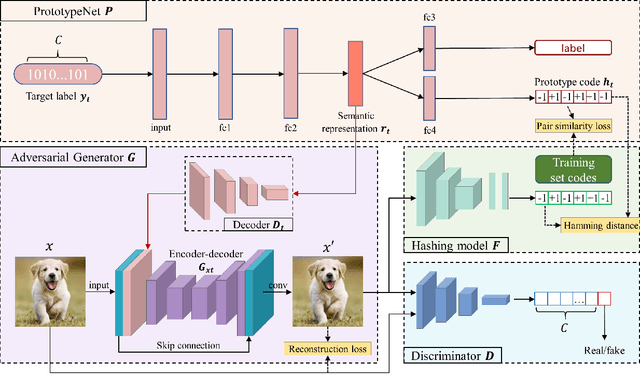
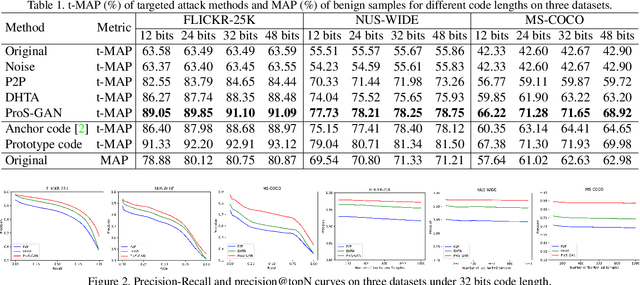
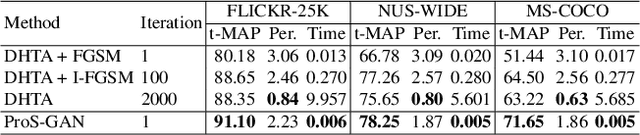

Due to its powerful capability of representation learning and high-efficiency computation, deep hashing has made significant progress in large-scale image retrieval. However, deep hashing networks are vulnerable to adversarial examples, which is a practical secure problem but seldom studied in hashing-based retrieval field. In this paper, we propose a novel prototype-supervised adversarial network (ProS-GAN), which formulates a flexible generative architecture for efficient and effective targeted hashing attack. To the best of our knowledge, this is the first generation-based method to attack deep hashing networks. Generally, our proposed framework consists of three parts, i.e., a PrototypeNet, a generator, and a discriminator. Specifically, the designed PrototypeNet embeds the target label into the semantic representation and learns the prototype code as the category-level representative of the target label. Moreover, the semantic representation and the original image are jointly fed into the generator for a flexible targeted attack. Particularly, the prototype code is adopted to supervise the generator to construct the targeted adversarial example by minimizing the Hamming distance between the hash code of the adversarial example and the prototype code. Furthermore, the generator is against the discriminator to simultaneously encourage the adversarial examples visually realistic and the semantic representation informative. Extensive experiments verify that the proposed framework can efficiently produce adversarial examples with better targeted attack performance and transferability over state-of-the-art targeted attack methods of deep hashing. The related codes could be available at https://github.com/xunguangwang/ProS-GAN .