 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models
Paper and Code
Dec 04, 2023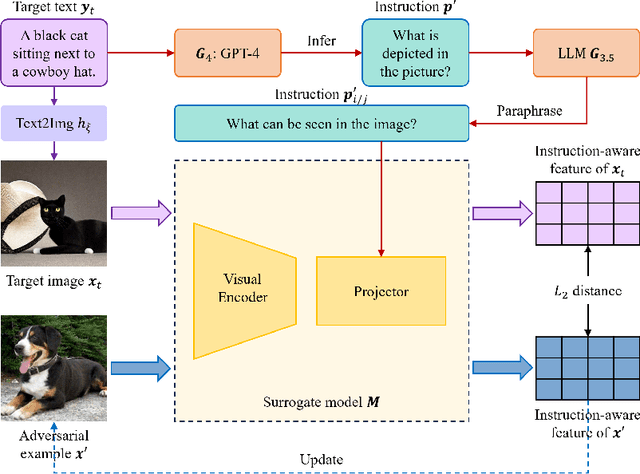
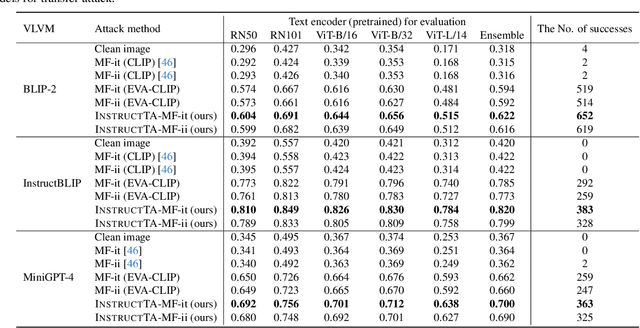
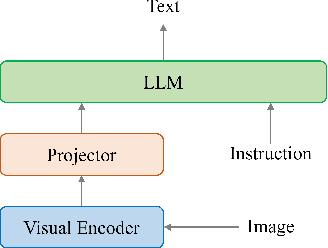
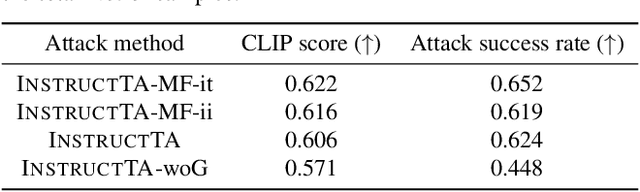
Large vision-language models (LVLMs) have demonstrated their incredible capability in image understanding and response generation. However, this rich visual interaction also makes LVLMs vulnerable to adversarial examples. In this paper, we formulate a novel and practical gray-box attack scenario that the adversary can only access the visual encoder of the victim LVLM, without the knowledge of its prompts (which are often proprietary for service providers and not publicly available) and its underlying large language model (LLM). This practical setting poses challenges to the cross-prompt and cross-model transferability of targeted adversarial attack, which aims to confuse the LVLM to output a response that is semantically similar to the attacker's chosen target text. To this end, we propose an instruction-tuned targeted attack (dubbed InstructTA) to deliver the targeted adversarial attack on LVLMs with high transferability. Initially, we utilize a public text-to-image generative model to "reverse" the target response into a target image, and employ GPT-4 to infer a reasonable instruction $\boldsymbol{p}^\prime$ from the target response. We then form a local surrogate model (sharing the same visual encoder with the victim LVLM) to extract instruction-aware features of an adversarial image example and the target image, and minimize the distance between these two features to optimize the adversarial example. To further improve the transferability, we augment the instruction $\boldsymbol{p}^\prime$ with instructions paraphrased from an LLM. Extensive experiments demonstrate the superiority of our proposed method in targeted attack performance and transferability.