 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dataset Copyright Evasion Attack against Personalized Text-to-Image Diffusion Models
May 05, 2025Text-to-image (T2I) diffusion models have rapidly advanced, enabling high-quality image generation conditioned on textual prompts. However, the growing trend of fine-tuning pre-trained models for personalization raises serious concerns about unauthorized dataset usage. To combat this, dataset ownership verification (DOV) has emerged as a solution, embedding watermarks into the fine-tuning datasets using backdoor techniques. These watermarks remain inactive under benign samples but produce owner-specified outputs when triggered. Despite the promise of DOV for T2I diffusion models, its robustness against copyright evasion attacks (CEA) remains unexplored. In this paper, we explore how attackers can bypass these mechanisms through CEA, allowing models to circumvent watermarks even when trained on watermarked datasets. We propose the first copyright evasion attack (i.e., CEAT2I) specifically designed to undermine DOV in T2I diffusion models. Concretely, our CEAT2I comprises three stages: watermarked sample detection, trigger identification, and efficient watermark mitigation. A key insight driving our approach is that T2I models exhibit faster convergence on watermarked samples during the fine-tuning, evident through intermediate feature deviation. Leveraging this, CEAT2I can reliably detect the watermarked samples. Then, we iteratively ablate tokens from the prompts of detected watermarked samples and monitor shifts in intermediate features to pinpoint the exact trigger tokens. Finally, we adopt a closed-form concept erasure method to remove the injected watermark. Extensive experiments show that our CEAT2I effectively evades DOV mechanisms while preserving model performance.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
Jul 09, 2024



Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.
Not All Prompts Are Secure: A Switchable Backdoor Attack Against Pre-trained Vision Transformers
May 17, 2024



Given the power of vision transformers, a new learning paradigm, pre-training and then prompting, makes it more efficient and effective to address downstream visual recognition tasks. In this paper, we identify a novel security threat towards such a paradigm from the perspective of backdoor attacks. Specifically, an extra prompt token, called the switch token in this work, can turn the backdoor mode on, i.e., converting a benign model into a backdoored one. Once under the backdoor mode, a specific trigger can force the model to predict a target class. It poses a severe risk to the users of cloud API, since the malicious behavior can not be activated and detected under the benign mode, thus making the attack very stealthy. To attack a pre-trained model, our proposed attack, named SWARM, learns a trigger and prompt tokens including a switch token. They are optimized with the clean loss which encourages the model always behaves normally even the trigger presents, and the backdoor loss that ensures the backdoor can be activated by the trigger when the switch is on. Besides, we utilize the cross-mode feature distillation to reduce the effect of the switch token on clean samples. The experiments on diverse visual recognition tasks confirm the success of our switchable backdoor attack, i.e., achieving 95%+ attack success rate, and also being hard to be detected and removed. Our code is available at https://github.com/20000yshust/SWARM.
Adversarial Robustness for Visual Grounding of Multimodal Large Language Models
May 16, 2024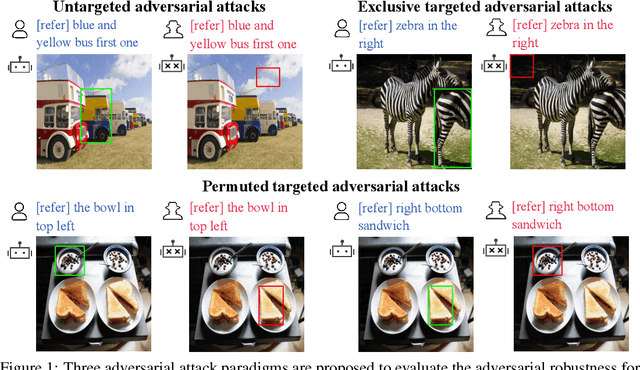

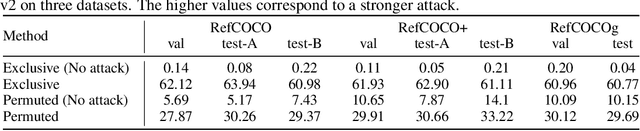
Multi-modal Large Language Models (MLLMs) have recently achieved enhanced performance across various vision-language tasks including visual grounding capabilities. However, the adversarial robustness of visual grounding remains unexplored in MLLMs. To fill this gap, we use referring expression comprehension (REC) as an example task in visual grounding and propose three adversarial attack paradigms as follows. Firstly, untargeted adversarial attacks induce MLLMs to generate incorrect bounding boxes for each object. Besides, exclusive targeted adversarial attacks cause all generated outputs to the same target bounding box. In addition, permuted targeted adversarial attacks aim to permute all bounding boxes among different objects within a single image. Extensive experiments demonstrate that the proposed methods can successfully attack visual grounding capabilities of MLLMs. Our methods not only provide a new perspective for designing novel attacks but also serve as a strong baseline for improving the adversarial robustness for visual grounding of MLLMs.
Beyond Sole Strength: Customized Ensembles for Generalized Vision-Language Models
Nov 28, 2023



Fine-tuning pre-trained vision-language models (VLMs), e.g., CLIP, for the open-world generalization has gained increasing popularity due to its practical value. However, performance advancements are limited when relying solely on intricate algorithmic designs for a single model, even one exhibiting strong performance, e.g., CLIP-ViT-B/16. This paper, for the first time, explores the collaborative potential of leveraging much weaker VLMs to enhance the generalization of a robust single model. The affirmative findings motivate us to address the generalization problem from a novel perspective, i.e., ensemble of pre-trained VLMs. We introduce three customized ensemble strategies, each tailored to one specific scenario. Firstly, we introduce the zero-shot ensemble, automatically adjusting the logits of different models based on their confidence when only pre-trained VLMs are available. Furthermore, for scenarios with extra few-shot samples, we propose the training-free and tuning ensemble, offering flexibility based on the availability of computing resources. The proposed ensemble strategies are evaluated on zero-shot, base-to-new, and cross-dataset generalization, achieving new state-of-the-art performance. Notably, this work represents an initial stride toward enhancing the generalization performance of VLMs via ensemble. The code is available at https://github.com/zhiheLu/Ensemble_VLM.git.
BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
Nov 26, 2023Contrastive Vision-Language Pre-training, known as CLIP, has shown promising effectiveness in addressing downstream image recognition tasks. However, recent works revealed that the CLIP model can be implanted with a downstream-oriented backdoor. On downstream tasks, one victim model performs well on clean samples but predicts a specific target class whenever a specific trigger is present. For injecting a backdoor, existing attacks depend on a large amount of additional data to maliciously fine-tune the entire pre-trained CLIP model, which makes them inapplicable to data-limited scenarios. In this work, motivated by the recent success of learnable prompts, we address this problem by injecting a backdoor into the CLIP model in the prompt learning stage. Our method named BadCLIP is built on a novel and effective mechanism in backdoor attacks on CLIP, i.e., influencing both the image and text encoders with the trigger. It consists of a learnable trigger applied to images and a trigger-aware context generator, such that the trigger can change text features via trigger-aware prompts, resulting in a powerful and generalizable attack. Extensive experiments conducted on 11 datasets verify that the clean accuracy of BadCLIP is similar to those of advanced prompt learning methods and the attack success rate is higher than 99% in most cases. BadCLIP is also generalizable to unseen classes, and shows a strong generalization capability under cross-dataset and cross-domain settings.
GraphAdapter: Tuning Vision-Language Models With Dual Knowledge Graph
Sep 24, 2023



Adapter-style efficient transfer learning (ETL) has shown excellent performance in the tuning of vision-language models (VLMs) under the low-data regime, where only a few additional parameters are introduced to excavate the task-specific knowledge based on the general and powerful representation of VLMs. However, most adapter-style works face two limitations: (i) modeling task-specific knowledge with a single modality only; and (ii) overlooking the exploitation of the inter-class relationships in downstream tasks, thereby leading to sub-optimal solutions. To mitigate that, we propose an effective adapter-style tuning strategy, dubbed GraphAdapter, which performs the textual adapter by explicitly modeling the dual-modality structure knowledge (i.e., the correlation of different semantics/classes in textual and visual modalities) with a dual knowledge graph. In particular, the dual knowledge graph is established with two sub-graphs, i.e., a textual knowledge sub-graph, and a visual knowledge sub-graph, where the nodes and edges represent the semantics/classes and their correlations in two modalities, respectively. This enables the textual feature of each prompt to leverage the task-specific structure knowledge from both textual and visual modalities, yielding a more effective classifier for downstream tasks. Extensive experimental results on 11 benchmark datasets reveal that our GraphAdapter significantly outperforms previous adapter-based methods. The code will be released at https://github.com/lixinustc/GraphAdapter
A Dive into SAM Prior in Image Restoration
May 23, 2023
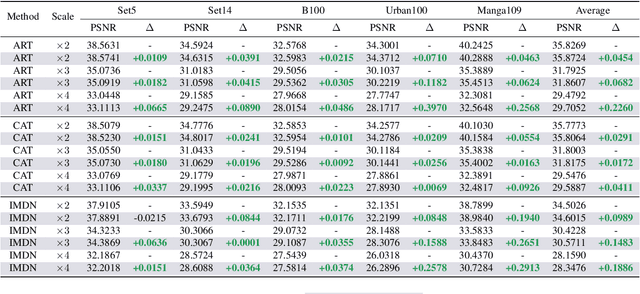
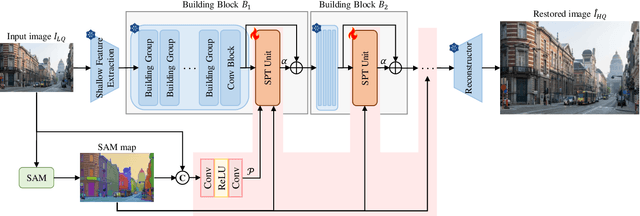
The goal of image restoration (IR), a fundamental issue in computer vision, is to restore a high-quality (HQ) image from its degraded low-quality (LQ) observation. Multiple HQ solutions may correspond to an LQ input in this poorly posed problem, creating an ambiguous solution space. This motivates the investigation and incorporation of prior knowledge in order to effectively constrain the solution space and enhance the quality of the restored images. In spite of the pervasive use of hand-crafted and learned priors in IR, limited attention has been paid to the incorporation of knowledge from large-scale foundation models. In this paper, we for the first time leverage the prior knowledge of the state-of-the-art segment anything model (SAM) to boost the performance of existing IR networks in an parameter-efficient tuning manner. In particular, the choice of SAM is based on its robustness to image degradations, such that HQ semantic masks can be extracted from it. In order to leverage semantic priors and enhance restoration quality, we propose a lightweight SAM prior tuning (SPT) unit. This plug-and-play component allows us to effectively integrate semantic priors into existing IR networks, resulting in significant improvements in restoration quality. As the only trainable module in our method, the SPT unit has the potential to improve both efficiency and scalability. We demonstrate the effectiveness of the proposed method in enhancing a variety of methods across multiple tasks, such as image super-resolution and color image denoising.
Can SAM Boost Video Super-Resolution?
May 12, 2023The primary challenge in video super-resolution (VSR) is to handle large motions in the input frames, which makes it difficult to accurately aggregate information from multiple frames. Existing works either adopt deformable convolutions or estimate optical flow as a prior to establish correspondences between frames for the effective alignment and fusion. However, they fail to take into account the valuable semantic information that can greatly enhance it; and flow-based methods heavily rely on the accuracy of a flow estimate model, which may not provide precise flows given two low-resolution frames. In this paper, we investigate a more robust and semantic-aware prior for enhanced VSR by utilizing the Segment Anything Model (SAM), a powerful foundational model that is less susceptible to image degradation. To use the SAM-based prior, we propose a simple yet effective module -- SAM-guidEd refinEment Module (SEEM), which can enhance both alignment and fusion procedures by the utilization of semantic information. This light-weight plug-in module is specifically designed to not only leverage the attention mechanism for the generation of semantic-aware feature but also be easily and seamlessly integrated into existing methods. Concretely, we apply our SEEM to two representative methods, EDVR and BasicVSR, resulting in consistently improved performance with minimal implementation effort, on three widely used VSR datasets: Vimeo-90K, REDS and Vid4. More importantly, we found that the proposed SEEM can advance the existing methods in an efficient tuning manner, providing increased flexibility in adjusting the balance between performance and the number of training parameters. Code will be open-source soon.