 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Long Video Understanding with Audiovisual Entity Cohesion and Agentic Search
Jan 20, 2026Long video understanding presents significant challenges for vision-language models due to extremely long context windows. Existing solutions relying on naive chunking strategies with retrieval-augmented generation, typically suffer from information fragmentation and a loss of global coherence. We present HAVEN, a unified framework for long-video understanding that enables coherent and comprehensive reasoning by integrating audiovisual entity cohesion and hierarchical video indexing with agentic search. First, we preserve semantic consistency by integrating entity-level representations across visual and auditory streams, while organizing content into a structured hierarchy spanning global summary, scene, segment, and entity levels. Then we employ an agentic search mechanism to enable dynamic retrieval and reasoning across these layers, facilitating coherent narrative reconstruction and fine-grained entity tracking. Extensive experiments demonstrate that our method achieves good temporal coherence, entity consistency, and retrieval efficiency, establishing a new state-of-the-art with an overall accuracy of 84.1% on LVBench. Notably, it achieves outstanding performance in the challenging reasoning category, reaching 80.1%. These results highlight the effectiveness of structured, multimodal reasoning for comprehensive and context-consistent understanding of long-form videos.
Johnson-Lindenstrauss Lemma Guided Network for Efficient 3D Medical Segmentation
Sep 26, 2025Lightweight 3D medical image segmentation remains constrained by a fundamental "efficiency / robustness conflict", particularly when processing complex anatomical structures and heterogeneous modalities. In this paper, we study how to redesign the framework based on the characteristics of high-dimensional 3D images, and explore data synergy to overcome the fragile representation of lightweight methods. Our approach, VeloxSeg, begins with a deployable and extensible dual-stream CNN-Transformer architecture composed of Paired Window Attention (PWA) and Johnson-Lindenstrauss lemma-guided convolution (JLC). For each 3D image, we invoke a "glance-and-focus" principle, where PWA rapidly retrieves multi-scale information, and JLC ensures robust local feature extraction with minimal parameters, significantly enhancing the model's ability to operate with low computational budget. Followed by an extension of the dual-stream architecture that incorporates modal interaction into the multi-scale image-retrieval process, VeloxSeg efficiently models heterogeneous modalities. Finally, Spatially Decoupled Knowledge Transfer (SDKT) via Gram matrices injects the texture prior extracted by a self-supervised network into the segmentation network, yielding stronger representations than baselines at no extra inference cost. Experimental results on multimodal benchmarks show that VeloxSeg achieves a 26% Dice improvement, alongside increasing GPU throughput by 11x and CPU by 48x. Codes are available at https://github.com/JinPLu/VeloxSeg.
Dual form Complementary Masking for Domain-Adaptive Image Segmentation
Jul 16, 2025Recent works have correlated Masked Image Modeling (MIM) with consistency regularization in Unsupervised Domain Adaptation (UDA). However, they merely treat masking as a special form of deformation on the input images and neglect the theoretical analysis, which leads to a superficial understanding of masked reconstruction and insufficient exploitation of its potential in enhancing feature extraction and representation learning. In this paper, we reframe masked reconstruction as a sparse signal reconstruction problem and theoretically prove that the dual form of complementary masks possesses superior capabilities in extracting domain-agnostic image features. Based on this compelling insight, we propose MaskTwins, a simple yet effective UDA framework that integrates masked reconstruction directly into the main training pipeline. MaskTwins uncovers intrinsic structural patterns that persist across disparate domains by enforcing consistency between predictions of images masked in complementary ways, enabling domain generalization in an end-to-end manner. Extensive experiments verify the superiority of MaskTwins over baseline methods in natural and biological image segmentation. These results demonstrate the significant advantages of MaskTwins in extracting domain-invariant features without the need for separate pre-training, offering a new paradigm for domain-adaptive segmentation.
Text-Queried Audio Source Separation via Hierarchical Modeling
May 27, 2025



Target audio source separation with natural language queries presents a promising paradigm for extracting arbitrary audio events through arbitrary text descriptions. Existing methods mainly face two challenges, the difficulty in jointly modeling acoustic-textual alignment and semantic-aware separation within a blindly-learned single-stage architecture, and the reliance on large-scale accurately-labeled training data to compensate for inefficient cross-modal learning and separation. To address these challenges, we propose a hierarchical decomposition framework, HSM-TSS, that decouples the task into global-local semantic-guided feature separation and structure-preserving acoustic reconstruction. Our approach introduces a dual-stage mechanism for semantic separation, operating on distinct global and local semantic feature spaces. We first perform global-semantic separation through a global semantic feature space aligned with text queries. A Q-Audio architecture is employed to align audio and text modalities, serving as pretrained global-semantic encoders. Conditioned on the predicted global feature, we then perform the second-stage local-semantic separation on AudioMAE features that preserve time-frequency structures, followed by acoustic reconstruction. We also propose an instruction processing pipeline to parse arbitrary text queries into structured operations, extraction or removal, coupled with audio descriptions, enabling flexible sound manipulation. Our method achieves state-of-the-art separation performance with data-efficient training while maintaining superior semantic consistency with queries in complex auditory scenes.
Multi-band Frequency Reconstruction for Neural Psychoacoustic Coding
May 12, 2025Achieving high-fidelity audio compression while preserving perceptual quality across diverse content remains a key challenge in Neural Audio Coding (NAC). We introduce MUFFIN, a fully convolutional Neural Psychoacoustic Coding (NPC) framework that leverages psychoacoustically guided multi-band frequency reconstruction. At its core is a Multi-Band Spectral Residual Vector Quantization (MBS-RVQ) module that allocates bitrate across frequency bands based on perceptual salience. This design enables efficient compression while disentangling speaker identity from content using distinct codebooks. MUFFIN incorporates a transformer-inspired convolutional backbone and a modified snake activation to enhance resolution in fine-grained spectral regions. Experimental results on multiple benchmarks demonstrate that MUFFIN consistently outperforms existing approaches in reconstruction quality. A high-compression variant achieves a state-of-the-art 12.5 Hz rate with minimal loss. MUFFIN also proves effective in downstream generative tasks, highlighting its promise as a token representation for integration with language models. Audio samples and code are available.
Plug-and-Play Versatile Compressed Video Enhancement
Apr 21, 2025As a widely adopted technique in data transmission, video compression effectively reduces the size of files, making it possible for real-time cloud computing. However, it comes at the cost of visual quality, posing challenges to the robustness of downstream vision models. In this work, we present a versatile codec-aware enhancement framework that reuses codec information to adaptively enhance videos under different compression settings, assisting various downstream vision tasks without introducing computation bottleneck. Specifically, the proposed codec-aware framework consists of a compression-aware adaptation (CAA) network that employs a hierarchical adaptation mechanism to estimate parameters of the frame-wise enhancement network, namely the bitstream-aware enhancement (BAE) network. The BAE network further leverages temporal and spatial priors embedded in the bitstream to effectively improve the quality of compressed input frames. Extensive experimental results demonstrate the superior quality enhancement performance of our framework over existing enhancement methods, as well as its versatility in assisting multiple downstream tasks on compressed videos as a plug-and-play module. Code and models are available at https://huimin-zeng.github.io/PnP-VCVE/.
Event-Enhanced Blurry Video Super-Resolution
Apr 18, 2025In this paper, we tackle the task of blurry video super-resolution (BVSR), aiming to generate high-resolution (HR) videos from low-resolution (LR) and blurry inputs. Current BVSR methods often fail to restore sharp details at high resolutions, resulting in noticeable artifacts and jitter due to insufficient motion information for deconvolution and the lack of high-frequency details in LR frames. To address these challenges, we introduce event signals into BVSR and propose a novel event-enhanced network, Ev-DeblurVSR. To effectively fuse information from frames and events for feature deblurring, we introduce a reciprocal feature deblurring module that leverages motion information from intra-frame events to deblur frame features while reciprocally using global scene context from the frames to enhance event features. Furthermore, to enhance temporal consistency, we propose a hybrid deformable alignment module that fully exploits the complementary motion information from inter-frame events and optical flow to improve motion estimation in the deformable alignment process. Extensive evaluations demonstrate that Ev-DeblurVSR establishes a new state-of-the-art performance on both synthetic and real-world datasets. Notably, on real data, our method is +2.59 dB more accurate and 7.28$\times$ faster than the recent best BVSR baseline FMA-Net. Code: https://github.com/DachunKai/Ev-DeblurVSR.
Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025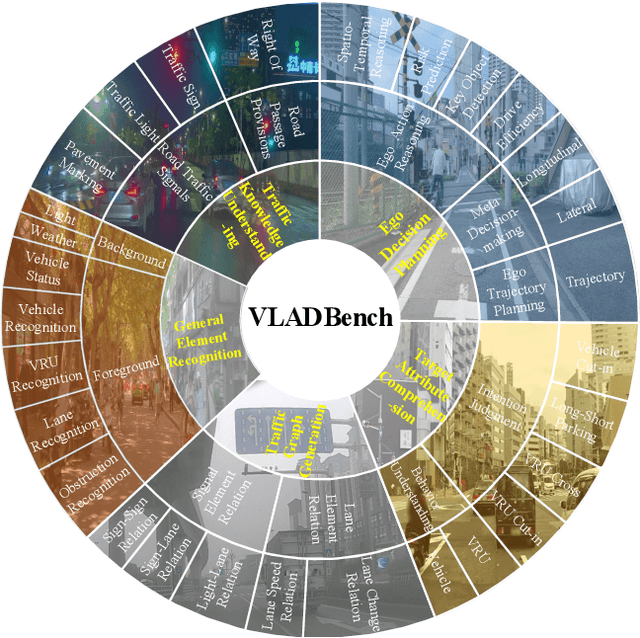

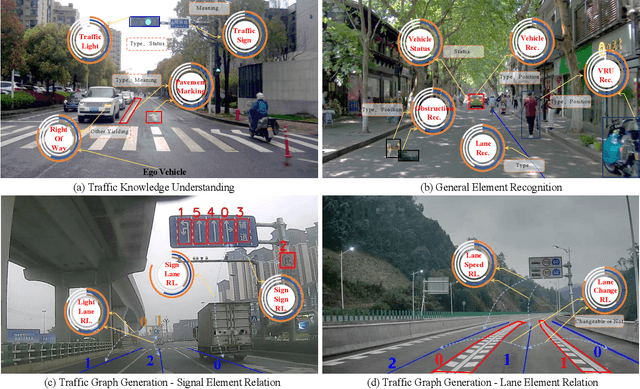

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
All-in-One Image Compression and Restoration
Feb 05, 2025



Visual images corrupted by various types and levels of degradations are commonly encountered in practical image compression. However, most existing image compression methods are tailored for clean images, therefore struggling to achieve satisfying results on these images. Joint compression and restoration methods typically focus on a single type of degradation and fail to address a variety of degradations in practice. To this end, we propose a unified framework for all-in-one image compression and restoration, which incorporates the image restoration capability against various degradations into the process of image compression. The key challenges involve distinguishing authentic image content from degradations, and flexibly eliminating various degradations without prior knowledge. Specifically, the proposed framework approaches these challenges from two perspectives: i.e., content information aggregation, and degradation representation aggregation. Extensive experiments demonstrate the following merits of our model: 1) superior rate-distortion (RD) performance on various degraded inputs while preserving the performance on clean data; 2) strong generalization ability to real-world and unseen scenarios; 3) higher computing efficiency over compared methods. Our code is available at https://github.com/ZeldaM1/All-in-one.
QMamba: Post-Training Quantization for Vision State Space Models
Jan 23, 2025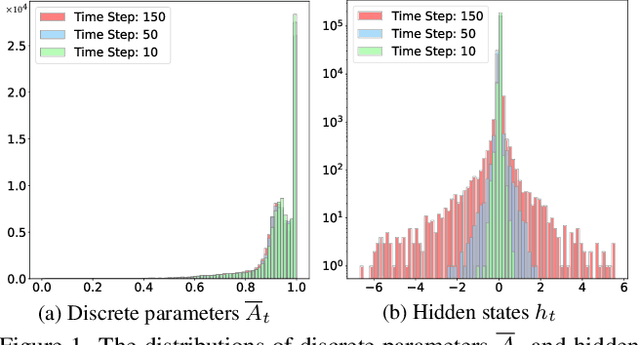

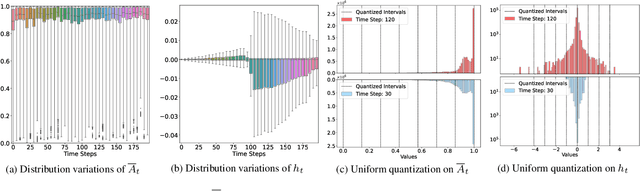

State Space Models (SSMs), as key components of Mamaba, have gained increasing attention for vision models recently, thanks to their efficient long sequence modeling capability. Given the computational cost of deploying SSMs on resource-limited edge devices, Post-Training Quantization (PTQ) is a technique with the potential for efficient deployment of SSMs. In this work, we propose QMamba, one of the first PTQ frameworks to our knowledge, designed for vision SSMs based on the analysis of the activation distributions in SSMs. We reveal that the distribution of discrete parameters exhibits long-tailed skewness and the distribution of the hidden state sequence exhibits highly dynamic variations. Correspondingly, we design Long-tailed Skewness Quantization (LtSQ) to quantize discrete parameters and Temporal Group Quantization (TGQ) to quantize hidden states, which reduces the quantization errors. Extensive experiments demonstrate that QMamba outperforms advanced PTQ methods on vision models across multiple model sizes and architectures. Notably, QMamba surpasses existing methods by 21.0% on ImageNet classification with 4-bit activations.