 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Output Rankings in Generative Engines for LLM-based Search
Feb 03, 2026The way customers search for and choose products is changing with the rise of large language models (LLMs). LLM-based search, or generative engines, provides direct product recommendations to users, rather than traditional online search results that require users to explore options themselves. However, these recommendations are strongly influenced by the initial retrieval order of LLMs, which disadvantages small businesses and independent creators by limiting their visibility. In this work, we propose CORE, an optimization method that \textbf{C}ontrols \textbf{O}utput \textbf{R}ankings in g\textbf{E}nerative Engines for LLM-based search. Since the LLM's interactions with the search engine are black-box, CORE targets the content returned by search engines as the primary means of influencing output rankings. Specifically, CORE optimizes retrieved content by appending strategically designed optimization content to steer the ranking of outputs. We introduce three types of optimization content: string-based, reasoning-based, and review-based, demonstrating their effectiveness in shaping output rankings. To evaluate CORE in realistic settings, we introduce ProductBench, a large-scale benchmark with 15 product categories and 200 products per category, where each product is associated with its top-10 recommendations collected from Amazon's search interface. Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of \textbf{91.4\% @Top-5}, \textbf{86.6\% @Top-3}, and \textbf{80.3\% @Top-1}, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
FASA: Frequency-aware Sparse Attention
Feb 03, 2026The deployment of Large Language Models (LLMs) faces a critical bottleneck when handling lengthy inputs: the prohibitive memory footprint of the Key Value (KV) cache. To address this bottleneck, the token pruning paradigm leverages attention sparsity to selectively retain a small, critical subset of tokens. However, existing approaches fall short, with static methods risking irreversible information loss and dynamic strategies employing heuristics that insufficiently capture the query-dependent nature of token importance. We propose FASA, a novel framework that achieves query-aware token eviction by dynamically predicting token importance. FASA stems from a novel insight into RoPE: the discovery of functional sparsity at the frequency-chunk (FC) level. Our key finding is that a small, identifiable subset of "dominant" FCs consistently exhibits high contextual agreement with the full attention head. This provides a robust and computationally free proxy for identifying salient tokens. %making them a powerful and efficient proxy for token importance. Building on this insight, FASA first identifies a critical set of tokens using dominant FCs, and then performs focused attention computation solely on this pruned subset. % Since accessing only a small fraction of the KV cache, FASA drastically lowers memory bandwidth requirements and computational cost. Across a spectrum of long-context tasks, from sequence modeling to complex CoT reasoning, FASA consistently outperforms all token-eviction baselines and achieves near-oracle accuracy, demonstrating remarkable robustness even under constraint budgets. Notably, on LongBench-V1, FASA reaches nearly 100\% of full-KV performance when only keeping 256 tokens, and achieves 2.56$\times$ speedup using just 18.9\% of the cache on AIME24.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025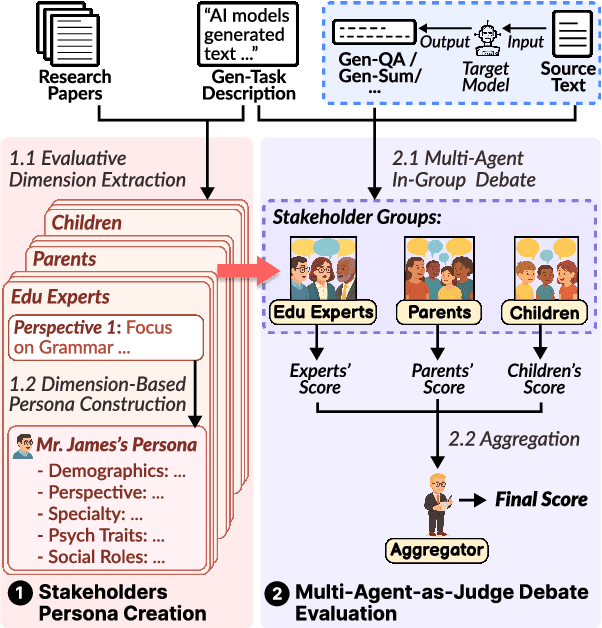



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
Hybrid Latent Reasoning via Reinforcement Learning
May 24, 2025Recent advances in large language models (LLMs) have introduced latent reasoning as a promising alternative to autoregressive reasoning. By performing internal computation with hidden states from previous steps, latent reasoning benefit from more informative features rather than sampling a discrete chain-of-thought (CoT) path. Yet latent reasoning approaches are often incompatible with LLMs, as their continuous paradigm conflicts with the discrete nature of autoregressive generation. Moreover, these methods rely on CoT traces for training and thus fail to exploit the inherent reasoning patterns of LLMs. In this work, we explore latent reasoning by leveraging the intrinsic capabilities of LLMs via reinforcement learning (RL). To this end, we introduce hybrid reasoning policy optimization (HRPO), an RL-based hybrid latent reasoning approach that (1) integrates prior hidden states into sampled tokens with a learnable gating mechanism, and (2) initializes training with predominantly token embeddings while progressively incorporating more hidden features. This design maintains LLMs' generative capabilities and incentivizes hybrid reasoning using both discrete and continuous representations. In addition, the hybrid HRPO introduces stochasticity into latent reasoning via token sampling, thereby enabling RL-based optimization without requiring CoT trajectories. Extensive evaluations across diverse benchmarks show that HRPO outperforms prior methods in both knowledge- and reasoning-intensive tasks. Furthermore, HRPO-trained LLMs remain interpretable and exhibit intriguing behaviors like cross-lingual patterns and shorter completion lengths, highlighting the potential of our RL-based approach and offer insights for future work in latent reasoning.
Plug-and-Play Versatile Compressed Video Enhancement
Apr 21, 2025As a widely adopted technique in data transmission, video compression effectively reduces the size of files, making it possible for real-time cloud computing. However, it comes at the cost of visual quality, posing challenges to the robustness of downstream vision models. In this work, we present a versatile codec-aware enhancement framework that reuses codec information to adaptively enhance videos under different compression settings, assisting various downstream vision tasks without introducing computation bottleneck. Specifically, the proposed codec-aware framework consists of a compression-aware adaptation (CAA) network that employs a hierarchical adaptation mechanism to estimate parameters of the frame-wise enhancement network, namely the bitstream-aware enhancement (BAE) network. The BAE network further leverages temporal and spatial priors embedded in the bitstream to effectively improve the quality of compressed input frames. Extensive experimental results demonstrate the superior quality enhancement performance of our framework over existing enhancement methods, as well as its versatility in assisting multiple downstream tasks on compressed videos as a plug-and-play module. Code and models are available at https://huimin-zeng.github.io/PnP-VCVE/.
All-in-One Image Compression and Restoration
Feb 05, 2025



Visual images corrupted by various types and levels of degradations are commonly encountered in practical image compression. However, most existing image compression methods are tailored for clean images, therefore struggling to achieve satisfying results on these images. Joint compression and restoration methods typically focus on a single type of degradation and fail to address a variety of degradations in practice. To this end, we propose a unified framework for all-in-one image compression and restoration, which incorporates the image restoration capability against various degradations into the process of image compression. The key challenges involve distinguishing authentic image content from degradations, and flexibly eliminating various degradations without prior knowledge. Specifically, the proposed framework approaches these challenges from two perspectives: i.e., content information aggregation, and degradation representation aggregation. Extensive experiments demonstrate the following merits of our model: 1) superior rate-distortion (RD) performance on various degraded inputs while preserving the performance on clean data; 2) strong generalization ability to real-world and unseen scenarios; 3) higher computing efficiency over compared methods. Our code is available at https://github.com/ZeldaM1/All-in-one.
Transferable Sequential Recommendation via Vector Quantized Meta Learning
Nov 04, 2024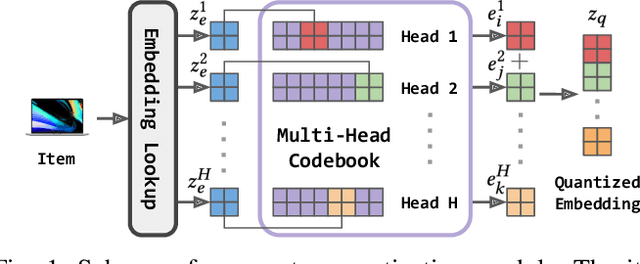

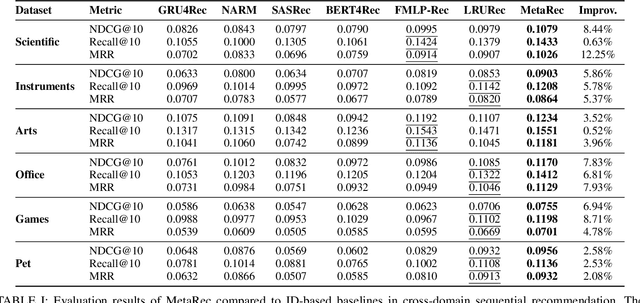

While sequential recommendation achieves significant progress on capturing user-item transition patterns, transferring such large-scale recommender systems remains challenging due to the disjoint user and item groups across domains. In this paper, we propose a vector quantized meta learning for transferable sequential recommenders (MetaRec). Without requiring additional modalities or shared information across domains, our approach leverages user-item interactions from multiple source domains to improve the target domain performance. To solve the input heterogeneity issue, we adopt vector quantization that maps item embeddings from heterogeneous input spaces to a shared feature space. Moreover, our meta transfer paradigm exploits limited target data to guide the transfer of source domain knowledge to the target domain (i.e., learn to transfer). In addition, MetaRec adaptively transfers from multiple source tasks by rescaling meta gradients based on the source-target domain similarity, enabling selective learning to improve recommendation performance. To validate the effectiveness of our approach, we perform extensive experiments on benchmark datasets, where MetaRec consistently outperforms baseline methods by a considerable margin.
Train Once, Deploy Anywhere: Matryoshka Representation Learning for Multimodal Recommendation
Sep 25, 2024



Despite recent advancements in language and vision modeling, integrating rich multimodal knowledge into recommender systems continues to pose significant challenges. This is primarily due to the need for efficient recommendation, which requires adaptive and interactive responses. In this study, we focus on sequential recommendation and introduce a lightweight framework called full-scale Matryoshka representation learning for multimodal recommendation (fMRLRec). Our fMRLRec captures item features at different granularities, learning informative representations for efficient recommendation across multiple dimensions. To integrate item features from diverse modalities, fMRLRec employs a simple mapping to project multimodal item features into an aligned feature space. Additionally, we design an efficient linear transformation that embeds smaller features into larger ones, substantially reducing memory requirements for large-scale training on recommendation data. Combined with improved state space modeling techniques, fMRLRec scales to different dimensions and only requires one-time training to produce multiple models tailored to various granularities. We demonstrate the effectiveness and efficiency of fMRLRec on multiple benchmark datasets, which consistently achieves superior performance over state-of-the-art baseline methods.
Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments
Jun 14, 2024



The rapid propagation of misinformation poses substantial risks to public interest. To combat misinformation, large language models (LLMs) are adapted to automatically verify claim credibility. Nevertheless, existing methods heavily rely on the embedded knowledge within LLMs and / or black-box APIs for evidence collection, leading to subpar performance with smaller LLMs or upon unreliable context. In this paper, we propose retrieval augmented fact verification through the synthesis of contrasting arguments (RAFTS). Upon input claims, RAFTS starts with evidence retrieval, where we design a retrieval pipeline to collect and re-rank relevant documents from verifiable sources. Then, RAFTS forms contrastive arguments (i.e., supporting or refuting) conditioned on the retrieved evidence. In addition, RAFTS leverages an embedding model to identify informative demonstrations, followed by in-context prompting to generate the prediction and explanation. Our method effectively retrieves relevant documents as evidence and evaluates arguments from varying perspectives, incorporating nuanced information for fine-grained decision-making. Combined with informative in-context examples as prior, RAFTS achieves significant improvements to supervised and LLM baselines without complex prompts. We demonstrate the effectiveness of our method through extensive experiments, where RAFTS can outperform GPT-based methods with a significantly smaller 7B LLM.