 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Latent Reasoning via Reinforcement Learning
May 24, 2025Recent advances in large language models (LLMs) have introduced latent reasoning as a promising alternative to autoregressive reasoning. By performing internal computation with hidden states from previous steps, latent reasoning benefit from more informative features rather than sampling a discrete chain-of-thought (CoT) path. Yet latent reasoning approaches are often incompatible with LLMs, as their continuous paradigm conflicts with the discrete nature of autoregressive generation. Moreover, these methods rely on CoT traces for training and thus fail to exploit the inherent reasoning patterns of LLMs. In this work, we explore latent reasoning by leveraging the intrinsic capabilities of LLMs via reinforcement learning (RL). To this end, we introduce hybrid reasoning policy optimization (HRPO), an RL-based hybrid latent reasoning approach that (1) integrates prior hidden states into sampled tokens with a learnable gating mechanism, and (2) initializes training with predominantly token embeddings while progressively incorporating more hidden features. This design maintains LLMs' generative capabilities and incentivizes hybrid reasoning using both discrete and continuous representations. In addition, the hybrid HRPO introduces stochasticity into latent reasoning via token sampling, thereby enabling RL-based optimization without requiring CoT trajectories. Extensive evaluations across diverse benchmarks show that HRPO outperforms prior methods in both knowledge- and reasoning-intensive tasks. Furthermore, HRPO-trained LLMs remain interpretable and exhibit intriguing behaviors like cross-lingual patterns and shorter completion lengths, highlighting the potential of our RL-based approach and offer insights for future work in latent reasoning.
SIDE: Socially Informed Drought Estimation Toward Understanding Societal Impact Dynamics of Environmental Crisis
Dec 17, 2024



Drought has become a critical global threat with significant societal impact. Existing drought monitoring solutions primarily focus on assessing drought severity using quantitative measurements, overlooking the diverse societal impact of drought from human-centric perspectives. Motivated by the collective intelligence on social media and the computational power of AI, this paper studies a novel problem of socially informed AI-driven drought estimation that aims to leverage social and news media information to jointly estimate drought severity and its societal impact. Two technical challenges exist: 1) How to model the implicit temporal dynamics of drought societal impact. 2) How to capture the social-physical interdependence between the physical drought condition and its societal impact. To address these challenges, we develop SIDE, a socially informed AI-driven drought estimation framework that explicitly quantifies the societal impact of drought and effectively models the social-physical interdependency for joint severity-impact estimation. Experiments on real-world datasets from California and Texas demonstrate SIDE's superior performance compared to state-of-the-art baselines in accurately estimating drought severity and its societal impact. SIDE offers valuable insights for developing human-centric drought mitigation strategies to foster sustainable and resilient communities.
Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments
Jun 14, 2024



The rapid propagation of misinformation poses substantial risks to public interest. To combat misinformation, large language models (LLMs) are adapted to automatically verify claim credibility. Nevertheless, existing methods heavily rely on the embedded knowledge within LLMs and / or black-box APIs for evidence collection, leading to subpar performance with smaller LLMs or upon unreliable context. In this paper, we propose retrieval augmented fact verification through the synthesis of contrasting arguments (RAFTS). Upon input claims, RAFTS starts with evidence retrieval, where we design a retrieval pipeline to collect and re-rank relevant documents from verifiable sources. Then, RAFTS forms contrastive arguments (i.e., supporting or refuting) conditioned on the retrieved evidence. In addition, RAFTS leverages an embedding model to identify informative demonstrations, followed by in-context prompting to generate the prediction and explanation. Our method effectively retrieves relevant documents as evidence and evaluates arguments from varying perspectives, incorporating nuanced information for fine-grained decision-making. Combined with informative in-context examples as prior, RAFTS achieves significant improvements to supervised and LLM baselines without complex prompts. We demonstrate the effectiveness of our method through extensive experiments, where RAFTS can outperform GPT-based methods with a significantly smaller 7B LLM.
Evidence-Driven Retrieval Augmented Response Generation for Online Misinformation
Mar 22, 2024



The proliferation of online misinformation has posed significant threats to public interest. While numerous online users actively participate in the combat against misinformation, many of such responses can be characterized by the lack of politeness and supporting facts. As a solution, text generation approaches are proposed to automatically produce counter-misinformation responses. Nevertheless, existing methods are often trained end-to-end without leveraging external knowledge, resulting in subpar text quality and excessively repetitive responses. In this paper, we propose retrieval augmented response generation for online misinformation (RARG), which collects supporting evidence from scientific sources and generates counter-misinformation responses based on the evidences. In particular, our RARG consists of two stages: (1) evidence collection, where we design a retrieval pipeline to retrieve and rerank evidence documents using a database comprising over 1M academic articles; (2) response generation, in which we align large language models (LLMs) to generate evidence-based responses via reinforcement learning from human feedback (RLHF). We propose a reward function to maximize the utilization of the retrieved evidence while maintaining the quality of the generated text, which yields polite and factual responses that clearly refutes misinformation. To demonstrate the effectiveness of our method, we study the case of COVID-19 and perform extensive experiments with both in- and cross-domain datasets, where RARG consistently outperforms baselines by generating high-quality counter-misinformation responses.
MetaAdapt: Domain Adaptive Few-Shot Misinformation Detection via Meta Learning
May 22, 2023

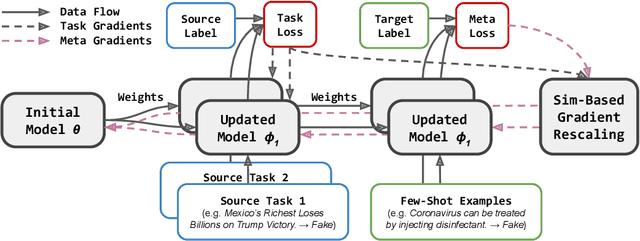

With emerging topics (e.g., COVID-19) on social media as a source for the spreading misinformation, overcoming the distributional shifts between the original training domain (i.e., source domain) and such target domains remains a non-trivial task for misinformation detection. This presents an elusive challenge for early-stage misinformation detection, where a good amount of data and annotations from the target domain is not available for training. To address the data scarcity issue, we propose MetaAdapt, a meta learning based approach for domain adaptive few-shot misinformation detection. MetaAdapt leverages limited target examples to provide feedback and guide the knowledge transfer from the source to the target domain (i.e., learn to adapt). In particular, we train the initial model with multiple source tasks and compute their similarity scores to the meta task. Based on the similarity scores, we rescale the meta gradients to adaptively learn from the source tasks. As such, MetaAdapt can learn how to adapt the misinformation detection model and exploit the source data for improved performance in the target domain. To demonstrate the efficiency and effectiveness of our method, we perform extensive experiments to compare MetaAdapt with state-of-the-art baselines and large language models (LLMs) such as LLaMA, where MetaAdapt achieves better performance in domain adaptive few-shot misinformation detection with substantially reduced parameters on real-world datasets.
On Attacking Out-Domain Uncertainty Estimation in Deep Neural Networks
Oct 12, 2022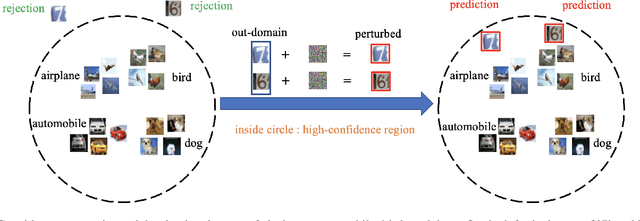
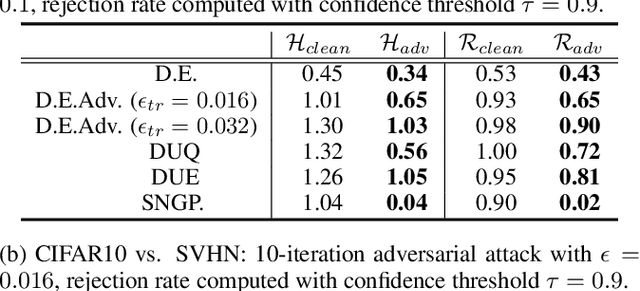
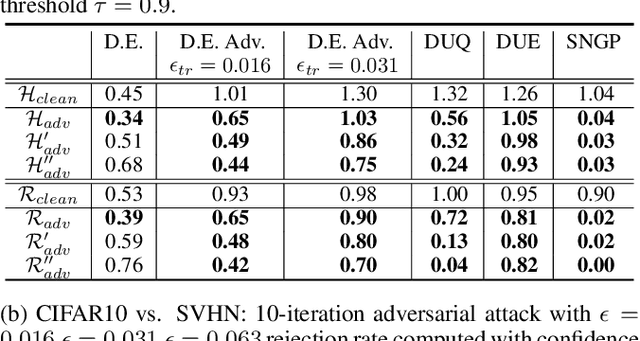
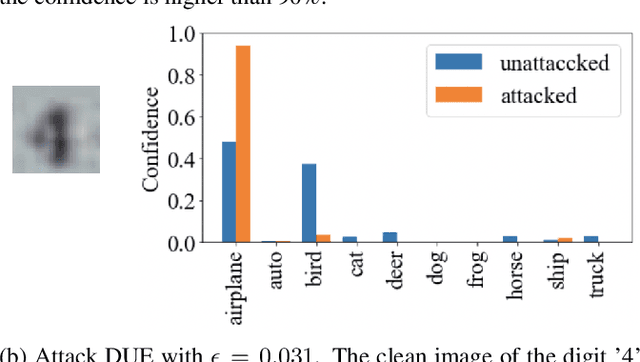
In many applications with real-world consequences, it is crucial to develop reliable uncertainty estimation for the predictions made by the AI decision systems. Targeting at the goal of estimating uncertainty, various deep neural network (DNN) based uncertainty estimation algorithms have been proposed. However, the robustness of the uncertainty returned by these algorithms has not been systematically explored. In this work, to raise the awareness of the research community on robust uncertainty estimation, we show that state-of-the-art uncertainty estimation algorithms could fail catastrophically under our proposed adversarial attack despite their impressive performance on uncertainty estimation. In particular, we aim at attacking the out-domain uncertainty estimation: under our attack, the uncertainty model would be fooled to make high-confident predictions for the out-domain data, which they originally would have rejected. Extensive experimental results on various benchmark image datasets show that the uncertainty estimated by state-of-the-art methods could be easily corrupted by our attack.
Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup
Oct 06, 2022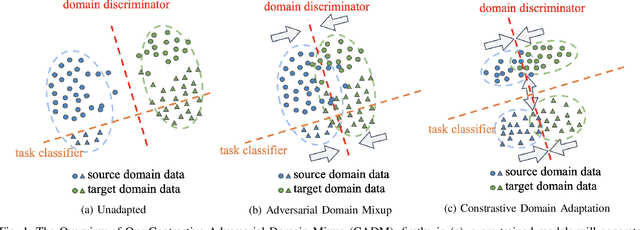
In the real-world application of COVID-19 misinformation detection, a fundamental challenge is the lack of the labeled COVID data to enable supervised end-to-end training of the models, especially at the early stage of the pandemic. To address this challenge, we propose an unsupervised domain adaptation framework using contrastive learning and adversarial domain mixup to transfer the knowledge from an existing source data domain to the target COVID-19 data domain. In particular, to bridge the gap between the source domain and the target domain, our method reduces a radial basis function (RBF) based discrepancy between these two domains. Moreover, we leverage the power of domain adversarial examples to establish an intermediate domain mixup, where the latent representations of the input text from both domains could be mixed during the training process. Extensive experiments on multiple real-world datasets suggest that our method can effectively adapt misinformation detection systems to the unseen COVID-19 target domain with significant improvements compared to the state-of-the-art baselines.
Domain Adaptation for Question Answering via Question Classification
Sep 12, 2022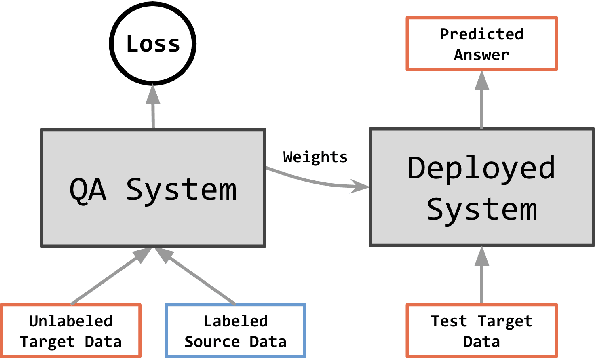
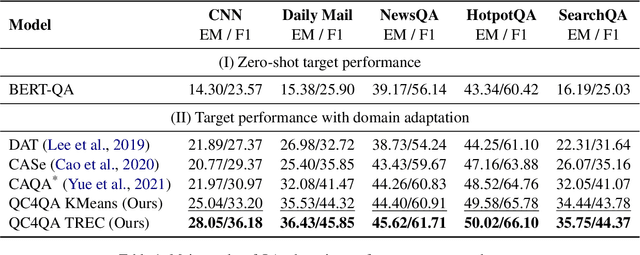

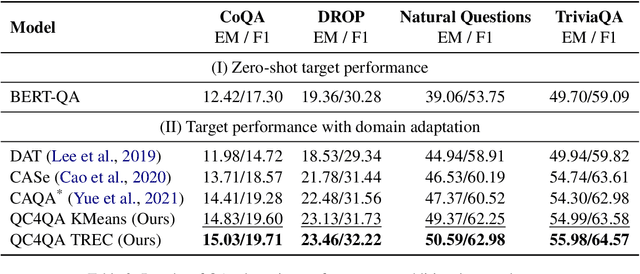
Question answering (QA) has demonstrated impressive progress in answering questions from customized domains. Nevertheless, domain adaptation remains one of the most elusive challenges for QA systems, especially when QA systems are trained in a source domain but deployed in a different target domain. In this work, we investigate the potential benefits of question classification for QA domain adaptation. We propose a novel framework: Question Classification for Question Answering (QC4QA). Specifically, a question classifier is adopted to assign question classes to both the source and target data. Then, we perform joint training in a self-supervised fashion via pseudo-labeling. For optimization, inter-domain discrepancy between the source and target domain is reduced via maximum mean discrepancy (MMD) distance. We additionally minimize intra-class discrepancy among QA samples of the same question class for fine-grained adaptation performance. To the best of our knowledge, this is the first work in QA domain adaptation to leverage question classification with self-supervised adaptation. We demonstrate the effectiveness of the proposed QC4QA with consistent improvements against the state-of-the-art baselines on multiple datasets.
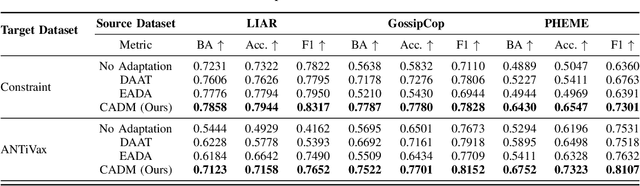
Contrastive Domain Adaptation for Early Misinformation Detection: A Case Study on COVID-19
Aug 30, 2022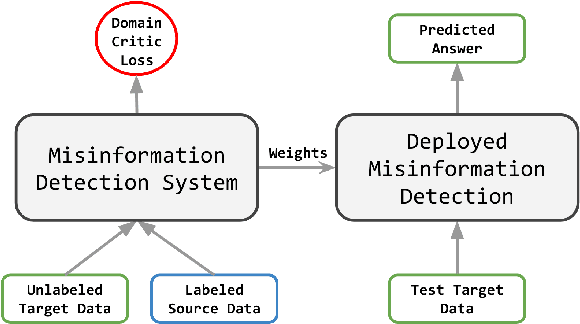
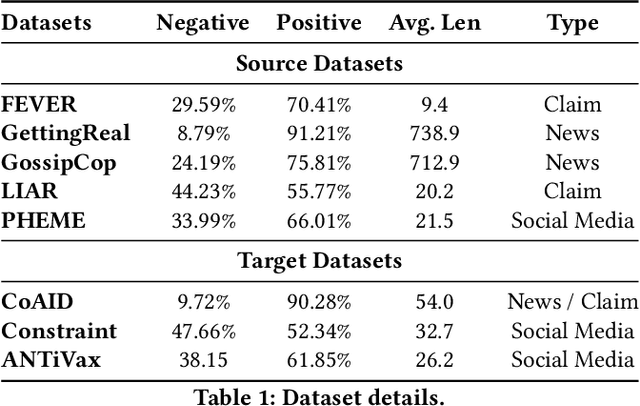
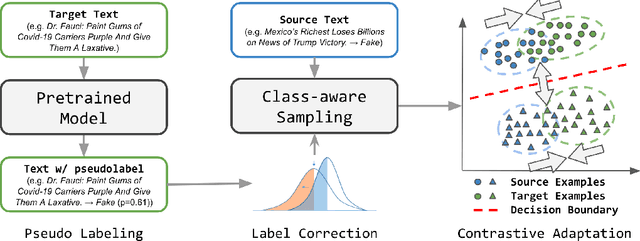

Despite recent progress in improving the performance of misinformation detection systems, classifying misinformation in an unseen domain remains an elusive challenge. To address this issue, a common approach is to introduce a domain critic and encourage domain-invariant input features. However, early misinformation often demonstrates both conditional and label shifts against existing misinformation data (e.g., class imbalance in COVID-19 datasets), rendering such methods less effective for detecting early misinformation. In this paper, we propose contrastive adaptation network for early misinformation detection (CANMD). Specifically, we leverage pseudo labeling to generate high-confidence target examples for joint training with source data. We additionally design a label correction component to estimate and correct the label shifts (i.e., class priors) between the source and target domains. Moreover, a contrastive adaptation loss is integrated in the objective function to reduce the intra-class discrepancy and enlarge the inter-class discrepancy. As such, the adapted model learns corrected class priors and an invariant conditional distribution across both domains for improved estimation of the target data distribution. To demonstrate the effectiveness of the proposed CANMD, we study the case of COVID-19 early misinformation detection and perform extensive experiments using multiple real-world datasets. The results suggest that CANMD can effectively adapt misinformation detection systems to the unseen COVID-19 target domain with significant improvements compared to the state-of-the-art baselines.
Defending Substitution-Based Profile Pollution Attacks on Sequential Recommenders
Jul 19, 2022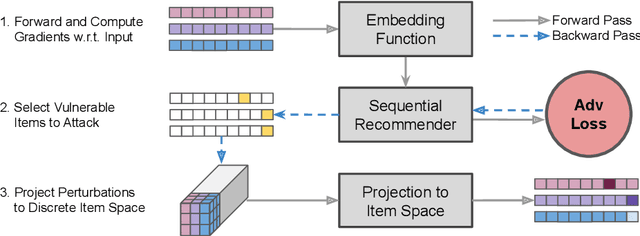


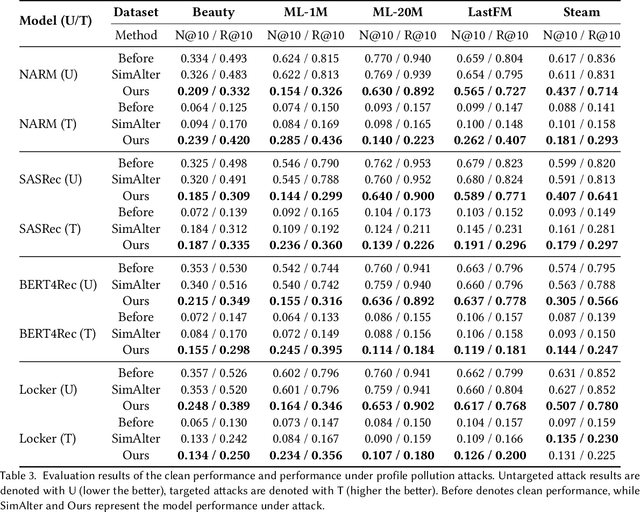
While sequential recommender systems achieve significant improvements on capturing user dynamics, we argue that sequential recommenders are vulnerable against substitution-based profile pollution attacks. To demonstrate our hypothesis, we propose a substitution-based adversarial attack algorithm, which modifies the input sequence by selecting certain vulnerable elements and substituting them with adversarial items. In both untargeted and targeted attack scenarios, we observe significant performance deterioration using the proposed profile pollution algorithm. Motivated by such observations, we design an efficient adversarial defense method called Dirichlet neighborhood sampling. Specifically, we sample item embeddings from a convex hull constructed by multi-hop neighbors to replace the original items in input sequences. During sampling, a Dirichlet distribution is used to approximate the probability distribution in the neighborhood such that the recommender learns to combat local perturbations. Additionally, we design an adversarial training method tailored for sequential recommender systems. In particular, we represent selected items with one-hot encodings and perform gradient ascent on the encodings to search for the worst case linear combination of item embeddings in training. As such, the embedding function learns robust item representations and the trained recommender is resistant to test-time adversarial examples. Extensive experiments show the effectiveness of both our attack and defense methods, which consistently outperform baselines by a significant margin across model architectures and datasets.