 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVI-HT: Adaptive Vision-IMU Fusion for 3D Hand Tracking
May 20, 2026We present AVI-HT, an adaptive visual-IMU fusion approach for tracking 3D hand poses by jointly modeling the egocentric image with on-glove 6-DoF IMU signals. AVI-HT achieves significantly improved accuracy and availability, particularly in hand-object interaction (HOI) scenarios involving heavy visual occlusion. Two complementary ingredients underpin its success: (1) synchronized multi-modal training data pairing on-body vision-IMU sensor streams with ground-truth 3D hand poses from a motion-capture system, and (2) a cross-sensor deep attention mechanism that adaptively modulates the trust assigned to the vision and individual IMU sensors. To evaluate AVI-HT in real-world settings, we conduct extensive experiments on our DexGloveHOI dataset that consists of 100K+ pairwise vision-IMU samples with synchronized 3D annotated poses, in which users manipulate a variety of objects during daily tasks. We compare against multiple single- and multi-modal tracking approaches under two hand models (UmeTrack, MANO). The results show that AVI-HT reduces mean keypoint error by 16.1% and its wrist-aligned variant by 24.2% over the baselines. Ablation studies further reveal the per-finger contribution of IMU sensors across activity types, and the model's sensitivity to IMU noise and temporal misalignment in vision-IMU fusion.
Glove2Hand: Synthesizing Natural Hand-Object Interaction from Multi-Modal Sensing Gloves
Mar 21, 2026Understanding hand-object interaction (HOI) is fundamental to computer vision, robotics, and AR/VR. However, conventional hand videos often lack essential physical information such as contact forces and motion signals, and are prone to frequent occlusions. To address the challenges, we present Glove2Hand, a framework that translates multi-modal sensing glove HOI videos into photorealistic bare hands, while faithfully preserving the underlying physical interaction dynamics. We introduce a novel 3D Gaussian hand model that ensures temporal rendering consistency. The rendered hand is seamlessly integrated into the scene using a diffusion-based hand restorer, which effectively handles complex hand-object interactions and non-rigid deformations. Leveraging Glove2Hand, we create HandSense, the first multi-modal HOI dataset featuring glove-to-hand videos with synchronized tactile and IMU signals. We demonstrate that HandSense significantly enhances downstream bare-hand applications, including video-based contact estimation and hand tracking under severe occlusion.
AirGlove: Exploring Egocentric 3D Hand Tracking and Appearance Generalization for Sensing Gloves
Feb 05, 2026Sensing gloves have become important tools for teleoperation and robotic policy learning as they are able to provide rich signals like speed, acceleration and tactile feedback. A common approach to track gloved hands is to directly use the sensor signals (e.g., angular velocity, gravity orientation) to estimate 3D hand poses. However, sensor-based tracking can be restrictive in practice as the accuracy is often impacted by sensor signal and calibration quality. Recent advances in vision-based approaches have achieved strong performance on human hands via large-scale pre-training, but their performance on gloved hands with distinct visual appearances remains underexplored. In this work, we present the first systematic evaluation of vision-based hand tracking models on gloved hands under both zero-shot and fine-tuning setups. Our analysis shows that existing bare-hand models suffer from substantial performance degradation on sensing gloves due to large appearance gap between bare-hand and glove designs. We therefore propose AirGlove, which leverages existing gloves to generalize the learned glove representations towards new gloves with limited data. Experiments with multiple sensing gloves show that AirGlove effectively generalizes the hand pose models to new glove designs and achieves a significant performance boost over the compared schemes.
Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
UGMAE: A Unified Framework for Graph Masked Autoencoders
Feb 12, 2024



Generative self-supervised learning on graphs, particularly graph masked autoencoders, has emerged as a popular learning paradigm and demonstrated its efficacy in handling non-Euclidean data. However, several remaining issues limit the capability of existing methods: 1) the disregard of uneven node significance in masking, 2) the underutilization of holistic graph information, 3) the ignorance of semantic knowledge in the representation space due to the exclusive use of reconstruction loss in the output space, and 4) the unstable reconstructions caused by the large volume of masked contents. In light of this, we propose UGMAE, a unified framework for graph masked autoencoders to address these issues from the perspectives of adaptivity, integrity, complementarity, and consistency. Specifically, we first develop an adaptive feature mask generator to account for the unique significance of nodes and sample informative masks (adaptivity). We then design a ranking-based structure reconstruction objective joint with feature reconstruction to capture holistic graph information and emphasize the topological proximity between neighbors (integrity). After that, we present a bootstrapping-based similarity module to encode the high-level semantic knowledge in the representation space, complementary to the low-level reconstruction in the output space (complementarity). Finally, we build a consistency assurance module to provide reconstruction objectives with extra stabilized consistency targets (consistency). Extensive experiments demonstrate that UGMAE outperforms both contrastive and generative state-of-the-art baselines on several tasks across multiple datasets.
On Attacking Out-Domain Uncertainty Estimation in Deep Neural Networks
Oct 12, 2022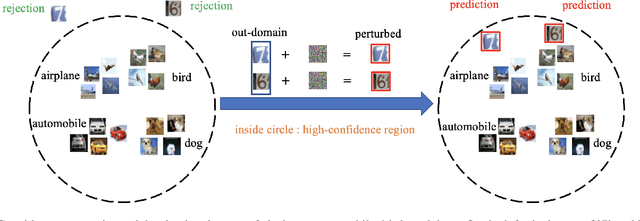
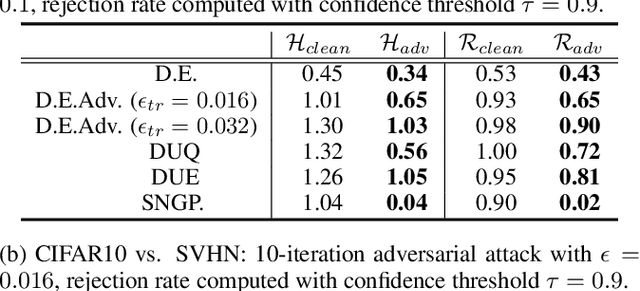
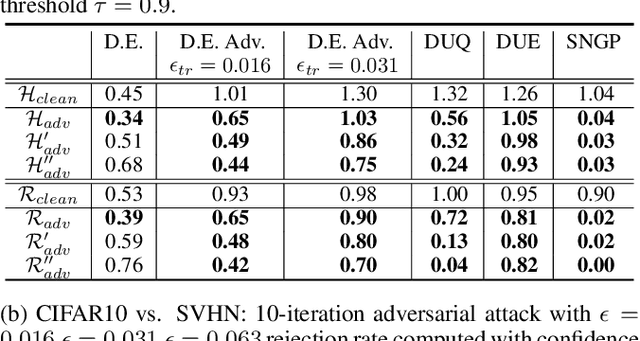
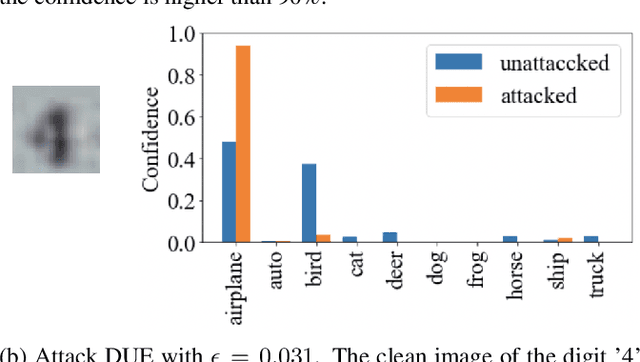
In many applications with real-world consequences, it is crucial to develop reliable uncertainty estimation for the predictions made by the AI decision systems. Targeting at the goal of estimating uncertainty, various deep neural network (DNN) based uncertainty estimation algorithms have been proposed. However, the robustness of the uncertainty returned by these algorithms has not been systematically explored. In this work, to raise the awareness of the research community on robust uncertainty estimation, we show that state-of-the-art uncertainty estimation algorithms could fail catastrophically under our proposed adversarial attack despite their impressive performance on uncertainty estimation. In particular, we aim at attacking the out-domain uncertainty estimation: under our attack, the uncertainty model would be fooled to make high-confident predictions for the out-domain data, which they originally would have rejected. Extensive experimental results on various benchmark image datasets show that the uncertainty estimated by state-of-the-art methods could be easily corrupted by our attack.
Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup
Oct 06, 2022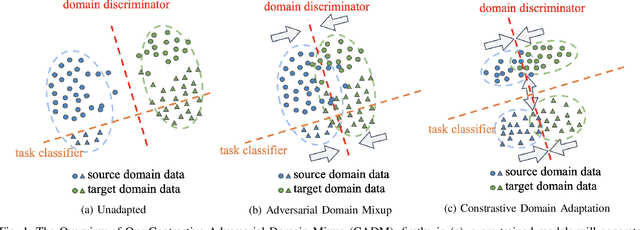
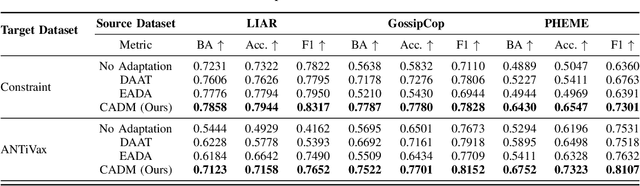
In the real-world application of COVID-19 misinformation detection, a fundamental challenge is the lack of the labeled COVID data to enable supervised end-to-end training of the models, especially at the early stage of the pandemic. To address this challenge, we propose an unsupervised domain adaptation framework using contrastive learning and adversarial domain mixup to transfer the knowledge from an existing source data domain to the target COVID-19 data domain. In particular, to bridge the gap between the source domain and the target domain, our method reduces a radial basis function (RBF) based discrepancy between these two domains. Moreover, we leverage the power of domain adversarial examples to establish an intermediate domain mixup, where the latent representations of the input text from both domains could be mixed during the training process. Extensive experiments on multiple real-world datasets suggest that our method can effectively adapt misinformation detection systems to the unseen COVID-19 target domain with significant improvements compared to the state-of-the-art baselines.
Domain Adaptation for Question Answering via Question Classification
Sep 12, 2022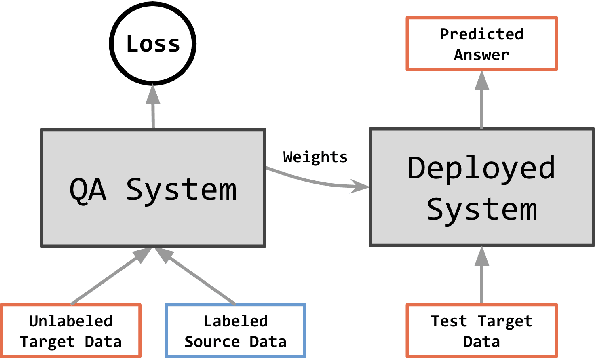
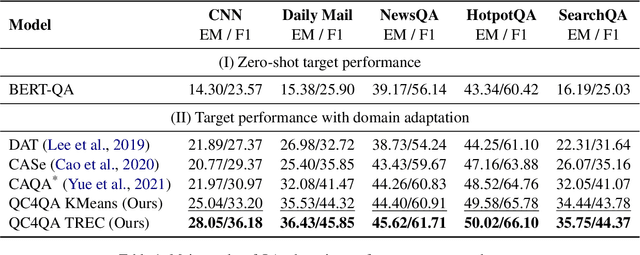

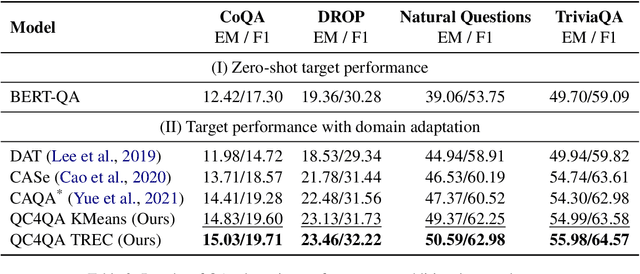
Question answering (QA) has demonstrated impressive progress in answering questions from customized domains. Nevertheless, domain adaptation remains one of the most elusive challenges for QA systems, especially when QA systems are trained in a source domain but deployed in a different target domain. In this work, we investigate the potential benefits of question classification for QA domain adaptation. We propose a novel framework: Question Classification for Question Answering (QC4QA). Specifically, a question classifier is adopted to assign question classes to both the source and target data. Then, we perform joint training in a self-supervised fashion via pseudo-labeling. For optimization, inter-domain discrepancy between the source and target domain is reduced via maximum mean discrepancy (MMD) distance. We additionally minimize intra-class discrepancy among QA samples of the same question class for fine-grained adaptation performance. To the best of our knowledge, this is the first work in QA domain adaptation to leverage question classification with self-supervised adaptation. We demonstrate the effectiveness of the proposed QC4QA with consistent improvements against the state-of-the-art baselines on multiple datasets.
Contrastive Domain Adaptation for Early Misinformation Detection: A Case Study on COVID-19
Aug 30, 2022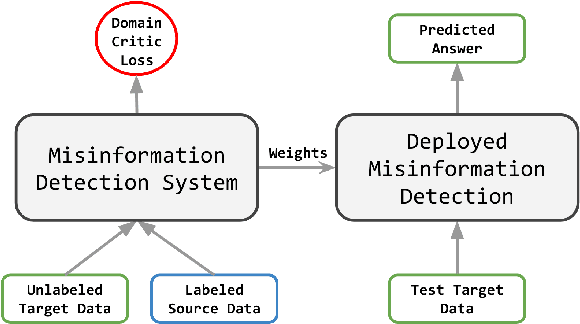
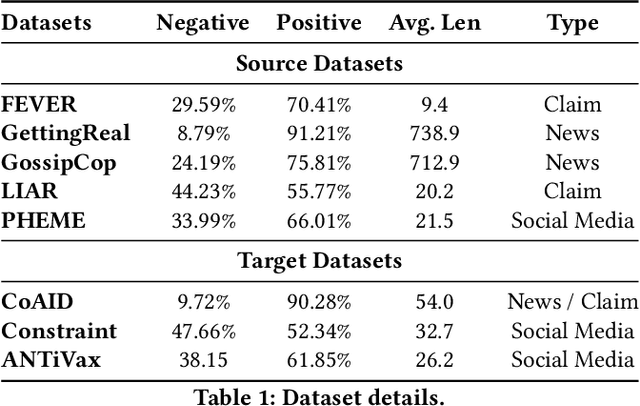
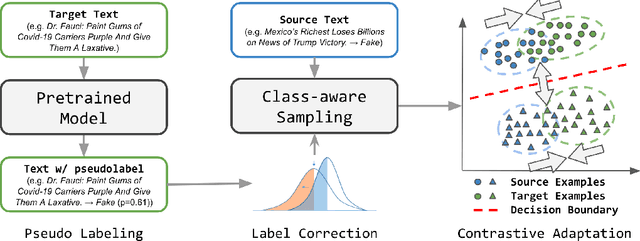

Despite recent progress in improving the performance of misinformation detection systems, classifying misinformation in an unseen domain remains an elusive challenge. To address this issue, a common approach is to introduce a domain critic and encourage domain-invariant input features. However, early misinformation often demonstrates both conditional and label shifts against existing misinformation data (e.g., class imbalance in COVID-19 datasets), rendering such methods less effective for detecting early misinformation. In this paper, we propose contrastive adaptation network for early misinformation detection (CANMD). Specifically, we leverage pseudo labeling to generate high-confidence target examples for joint training with source data. We additionally design a label correction component to estimate and correct the label shifts (i.e., class priors) between the source and target domains. Moreover, a contrastive adaptation loss is integrated in the objective function to reduce the intra-class discrepancy and enlarge the inter-class discrepancy. As such, the adapted model learns corrected class priors and an invariant conditional distribution across both domains for improved estimation of the target data distribution. To demonstrate the effectiveness of the proposed CANMD, we study the case of COVID-19 early misinformation detection and perform extensive experiments using multiple real-world datasets. The results suggest that CANMD can effectively adapt misinformation detection systems to the unseen COVID-19 target domain with significant improvements compared to the state-of-the-art baselines.
Defending Substitution-Based Profile Pollution Attacks on Sequential Recommenders
Jul 19, 2022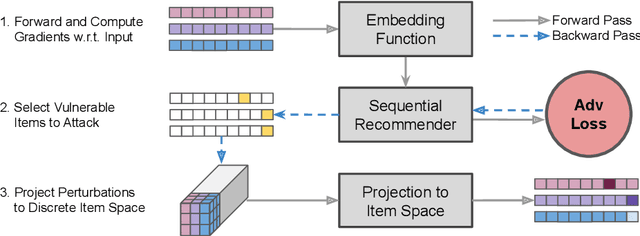


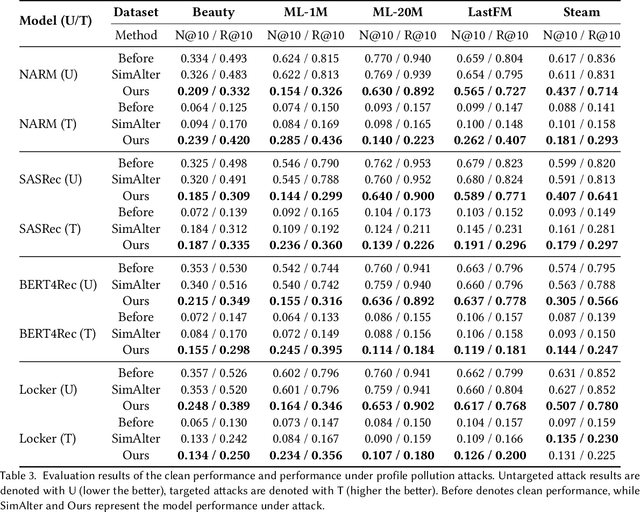
While sequential recommender systems achieve significant improvements on capturing user dynamics, we argue that sequential recommenders are vulnerable against substitution-based profile pollution attacks. To demonstrate our hypothesis, we propose a substitution-based adversarial attack algorithm, which modifies the input sequence by selecting certain vulnerable elements and substituting them with adversarial items. In both untargeted and targeted attack scenarios, we observe significant performance deterioration using the proposed profile pollution algorithm. Motivated by such observations, we design an efficient adversarial defense method called Dirichlet neighborhood sampling. Specifically, we sample item embeddings from a convex hull constructed by multi-hop neighbors to replace the original items in input sequences. During sampling, a Dirichlet distribution is used to approximate the probability distribution in the neighborhood such that the recommender learns to combat local perturbations. Additionally, we design an adversarial training method tailored for sequential recommender systems. In particular, we represent selected items with one-hot encodings and perform gradient ascent on the encodings to search for the worst case linear combination of item embeddings in training. As such, the embedding function learns robust item representations and the trained recommender is resistant to test-time adversarial examples. Extensive experiments show the effectiveness of both our attack and defense methods, which consistently outperform baselines by a significant margin across model architectures and datasets.