 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
1.58-bit FLUX
Dec 24, 2024We present 1.58-bit FLUX, the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}) while maintaining comparable performance for generating 1024 x 1024 images. Notably, our quantization method operates without access to image data, relying solely on self-supervision from the FLUX.1-dev model. Additionally, we develop a custom kernel optimized for 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x reduction in inference memory, and improved inference latency. Extensive evaluations on the GenEval and T2I Compbench benchmarks demonstrate the effectiveness of 1.58-bit FLUX in maintaining generation quality while significantly enhancing computational efficiency.
Tri$^{2}$-plane: Volumetric Avatar Reconstruction with Feature Pyramid
Jan 17, 2024Recent years have witnessed considerable achievements in facial avatar reconstruction with neural volume rendering. Despite notable advancements, the reconstruction of complex and dynamic head movements from monocular videos still suffers from capturing and restoring fine-grained details. In this work, we propose a novel approach, named Tri$^2$-plane, for monocular photo-realistic volumetric head avatar reconstructions. Distinct from the existing works that rely on a single tri-plane deformation field for dynamic facial modeling, the proposed Tri$^2$-plane leverages the principle of feature pyramids and three top-to-down lateral connections tri-planes for details improvement. It samples and renders facial details at multiple scales, transitioning from the entire face to specific local regions and then to even more refined sub-regions. Moreover, we incorporate a camera-based geometry-aware sliding window method as an augmentation in training, which improves the robustness beyond the canonical space, with a particular improvement in cross-identity generation capabilities. Experimental outcomes indicate that the Tri$^2$-plane not only surpasses existing methodologies but also achieves superior performance across both quantitative metrics and qualitative assessments through experiments.
NeLF: Practical Novel View Synthesis with Neural Light Field
May 21, 2021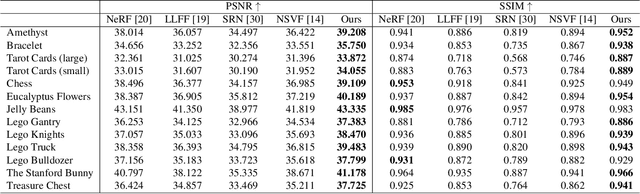
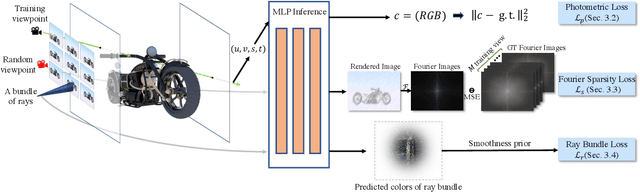
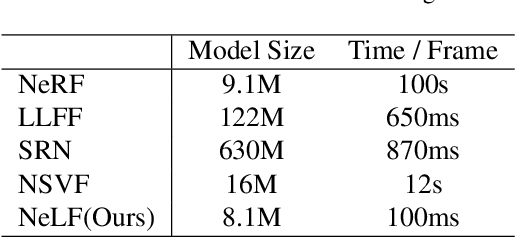
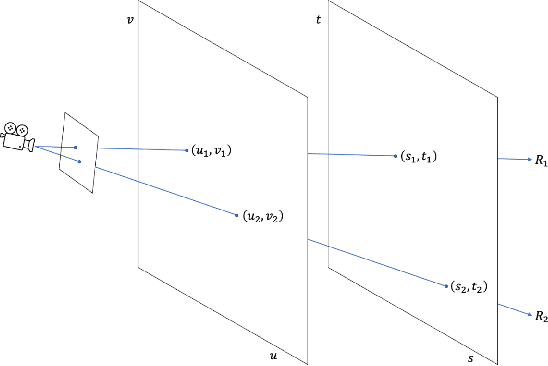
In this paper, we present an efficient and robust deep learning solution for novel view synthesis of complex scenes. In our approach, a 3D scene is represented as a light field, i.e., a set of rays, each of which has a corresponding color when reaching the image plane. For efficient novel view rendering, we adopt a 4D parameterization of the light field, where each ray is characterized by a 4D parameter. We then formulate the light field as a 4D function that maps 4D coordinates to corresponding color values. We train a deep fully connected network to optimize this implicit function and memorize the 3D scene. Then, the scene-specific model is used to synthesize novel views. Different from previous light field approaches which require dense view sampling to reliably render novel views, our method can render novel views by sampling rays and querying the color for each ray from the network directly, thus enabling high-quality light field rendering with a sparser set of training images. Our method achieves state-of-the-art novel view synthesis results while maintaining an interactive frame rate.
Talking-head Generation with Rhythmic Head Motion
Jul 16, 2020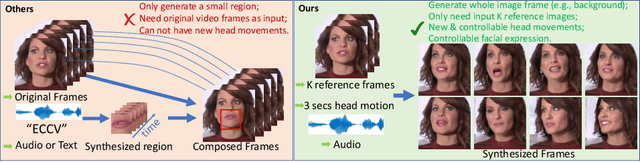
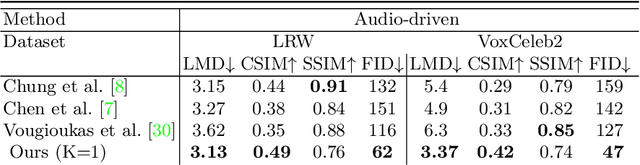
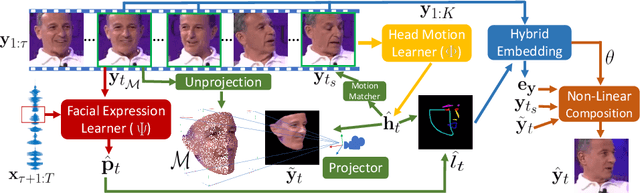
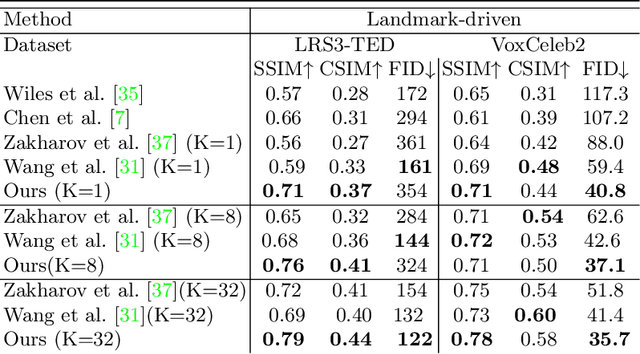
When people deliver a speech, they naturally move heads, and this rhythmic head motion conveys prosodic information. However, generating a lip-synced video while moving head naturally is challenging. While remarkably successful, existing works either generate still talkingface videos or rely on landmark/video frames as sparse/dense mapping guidance to generate head movements, which leads to unrealistic or uncontrollable video synthesis. To overcome the limitations, we propose a 3D-aware generative network along with a hybrid embedding module and a non-linear composition module. Through modeling the head motion and facial expressions1 explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. Thoughtful experiments on several standard benchmarks demonstrate that our method achieves significantly better results than the state-of-the-art methods in both quantitative and qualitative comparisons. The code is available on https://github.com/ lelechen63/Talking-head-Generation-with-Rhythmic-Head-Motion.
Superimposition-guided Facial Reconstruction from Skull
Sep 28, 2018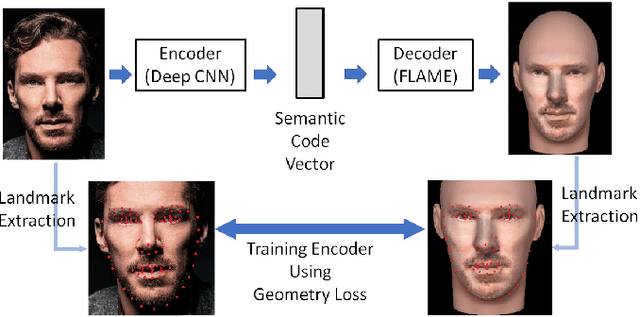
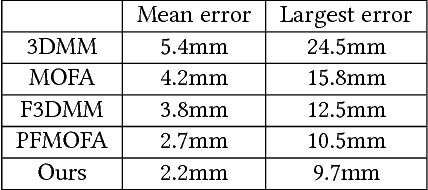
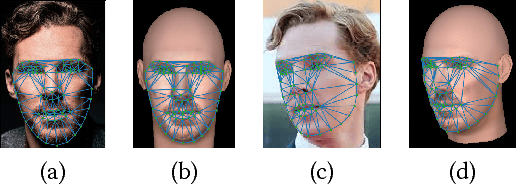

We develop a new algorithm to perform facial reconstruction from a given skull. This technique has forensic application in helping the identification of skeletal remains when other information is unavailable. Unlike most existing strategies that directly reconstruct the face from the skull, we utilize a database of portrait photos to create many face candidates, then perform a superimposition to get a well matched face, and then revise it according to the superimposition. To support this pipeline, we build an effective autoencoder for image-based facial reconstruction, and a generative model for constrained face inpainting. Our experiments have demonstrated that the proposed pipeline is stable and accurate.