 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
A Shared Control Framework for Mobile Robots with Planning-Level Intention Prediction
Nov 12, 2025In mobile robot shared control, effectively understanding human motion intention is critical for seamless human-robot collaboration. This paper presents a novel shared control framework featuring planning-level intention prediction. A path replanning algorithm is designed to adjust the robot's desired trajectory according to inferred human intentions. To represent future motion intentions, we introduce the concept of an intention domain, which serves as a constraint for path replanning. The intention-domain prediction and path replanning problems are jointly formulated as a Markov Decision Process and solved through deep reinforcement learning. In addition, a Voronoi-based human trajectory generation algorithm is developed, allowing the model to be trained entirely in simulation without human participation or demonstration data. Extensive simulations and real-world user studies demonstrate that the proposed method significantly reduces operator workload and enhances safety, without compromising task efficiency compared with existing assistive teleoperation approaches.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
A Learn-Then-Reason Model Towards Generalization in Knowledge Base Question Answering
Jun 20, 2024



Large-scale knowledge bases (KBs) like Freebase and Wikidata house millions of structured knowledge. Knowledge Base Question Answering (KBQA) provides a user-friendly way to access these valuable KBs via asking natural language questions. In order to improve the generalization capabilities of KBQA models, extensive research has embraced a retrieve-then-reason framework to retrieve relevant evidence for logical expression generation. These multi-stage efforts prioritize acquiring external sources but overlook the incorporation of new knowledge into their model parameters. In effect, even advanced language models and retrievers have knowledge boundaries, thereby limiting the generalization capabilities of previous KBQA models. Therefore, this paper develops KBLLaMA, which follows a learn-then-reason framework to inject new KB knowledge into a large language model for flexible end-to-end KBQA. At the core of KBLLaMA, we study (1) how to organize new knowledge about KBQA and (2) how to facilitate the learning of the organized knowledge. Extensive experiments on various KBQA generalization tasks showcase the state-of-the-art performance of KBLLaMA. Especially on the general benchmark GrailQA and domain-specific benchmark Bio-chemical, KBLLaMA respectively derives a performance gain of up to 3.8% and 9.8% compared to the baselines.
Open-World Semi-Supervised Learning for Node Classification
Mar 18, 2024Open-world semi-supervised learning (Open-world SSL) for node classification, that classifies unlabeled nodes into seen classes or multiple novel classes, is a practical but under-explored problem in the graph community. As only seen classes have human labels, they are usually better learned than novel classes, and thus exhibit smaller intra-class variances within the embedding space (named as imbalance of intra-class variances between seen and novel classes). Based on empirical and theoretical analysis, we find the variance imbalance can negatively impact the model performance. Pre-trained feature encoders can alleviate this issue via producing compact representations for novel classes. However, creating general pre-trained encoders for various types of graph data has been proven to be challenging. As such, there is a demand for an effective method that does not rely on pre-trained graph encoders. In this paper, we propose an IMbalance-Aware method named OpenIMA for Open-world semi-supervised node classification, which trains the node classification model from scratch via contrastive learning with bias-reduced pseudo labels. Extensive experiments on seven popular graph benchmarks demonstrate the effectiveness of OpenIMA, and the source code has been available on GitHub.
ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
Feb 21, 2024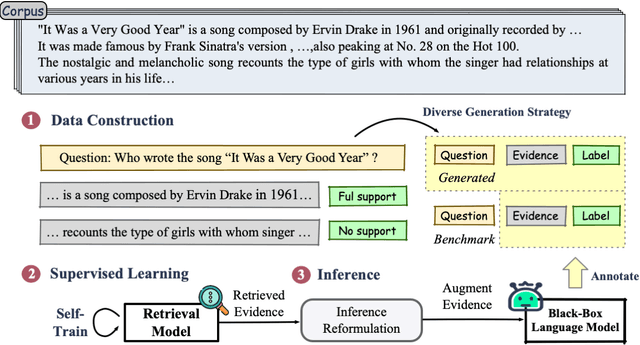
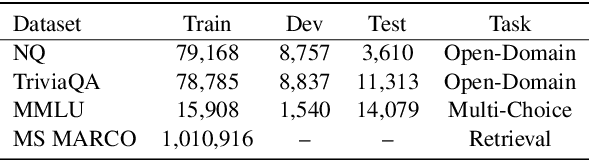

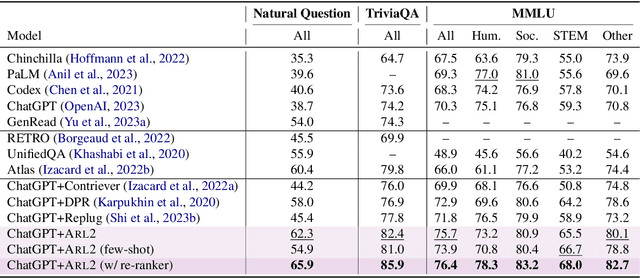
Retrieval-augmented generation enhances large language models (LLMs) by incorporating relevant information from external knowledge sources. This enables LLMs to adapt to specific domains and mitigate hallucinations in knowledge-intensive tasks. However, existing retrievers are often misaligned with LLMs due to their separate training processes and the black-box nature of LLMs. To address this challenge, we propose ARL2, a retriever learning technique that harnesses LLMs as labelers. ARL2 leverages LLMs to annotate and score relevant evidence, enabling learning the retriever from robust LLM supervision. Furthermore, ARL2 uses an adaptive self-training strategy for curating high-quality and diverse relevance data, which can effectively reduce the annotation cost. Extensive experiments demonstrate the effectiveness of ARL2, achieving accuracy improvements of 5.4% on NQ and 4.6% on MMLU compared to the state-of-the-art methods. Additionally, ARL2 exhibits robust transfer learning capabilities and strong zero-shot generalization abilities. Our code will be published at \url{https://github.com/zhanglingxi-cs/ARL2}.
FC-KBQA: A Fine-to-Coarse Composition Framework for Knowledge Base Question Answering
Jun 26, 2023



The generalization problem on KBQA has drawn considerable attention. Existing research suffers from the generalization issue brought by the entanglement in the coarse-grained modeling of the logical expression, or inexecutability issues due to the fine-grained modeling of disconnected classes and relations in real KBs. We propose a Fine-to-Coarse Composition framework for KBQA (FC-KBQA) to both ensure the generalization ability and executability of the logical expression. The main idea of FC-KBQA is to extract relevant fine-grained knowledge components from KB and reformulate them into middle-grained knowledge pairs for generating the final logical expressions. FC-KBQA derives new state-of-the-art performance on GrailQA and WebQSP, and runs 4 times faster than the baseline.
Neural-Symbolic Reasoning on Knowledge Graphs
Oct 29, 2020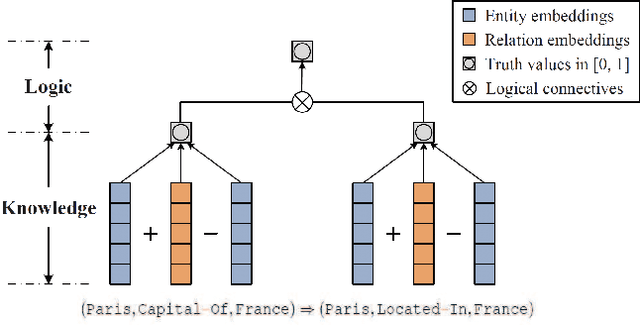

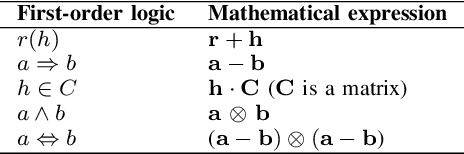
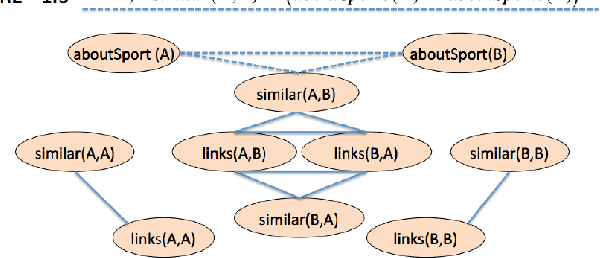
Knowledge graph reasoning is the fundamental component to support machine learning applications such as information extraction, information retrieval and recommendation. Since knowledge graph can be viewed as the discrete symbolic representations of knowledge, reasoning on knowledge graphs can naturally leverage the symbolic techniques. However, symbolic reasoning is intolerant of the ambiguous and noisy data. On the contrary, the recent advances of deep learning promote neural reasoning on knowledge graphs, which is robust to the ambiguous and noisy data, but lacks interpretability compared to symbolic reasoning. Considering the advantages and disadvantages of both methodologies, recent efforts have been made on combining the two reasoning methods. In this survey, we take a thorough look at the development of the symbolic reasoning, neural reasoning and the neural-symbolic reasoning on knowledge graphs. We survey two specific reasoning tasks, knowledge graph completion and question answering on knowledge graphs, and explain them in a unified reasoning framework. We also briefly discuss the future directions for knowledge graph reasoning.