 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOET-X: Memory-efficient LLM Training by Scaling Orthogonal Transformation
Mar 05, 2026Efficient and stable training of large language models (LLMs) remains a core challenge in modern machine learning systems. To address this challenge, Reparameterized Orthogonal Equivalence Training (POET), a spectrum-preserving framework that optimizes each weight matrix through orthogonal equivalence transformation, has been proposed. Although POET provides strong training stability, its original implementation incurs high memory consumption and computational overhead due to intensive matrix multiplications. To overcome these limitations, we introduce POET-X, a scalable and memory-efficient variant that performs orthogonal equivalence transformations with significantly reduced computational cost. POET-X maintains the generalization and stability benefits of POET while achieving substantial improvements in throughput and memory efficiency. In our experiments, POET-X enables the pretraining of billion-parameter LLMs on a single Nvidia H100 GPU, and in contrast, standard optimizers such as AdamW run out of memory under the same settings.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models
Apr 03, 2024The ability of large language models (LLMs) to follow instructions is crucial to real-world applications. Despite recent advances, several studies have highlighted that LLMs struggle when faced with challenging instructions, especially those that include complex constraints, hindering their effectiveness in various tasks. To address this challenge, we introduce Conifer, a novel instruction tuning dataset, designed to enhance LLMs to follow multi-level instructions with complex constraints. Utilizing GPT-4, we curate the dataset by a series of LLM-driven refinement processes to ensure high quality. We also propose a progressive learning scheme that emphasizes an easy-to-hard progression, and learning from process feedback. Models trained with Conifer exhibit remarkable improvements in instruction-following abilities, especially for instructions with complex constraints. On several instruction-following benchmarks, our 7B model outperforms the state-of-the-art open-source 7B models, even exceeds the performance of models 10 times larger on certain metrics. All the code and Conifer dataset are available at https://www.github.com/ConiferLM/Conifer.
Open-World Semi-Supervised Learning for Node Classification
Mar 18, 2024Open-world semi-supervised learning (Open-world SSL) for node classification, that classifies unlabeled nodes into seen classes or multiple novel classes, is a practical but under-explored problem in the graph community. As only seen classes have human labels, they are usually better learned than novel classes, and thus exhibit smaller intra-class variances within the embedding space (named as imbalance of intra-class variances between seen and novel classes). Based on empirical and theoretical analysis, we find the variance imbalance can negatively impact the model performance. Pre-trained feature encoders can alleviate this issue via producing compact representations for novel classes. However, creating general pre-trained encoders for various types of graph data has been proven to be challenging. As such, there is a demand for an effective method that does not rely on pre-trained graph encoders. In this paper, we propose an IMbalance-Aware method named OpenIMA for Open-world semi-supervised node classification, which trains the node classification model from scratch via contrastive learning with bias-reduced pseudo labels. Extensive experiments on seven popular graph benchmarks demonstrate the effectiveness of OpenIMA, and the source code has been available on GitHub.
Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao
Aug 11, 2022

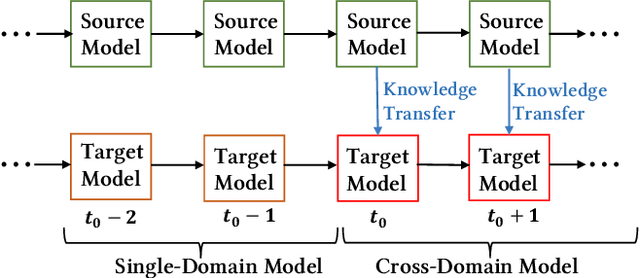
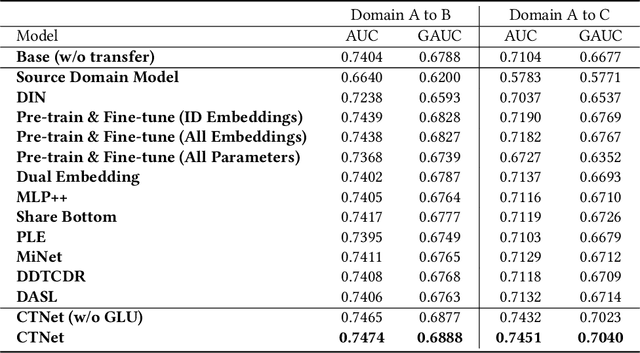
As one of the largest e-commerce platforms in the world, Taobao's recommendation systems (RSs) serve the demands of shopping for hundreds of millions of customers. Click-Through Rate (CTR) prediction is a core component of the RS. One of the biggest characteristics in CTR prediction at Taobao is that there exist multiple recommendation domains where the scales of different domains vary significantly. Therefore, it is crucial to perform cross-domain CTR prediction to transfer knowledge from large domains to small domains to alleviate the data sparsity issue. However, existing cross-domain CTR prediction methods are proposed for static knowledge transfer, ignoring that all domains in real-world RSs are continually time-evolving. In light of this, we present a necessary but novel task named Continual Transfer Learning (CTL), which transfers knowledge from a time-evolving source domain to a time-evolving target domain. In this work, we propose a simple and effective CTL model called CTNet to solve the problem of continual cross-domain CTR prediction at Taobao, and CTNet can be trained efficiently. Particularly, CTNet considers an important characteristic in the industry that models has been continually well-trained for a very long time. So CTNet aims to fully utilize all the well-trained model parameters in both source domain and target domain to avoid losing historically acquired knowledge, and only needs incremental target domain data for training to guarantee efficiency. Extensive offline experiments and online A/B testing at Taobao demonstrate the efficiency and effectiveness of CTNet. CTNet is now deployed online in the recommender systems of Taobao, serving the main traffic of hundreds of millions of active users.
Learning towards Minimum Hyperspherical Energy
Oct 27, 2018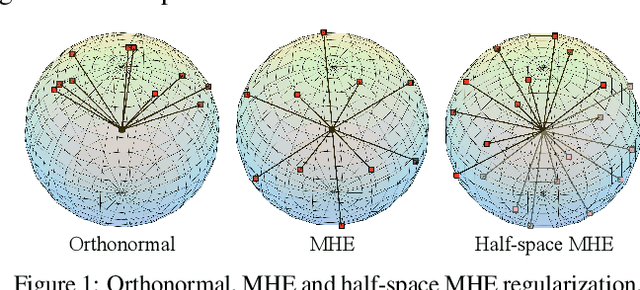
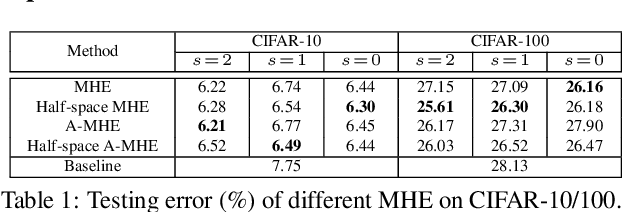
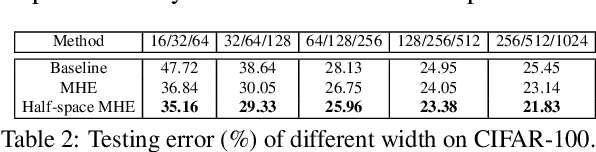
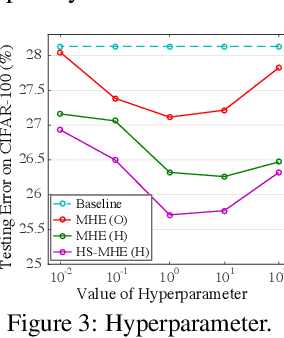
Neural networks are a powerful class of nonlinear functions that can be trained end-to-end on various applications. While the over-parametrization nature in many neural networks renders the ability to fit complex functions and the strong representation power to handle challenging tasks, it also leads to highly correlated neurons that can hurt the generalization ability and incur unnecessary computation cost. As a result, how to regularize the network to avoid undesired representation redundancy becomes an important issue. To this end, we draw inspiration from a well-known problem in physics -- Thomson problem, where one seeks to find a state that distributes N electrons on a unit sphere as evenly as possible with minimum potential energy. In light of this intuition, we reduce the redundancy regularization problem to generic energy minimization, and propose a minimum hyperspherical energy (MHE) objective as generic regularization for neural networks. We also propose a few novel variants of MHE, and provide some insights from a theoretical point of view. Finally, we apply neural networks with MHE regularization to several challenging tasks. Extensive experiments demonstrate the effectiveness of our intuition, by showing the superior performance with MHE regularization.