 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Dimensional Scaling via Accelerated Alternating Projections
Jan 04, 2025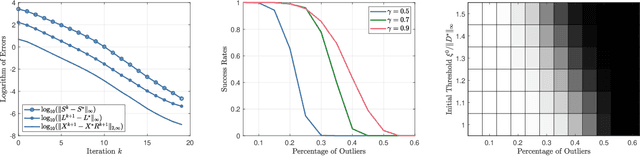
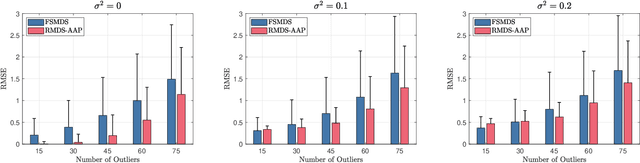
We consider the robust multi-dimensional scaling (RMDS) problem in this paper. The goal is to localize point locations from pairwise distances that may be corrupted by outliers. Inspired by classic MDS theories, and nonconvex works for the robust principal component analysis (RPCA) problem, we propose an alternating projection based algorithm that is further accelerated by the tangent space projection technique. For the proposed algorithm, if the outliers are sparse enough, we can establish linear convergence of the reconstructed points to the original points after centering and rotation alignment. Numerical experiments verify the state-of-the-art performances of the proposed algorithm.
Leave-One-Out Analysis for Nonconvex Robust Matrix Completion with General Thresholding Functions
Jul 28, 2024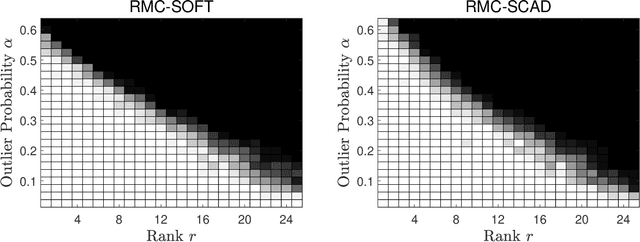
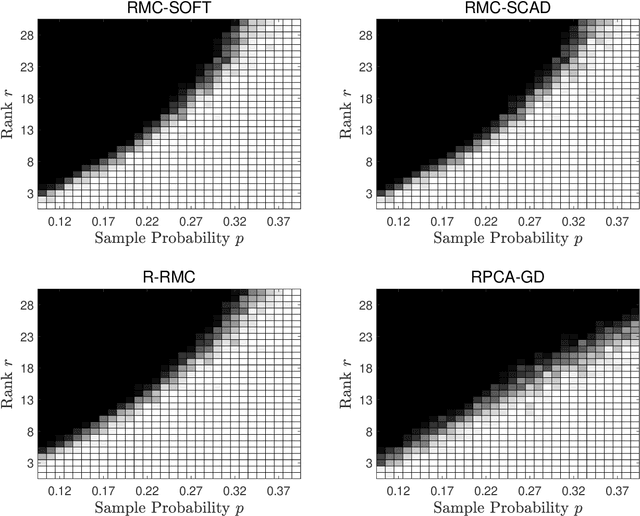
We study the problem of robust matrix completion (RMC), where the partially observed entries of an underlying low-rank matrix is corrupted by sparse noise. Existing analysis of the non-convex methods for this problem either requires the explicit but empirically redundant regularization in the algorithm or requires sample splitting in the analysis. In this paper, we consider a simple yet efficient nonconvex method which alternates between a projected gradient step for the low-rank part and a thresholding step for the sparse noise part. Inspired by leave-one out analysis for low rank matrix completion, it is established that the method can achieve linear convergence for a general class of thresholding functions, including for example soft-thresholding and SCAD. To the best of our knowledge, this is the first leave-one-out analysis on a nonconvex method for RMC. Additionally, when applying our result to low rank matrix completion, it improves the sampling complexity of existing result for the singular value projection method.
Outlier Detection Using Generative Models with Theoretical Performance Guarantees
Oct 16, 2023

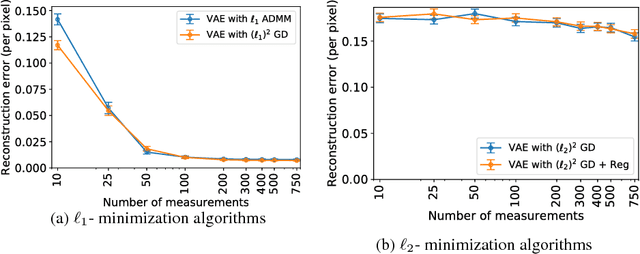
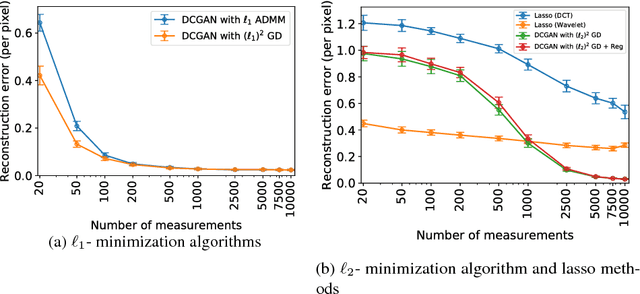
This paper considers the problem of recovering signals modeled by generative models from linear measurements contaminated with sparse outliers. We propose an outlier detection approach for reconstructing the ground-truth signals modeled by generative models under sparse outliers. We establish theoretical recovery guarantees for reconstruction of signals using generative models in the presence of outliers, giving lower bounds on the number of correctable outliers. Our results are applicable to both linear generator neural networks and the nonlinear generator neural networks with an arbitrary number of layers. We propose an iterative alternating direction method of multipliers (ADMM) algorithm for solving the outlier detection problem via $\ell_1$ norm minimization, and a gradient descent algorithm for solving the outlier detection problem via squared $\ell_1$ norm minimization. We conduct extensive experiments using variational auto-encoder and deep convolutional generative adversarial networks, and the experimental results show that the signals can be successfully reconstructed under outliers using our approach. Our approach outperforms the traditional Lasso and $\ell_2$ minimization approach.
Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao
Aug 11, 2022

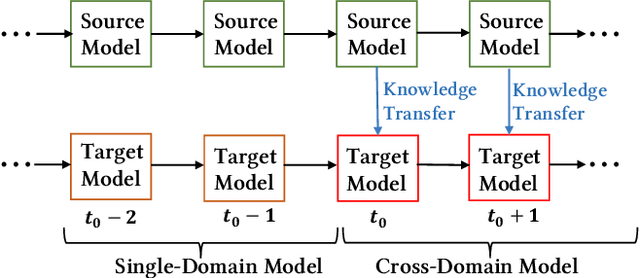
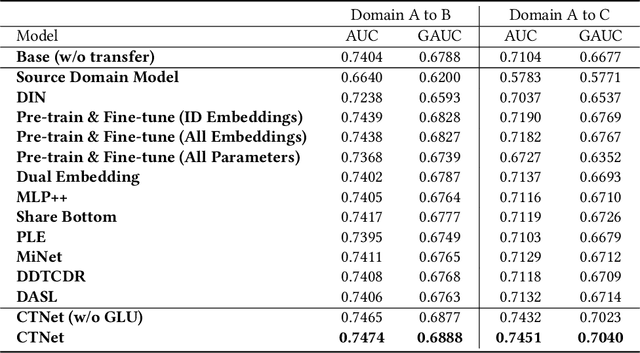
As one of the largest e-commerce platforms in the world, Taobao's recommendation systems (RSs) serve the demands of shopping for hundreds of millions of customers. Click-Through Rate (CTR) prediction is a core component of the RS. One of the biggest characteristics in CTR prediction at Taobao is that there exist multiple recommendation domains where the scales of different domains vary significantly. Therefore, it is crucial to perform cross-domain CTR prediction to transfer knowledge from large domains to small domains to alleviate the data sparsity issue. However, existing cross-domain CTR prediction methods are proposed for static knowledge transfer, ignoring that all domains in real-world RSs are continually time-evolving. In light of this, we present a necessary but novel task named Continual Transfer Learning (CTL), which transfers knowledge from a time-evolving source domain to a time-evolving target domain. In this work, we propose a simple and effective CTL model called CTNet to solve the problem of continual cross-domain CTR prediction at Taobao, and CTNet can be trained efficiently. Particularly, CTNet considers an important characteristic in the industry that models has been continually well-trained for a very long time. So CTNet aims to fully utilize all the well-trained model parameters in both source domain and target domain to avoid losing historically acquired knowledge, and only needs incremental target domain data for training to guarantee efficiency. Extensive offline experiments and online A/B testing at Taobao demonstrate the efficiency and effectiveness of CTNet. CTNet is now deployed online in the recommender systems of Taobao, serving the main traffic of hundreds of millions of active users.
An End-to-End Cascaded Image Deraining and Object Detection Neural Network
Feb 23, 2022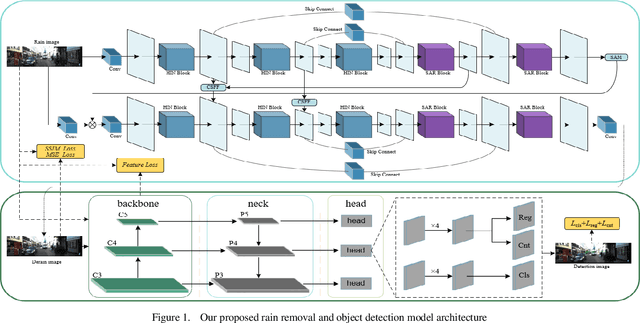
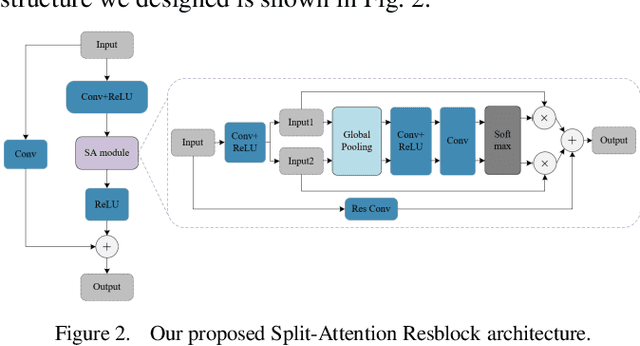

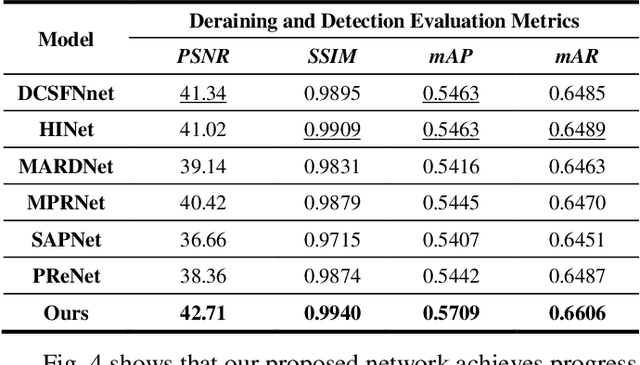
While the deep learning-based image deraining methods have made great progress in recent years, there are two major shortcomings in their application in real-world situations. Firstly, the gap between the low-level vision task represented by rain removal and the high-level vision task represented by object detection is significant, and the low-level vision task can hardly contribute to the high-level vision task. Secondly, the quality of the deraining dataset needs to be improved. In fact, the rain lines in many baselines have a large gap with the real rain lines, and the resolution of the deraining dataset images is generally not ideally. Meanwhile, there are few common datasets for both the low-level vision task and the high-level vision task. In this paper, we explore the combination of the low-level vision task with the high-level vision task. Specifically, we propose an end-to-end object detection network for reducing the impact of rainfall, which consists of two cascaded networks, an improved image deraining network and an object detection network, respectively. We also design the components of the loss function to accommodate the characteristics of the different sub-networks. We then propose a dataset based on the KITTI dataset for rainfall removal and object detection, on which our network surpasses the state-of-the-art with a significant improvement in metrics. Besides, our proposed network is measured on driving videos collected by self-driving vehicles and shows positive results for rain removal and object detection.
Modular Transfer Learning with Transition Mismatch Compensation for Excessive Disturbance Rejection
Jul 29, 2020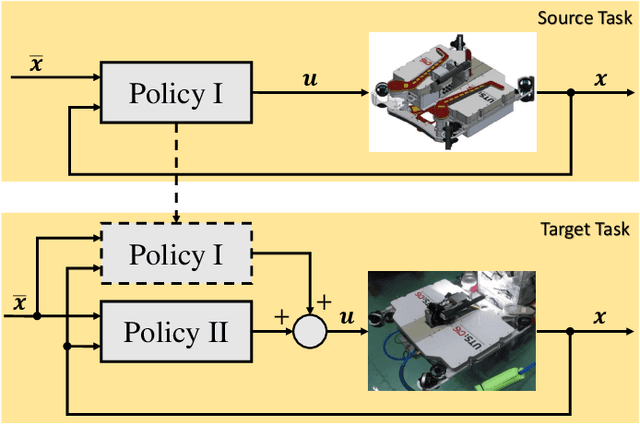
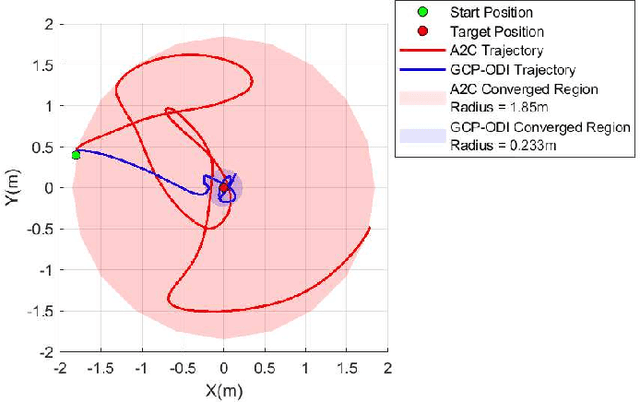
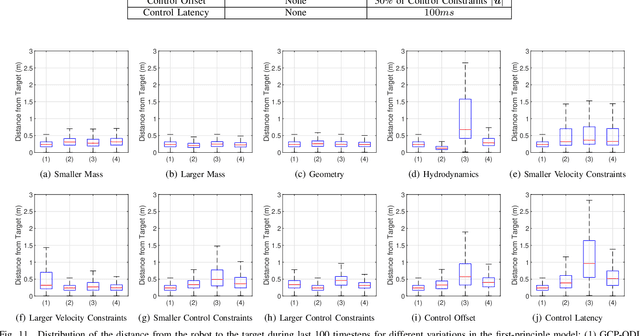
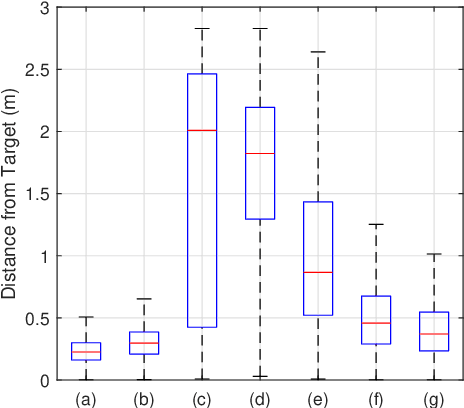
Underwater robots in shallow waters usually suffer from strong wave forces, which may frequently exceed robot's control constraints. Learning-based controllers are suitable for disturbance rejection control, but the excessive disturbances heavily affect the state transition in Markov Decision Process (MDP) or Partially Observable Markov Decision Process (POMDP). Also, pure learning procedures on targeted system may encounter damaging exploratory actions or unpredictable system variations, and training exclusively on a prior model usually cannot address model mismatch from the targeted system. In this paper, we propose a transfer learning framework that adapts a control policy for excessive disturbance rejection of an underwater robot under dynamics model mismatch. A modular network of learning policies is applied, composed of a Generalized Control Policy (GCP) and an Online Disturbance Identification Model (ODI). GCP is first trained over a wide array of disturbance waveforms. ODI then learns to use past states and actions of the system to predict the disturbance waveforms which are provided as input to GCP (along with the system state). A transfer reinforcement learning algorithm using Transition Mismatch Compensation (TMC) is developed based on the modular architecture, that learns an additional compensatory policy through minimizing mismatch of transitions predicted by the two dynamics models of the source and target tasks. We demonstrated on a pose regulation task in simulation that TMC is able to successfully reject the disturbances and stabilize the robot under an empirical model of the robot system, meanwhile improve sample efficiency.
Fast and Robust Spectrally Sparse Signal Recovery: A Provable Non-Convex Approach via Robust Low-Rank Hankel Matrix Reconstruction
Oct 13, 2019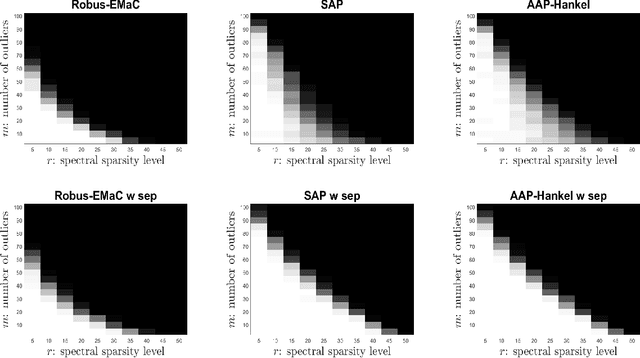
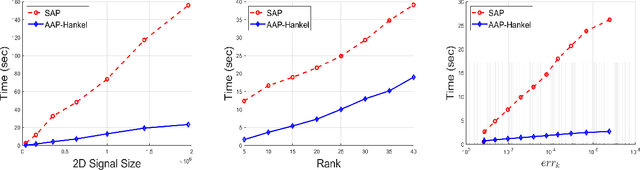
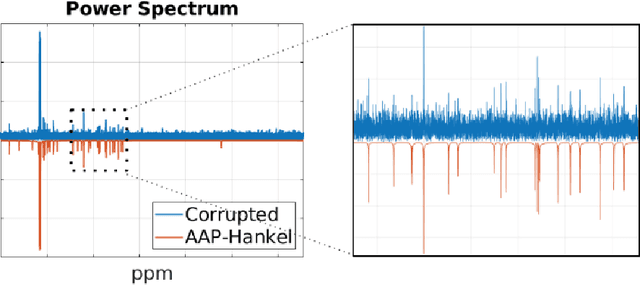
Consider a spectrally sparse signal $\boldsymbol{x}$ that consists of $r$ complex sinusoids with or without damping. We study the robust recovery problem for the spectrally sparse signal under the fully observed setting, which is about recovering $\boldsymbol{x}$ and a sparse corruption vector $\boldsymbol{s}$ from their sum $\boldsymbol{z}=\boldsymbol{x}+\boldsymbol{s}$. In this paper, we exploit the low-rank property of the Hankel matrix constructed from $\boldsymbol{x}$, and develop an efficient non-convex algorithm, coined Accelerated Alternating Projections for Robust Low-Rank Hankel Matrix Reconstruction (AAP-Hankel). The high computational efficiency and low space complexity of AAP-Hankel are achieved by fast computations involving structured matrices, and a subspace projection method for accelerated low-rank approximation. Theoretical recovery guarantee with a linear convergence rate has been established for AAP-Hankel. Empirical performance comparisons on synthetic and real-world datasets demonstrate the computational advantages of AAP-Hankel, in both efficiency and robustness aspects.
DOB-Net: Actively Rejecting Unknown Excessive Time-Varying Disturbances
Jul 10, 2019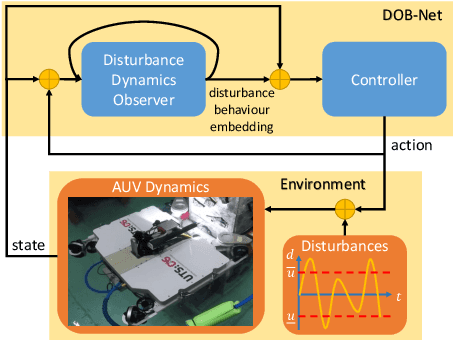
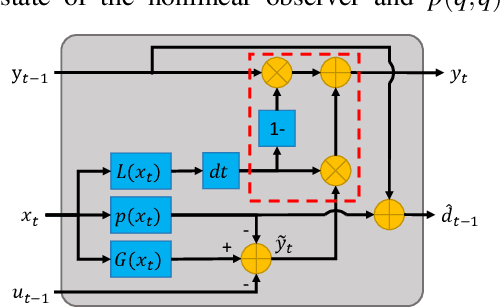
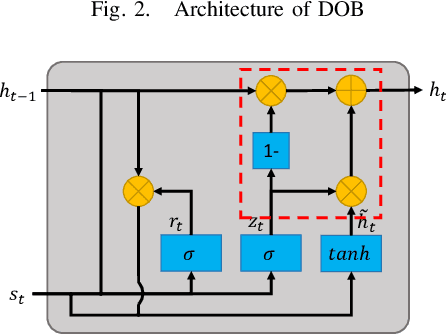
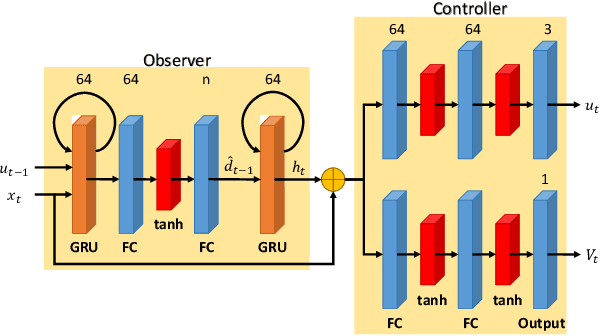
This paper presents an observer-integrated Reinforcement Learning (RL) approach, called Disturbance OBserver Network (DOB-Net), for robots operating in environments where disturbances are unknown and time-varying, and may frequently exceed robot control capabilities. The DOB-Net integrates a disturbance dynamics observer network and a controller network. Originated from classical DOB mechanisms, the observer is built and enhanced via Recurrent Neural Networks (RNNs), encoding estimation of past values and prediction of future values of unknown disturbances in RNN hidden state. Such encoding allows the controller generate optimal control signals to actively reject disturbances, under the constraints of robot control capabilities. The observer and the controller are jointly learned within policy optimization by advantage actor critic. Numerical simulations on position regulation tasks have demonstrated that the proposed DOB-Net significantly outperforms a canonical feedback controller and classical RL algorithms.
Blind Hyperspectral-Multispectral Image Fusion via Graph Laplacian Regularization
Feb 21, 2019


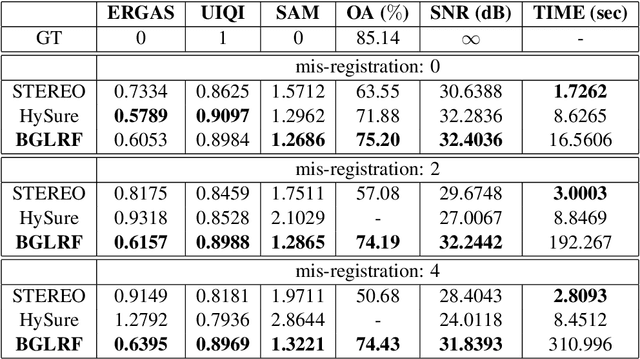
Fusing a low-resolution hyperspectral image (HSI) and a high-resolution multispectral image (MSI) of the same scene leads to a super-resolution image (SRI), which is information rich spatially and spectrally. In this paper, we super-resolve the HSI using the graph Laplacian defined on the MSI. Unlike many existing works, we don't assume prior knowledge about the spatial degradation from SRI to HSI, nor a perfectly aligned HSI and MSI pair. Our algorithm progressively alternates between finding the blur kernel and fusing HSI with MSI, generating accurate estimations of the blur kernel and the SRI at convergence. Experiments on various datasets demonstrate the advantages of the proposed algorithm in the quality of fusion and its capability in dealing with unknown spatial degradation.
Outlier Detection using Generative Models with Theoretical Performance Guarantees
Oct 26, 2018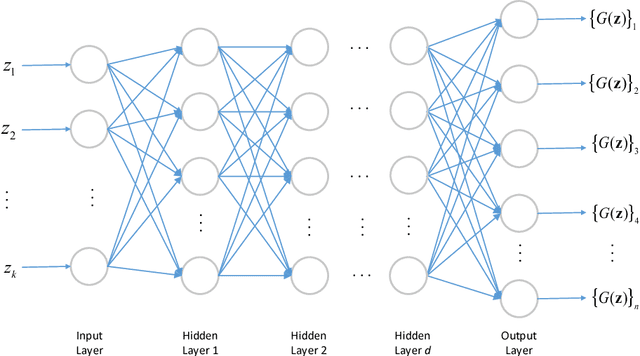

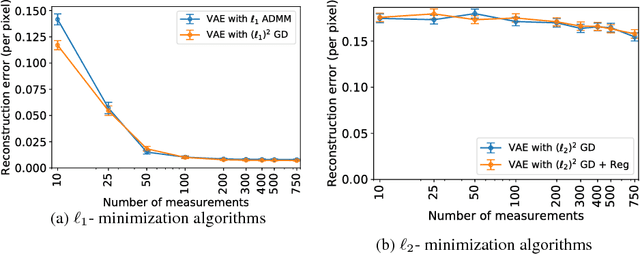
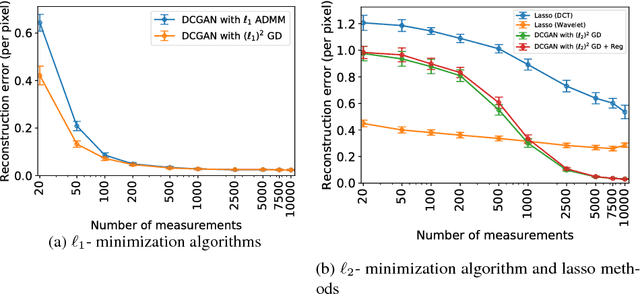
This paper considers the problem of recovering signals from compressed measurements contaminated with sparse outliers, which has arisen in many applications. In this paper, we propose a generative model neural network approach for reconstructing the ground truth signals under sparse outliers. We propose an iterative alternating direction method of multipliers (ADMM) algorithm for solving the outlier detection problem via $\ell_1$ norm minimization, and a gradient descent algorithm for solving the outlier detection problem via squared $\ell_1$ norm minimization. We establish the recovery guarantees for reconstruction of signals using generative models in the presence of outliers, and give an upper bound on the number of outliers allowed for recovery. Our results are applicable to both the linear generator neural network and the nonlinear generator neural network with an arbitrary number of layers. We conduct extensive experiments using variational auto-encoder and deep convolutional generative adversarial networks, and the experimental results show that the signals can be successfully reconstructed under outliers using our approach. Our approach outperforms the traditional Lasso and $\ell_2$ minimization approach.