 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
RUSSO: Robust Underwater SLAM with Sonar Optimization against Visual Degradation
Mar 03, 2025



Visual degradation in underwater environments poses unique and significant challenges, which distinguishes underwater SLAM from popular vision-based SLAM on the ground. In this paper, we propose RUSSO, a robust underwater SLAM system which fuses stereo camera, inertial measurement unit (IMU), and imaging sonar to achieve robust and accurate localization in challenging underwater environments for 6 degrees of freedom (DoF) estimation. During visual degradation, the system is reduced to a sonar-inertial system estimating 3-DoF poses. The sonar pose estimation serves as a strong prior for IMU propagation, thereby enhancing the reliability of pose estimation with IMU propagation. Additionally, we propose a SLAM initialization method that leverages the imaging sonar to counteract the lack of visual features during the initialization stage of SLAM. We extensively validate RUSSO through experiments in simulator, pool, and sea scenarios. The results demonstrate that RUSSO achieves better robustness and localization accuracy compared to the state-of-the-art visual-inertial SLAM systems, especially in visually challenging scenarios. To the best of our knowledge, this is the first time fusing stereo camera, IMU, and imaging sonar to realize robust underwater SLAM against visual degradation.
CIRCUIT: A Benchmark for Circuit Interpretation and Reasoning Capabilities of LLMs
Feb 11, 2025The role of Large Language Models (LLMs) has not been extensively explored in analog circuit design, which could benefit from a reasoning-based approach that transcends traditional optimization techniques. In particular, despite their growing relevance, there are no benchmarks to assess LLMs' reasoning capability about circuits. Therefore, we created the CIRCUIT dataset consisting of 510 question-answer pairs spanning various levels of analog-circuit-related subjects. The best-performing model on our dataset, GPT-4o, achieves 48.04% accuracy when evaluated on the final numerical answer. To evaluate the robustness of LLMs on our dataset, we introduced a unique feature that enables unit-test-like evaluation by grouping questions into unit tests. In this case, GPT-4o can only pass 27.45% of the unit tests, highlighting that the most advanced LLMs still struggle with understanding circuits, which requires multi-level reasoning, particularly when involving circuit topologies. This circuit-specific benchmark highlights LLMs' limitations, offering valuable insights for advancing their application in analog integrated circuit design.
MPCViT: Searching for MPC-friendly Vision Transformer with Heterogeneous Attention
Nov 25, 2022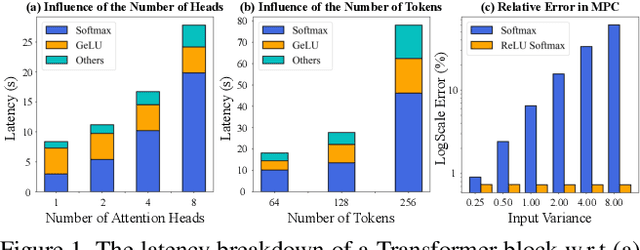

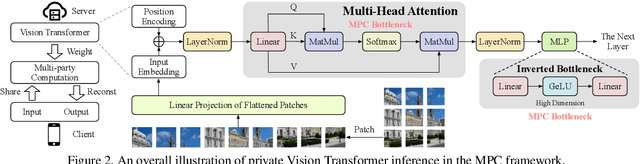
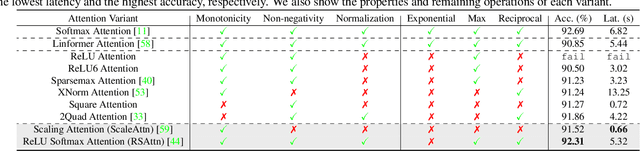
Secure multi-party computation (MPC) enables computation directly on encrypted data on non-colluding untrusted servers and protects both data and model privacy in deep learning inference. However, existing neural network (NN) architectures, including Vision Transformers (ViTs), are not designed or optimized for MPC protocols and incur significant latency overhead due to the Softmax function in the multi-head attention (MHA). In this paper, we propose an MPC-friendly ViT, dubbed MPCViT, to enable accurate yet efficient ViT inference in MPC. We systematically compare different attention variants in MPC and propose a heterogeneous attention search space, which combines the high-accuracy and MPC-efficient attentions with diverse structure granularities. We further propose a simple yet effective differentiable neural architecture search (NAS) algorithm for fast ViT optimization. MPCViT significantly outperforms prior-art ViT variants in MPC. With the proposed NAS algorithm, our extensive experiments demonstrate that MPCViT achieves 7.9x and 2.8x latency reduction with better accuracy compared to Linformer and MPCFormer on the Tiny-ImageNet dataset, respectively. Further, with proper knowledge distillation (KD), MPCViT even achieves 1.9% better accuracy compared to the baseline ViT with 9.9x latency reduction on the Tiny-ImageNet dataset.
Safe Multi-Agent Reinforcement Learning through Decentralized Multiple Control Barrier Functions
Mar 23, 2021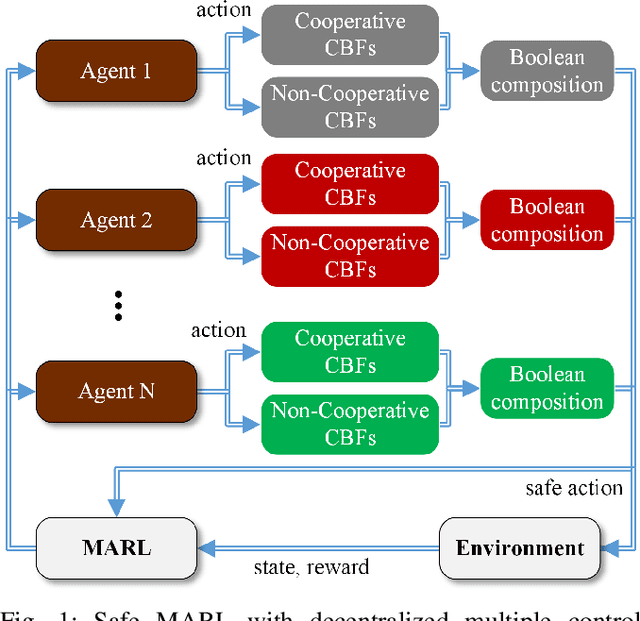
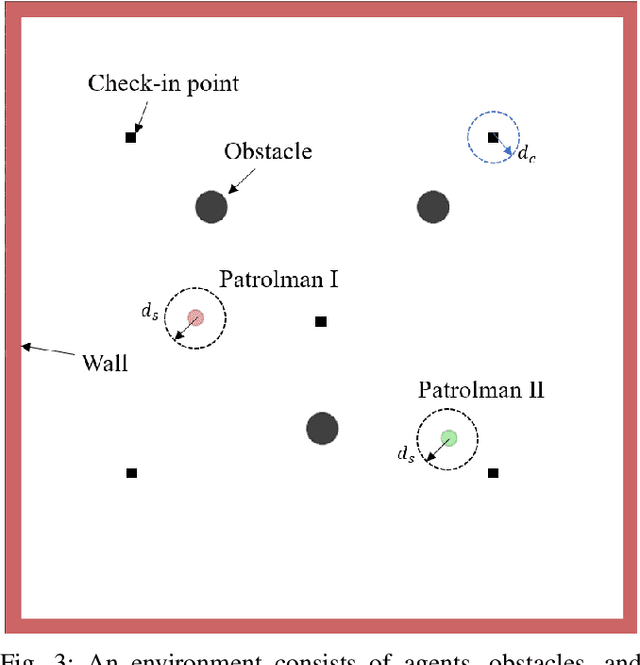
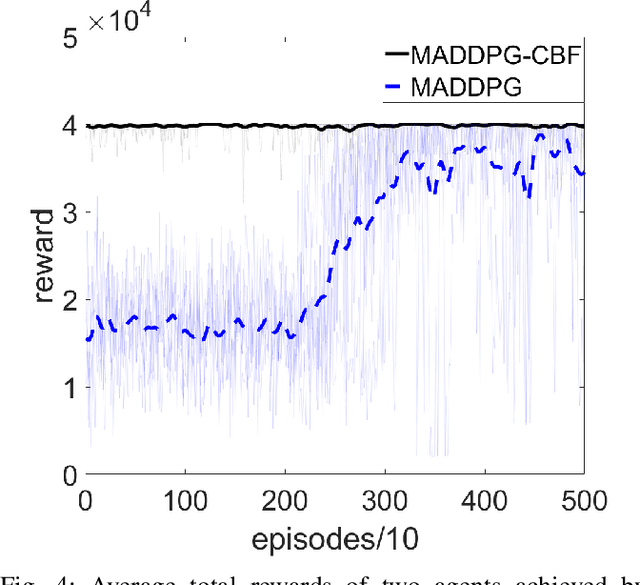
Multi-Agent Reinforcement Learning (MARL) algorithms show amazing performance in simulation in recent years, but placing MARL in real-world applications may suffer safety problems. MARL with centralized shields was proposed and verified in safety games recently. However, centralized shielding approaches can be infeasible in several real-world multi-agent applications that involve non-cooperative agents or communication delay. Thus, we propose to combine MARL with decentralized Control Barrier Function (CBF) shields based on available local information. We establish a safe MARL framework with decentralized multiple CBFs and develop Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to Multi-Agent Deep Deterministic Policy Gradient with decentralized multiple Control Barrier Functions (MADDPG-CBF). Based on a collision-avoidance problem that includes not only cooperative agents but obstacles, we demonstrate the construction of multiple CBFs with safety guarantees in theory. Experiments are conducted and experiment results verify that the proposed safe MARL framework can guarantee the safety of agents included in MARL.
Modular Transfer Learning with Transition Mismatch Compensation for Excessive Disturbance Rejection
Jul 29, 2020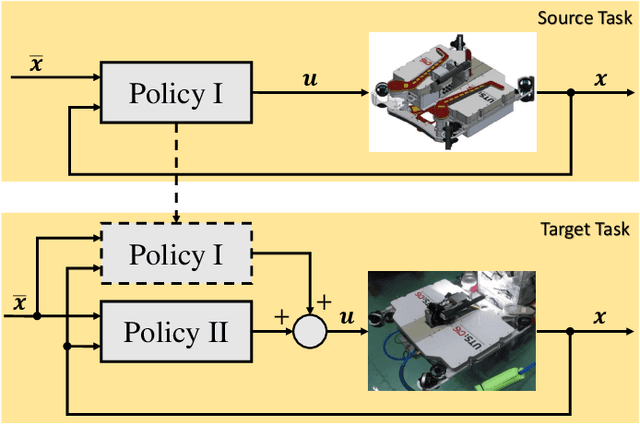
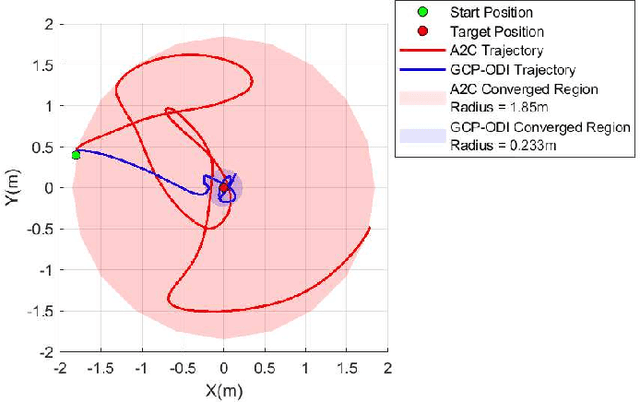
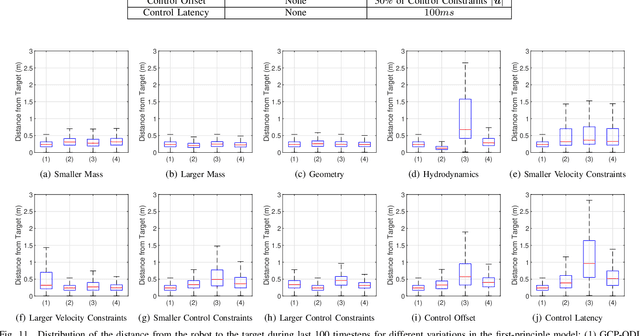
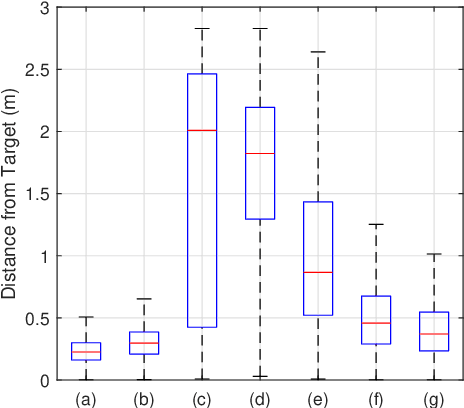
Underwater robots in shallow waters usually suffer from strong wave forces, which may frequently exceed robot's control constraints. Learning-based controllers are suitable for disturbance rejection control, but the excessive disturbances heavily affect the state transition in Markov Decision Process (MDP) or Partially Observable Markov Decision Process (POMDP). Also, pure learning procedures on targeted system may encounter damaging exploratory actions or unpredictable system variations, and training exclusively on a prior model usually cannot address model mismatch from the targeted system. In this paper, we propose a transfer learning framework that adapts a control policy for excessive disturbance rejection of an underwater robot under dynamics model mismatch. A modular network of learning policies is applied, composed of a Generalized Control Policy (GCP) and an Online Disturbance Identification Model (ODI). GCP is first trained over a wide array of disturbance waveforms. ODI then learns to use past states and actions of the system to predict the disturbance waveforms which are provided as input to GCP (along with the system state). A transfer reinforcement learning algorithm using Transition Mismatch Compensation (TMC) is developed based on the modular architecture, that learns an additional compensatory policy through minimizing mismatch of transitions predicted by the two dynamics models of the source and target tasks. We demonstrated on a pose regulation task in simulation that TMC is able to successfully reject the disturbances and stabilize the robot under an empirical model of the robot system, meanwhile improve sample efficiency.
A2: Extracting Cyclic Switchings from DOB-nets for Rejecting Excessive Disturbances
Nov 01, 2019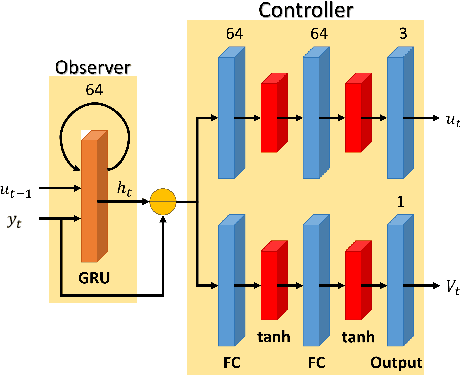

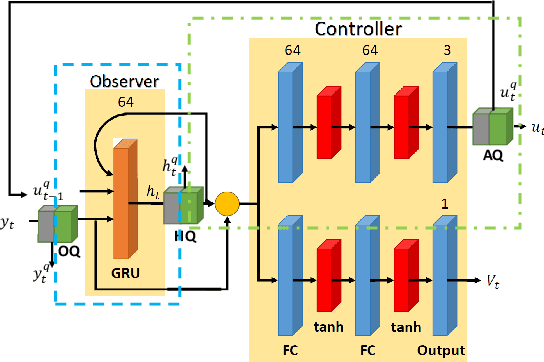
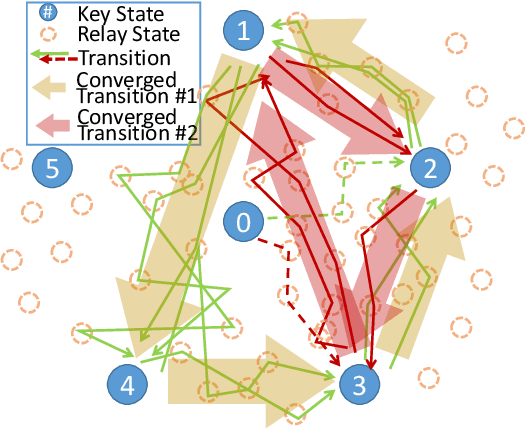
Reinforcement Learning (RL) is limited in practice by its gray-box nature, which is responsible for insufficient trustiness from users, unsatisfied interpretation for human intervention, inadequate analysis for future improvement, etc. This paper seeks to partially characterize the interplay between dynamical environments and the DOB-net. The DOB-net obtained from RL solves a set of Partially Observable Markovian Decision Processes (POMDPs). The transition function of each POMDP is largely determined by the environments, which are excessive external disturbances in this research. This paper proposes an Attention-based Abstraction (A${}^2$) approach to extract a finite-state automaton, referred to as a Key Moore Machine Network (KMMN), to capture the switching mechanisms exhibited by the DOB-net in dealing with multiple such POMDPs. This approach first quantizes the controlled platform by learning continuous-discrete interfaces. Then it extracts the KMMN by finding the key hidden states and transitions that attract sufficient attention from the DOB-net. Within the resultant KMMN, this study found three patterns of cyclic switchings (between key hidden states), showing controls near their saturation are synchronized with unknown disturbances. Interestingly, the found switching mechanism has appeared previously in the design of hybrid control for often-saturated systems. It is further interpreted via an analogy to the discrete-event subsystem in the hybrid control.
DOB-Net: Actively Rejecting Unknown Excessive Time-Varying Disturbances
Jul 10, 2019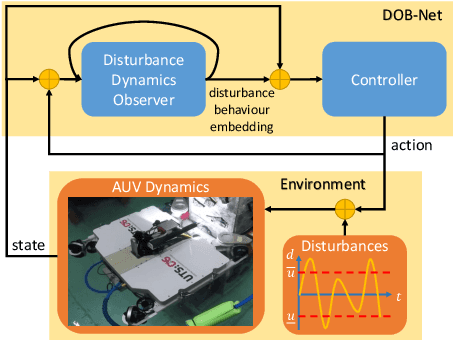
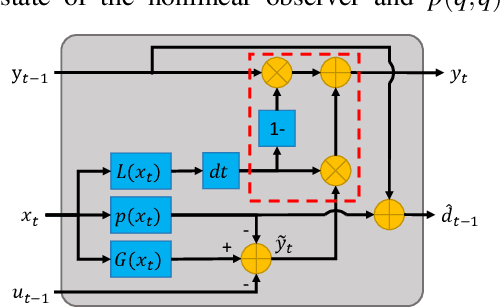
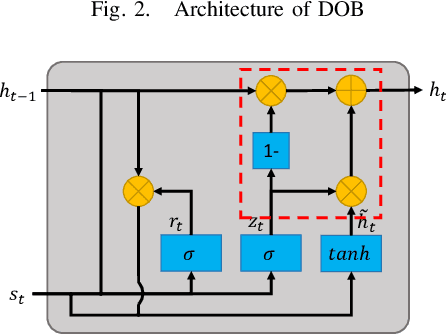
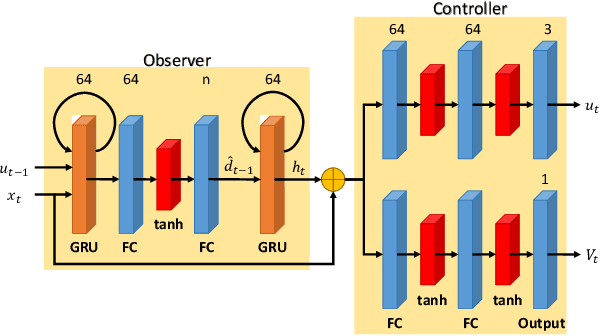
This paper presents an observer-integrated Reinforcement Learning (RL) approach, called Disturbance OBserver Network (DOB-Net), for robots operating in environments where disturbances are unknown and time-varying, and may frequently exceed robot control capabilities. The DOB-Net integrates a disturbance dynamics observer network and a controller network. Originated from classical DOB mechanisms, the observer is built and enhanced via Recurrent Neural Networks (RNNs), encoding estimation of past values and prediction of future values of unknown disturbances in RNN hidden state. Such encoding allows the controller generate optimal control signals to actively reject disturbances, under the constraints of robot control capabilities. The observer and the controller are jointly learned within policy optimization by advantage actor critic. Numerical simulations on position regulation tasks have demonstrated that the proposed DOB-Net significantly outperforms a canonical feedback controller and classical RL algorithms.