 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgPETL: Parameter-Efficient Image-to-Surgical-Video Transfer Learning for Surgical Phase Recognition
Sep 30, 2024Capitalizing on image-level pre-trained models for various downstream tasks has recently emerged with promising performance. However, the paradigm of "image pre-training followed by video fine-tuning" for high-dimensional video data inevitably poses significant performance bottlenecks. Furthermore, in the medical domain, many surgical video tasks encounter additional challenges posed by the limited availability of video data and the necessity for comprehensive spatial-temporal modeling. Recently, Parameter-Efficient Image-to-Video Transfer Learning has emerged as an efficient and effective paradigm for video action recognition tasks, which employs image-level pre-trained models with promising feature transferability and involves cross-modality temporal modeling with minimal fine-tuning. Nevertheless, the effectiveness and generalizability of this paradigm within intricate surgical domain remain unexplored. In this paper, we delve into a novel problem of efficiently adapting image-level pre-trained models to specialize in fine-grained surgical phase recognition, termed as Parameter-Efficient Image-to-Surgical-Video Transfer Learning. Firstly, we develop a parameter-efficient transfer learning benchmark SurgPETL for surgical phase recognition, and conduct extensive experiments with three advanced methods based on ViTs of two distinct scales pre-trained on five large-scale natural and medical datasets. Then, we introduce the Spatial-Temporal Adaptation module, integrating a standard spatial adapter with a novel temporal adapter to capture detailed spatial features and establish connections across temporal sequences for robust spatial-temporal modeling. Extensive experiments on three challenging datasets spanning various surgical procedures demonstrate the effectiveness of SurgPETL with STA.
MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning
Apr 23, 2024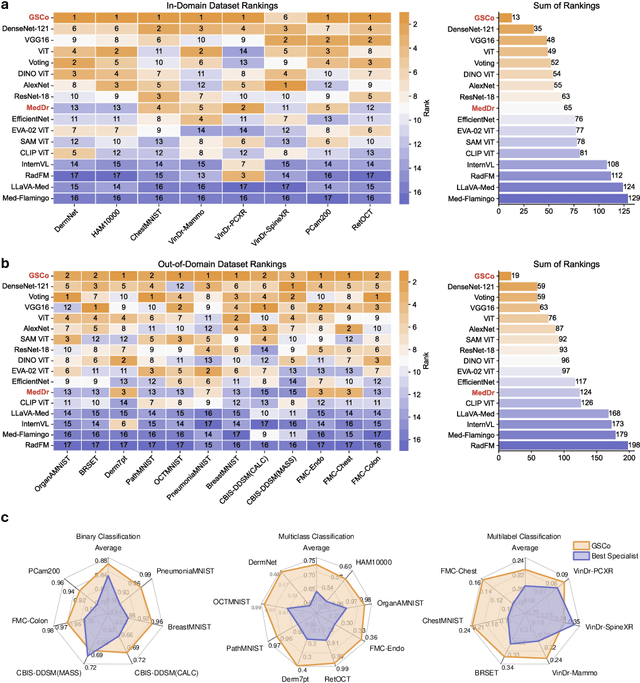

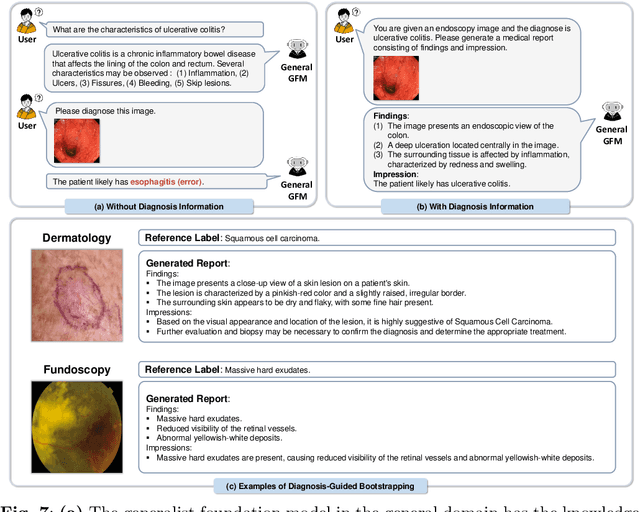
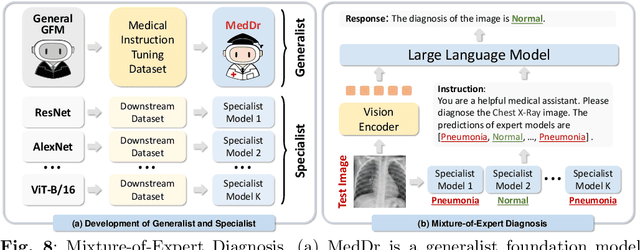
The rapid advancement of large-scale vision-language models has showcased remarkable capabilities across various tasks. However, the lack of extensive and high-quality image-text data in medicine has greatly hindered the development of large-scale medical vision-language models. In this work, we present a diagnosis-guided bootstrapping strategy that exploits both image and label information to construct vision-language datasets. Based on the constructed dataset, we developed MedDr, a generalist foundation model for healthcare capable of handling diverse medical data modalities, including radiology, pathology, dermatology, retinography, and endoscopy. Moreover, during inference, we propose a simple but effective retrieval-augmented medical diagnosis strategy, which enhances the model's generalization ability. Extensive experiments on visual question answering, medical report generation, and medical image diagnosis demonstrate the superiority of our method.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024



Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
JOINEDTrans: Prior Guided Multi-task Transformer for Joint Optic Disc/Cup Segmentation and Fovea Detection
May 19, 2023



Deep learning-based image segmentation and detection models have largely improved the efficiency of analyzing retinal landmarks such as optic disc (OD), optic cup (OC), and fovea. However, factors including ophthalmic disease-related lesions and low image quality issues may severely complicate automatic OD/OC segmentation and fovea detection. Most existing works treat the identification of each landmark as a single task, and take into account no prior information. To address these issues, we propose a prior guided multi-task transformer framework for joint OD/OC segmentation and fovea detection, named JOINEDTrans. JOINEDTrans effectively combines various spatial features of the fundus images, relieving the structural distortions induced by lesions and other imaging issues. It contains a segmentation branch and a detection branch. To be noted, we employ an encoder pretrained in a vessel segmentation task to effectively exploit the positional relationship among vessel, OD/OC, and fovea, successfully incorporating spatial prior into the proposed JOINEDTrans framework. There are a coarse stage and a fine stage in JOINEDTrans. In the coarse stage, OD/OC coarse segmentation and fovea heatmap localization are obtained through a joint segmentation and detection module. In the fine stage, we crop regions of interest for subsequent refinement and use predictions obtained in the coarse stage to provide additional information for better performance and faster convergence. Experimental results demonstrate that JOINEDTrans outperforms existing state-of-the-art methods on the publicly available GAMMA, REFUGE, and PALM fundus image datasets. We make our code available at https://github.com/HuaqingHe/JOINEDTrans
Uni4Eye: Unified 2D and 3D Self-supervised Pre-training via Masked Image Modeling Transformer for Ophthalmic Image Classification
Mar 12, 2022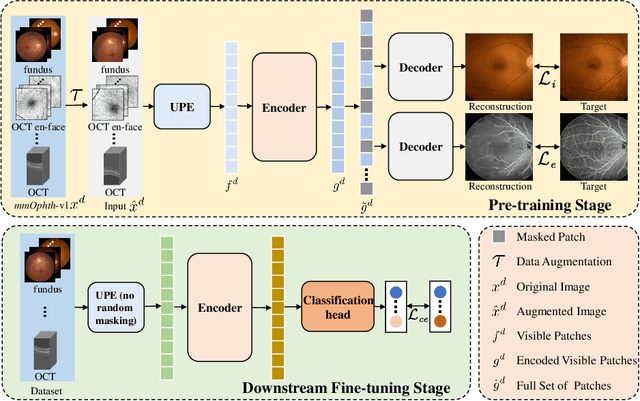

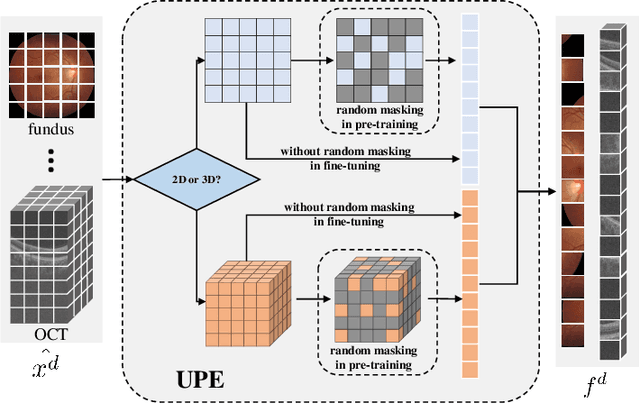
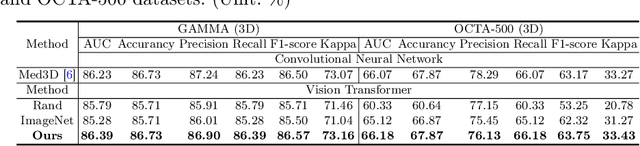
A large-scale labeled dataset is a key factor for the success of supervised deep learning in computer vision. However, a limited number of annotated data is very common, especially in ophthalmic image analysis, since manual annotation is time-consuming and labor-intensive. Self-supervised learning (SSL) methods bring huge opportunities for better utilizing unlabeled data, as they do not need massive annotations. With an attempt to use as many as possible unlabeled ophthalmic images, it is necessary to break the dimension barrier, simultaneously making use of both 2D and 3D images. In this paper, we propose a universal self-supervised Transformer framework, named Uni4Eye, to discover the inherent image property and capture domain-specific feature embedding in ophthalmic images. Uni4Eye can serve as a global feature extractor, which builds its basis on a Masked Image Modeling task with a Vision Transformer (ViT) architecture. We employ a Unified Patch Embedding module to replace the origin patch embedding module in ViT for jointly processing both 2D and 3D input images. Besides, we design a dual-branch multitask decoder module to simultaneously perform two reconstruction tasks on the input image and its gradient map, delivering discriminative representations for better convergence. We evaluate the performance of our pre-trained Uni4Eye encoder by fine-tuning it on six downstream ophthalmic image classification tasks. The superiority of Uni4Eye is successfully established through comparisons to other state-of-the-art SSL pre-training methods.
JOINED : Prior Guided Multi-task Learning for Joint Optic Disc/Cup Segmentation and Fovea Detection
Mar 01, 2022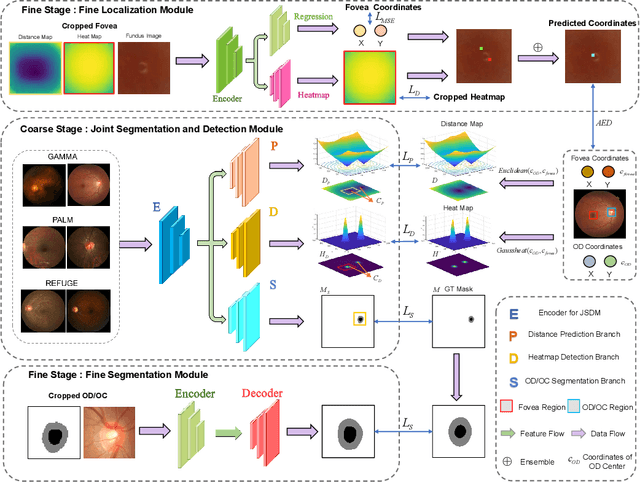
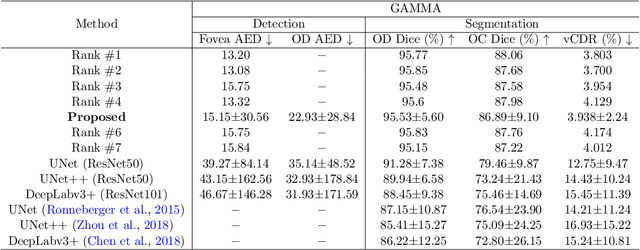

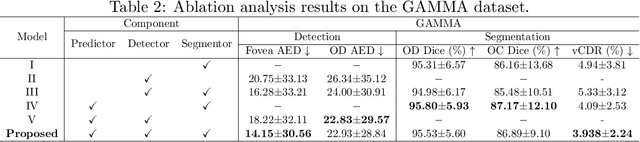
Fundus photography has been routinely used to document the presence and severity of various retinal degenerative diseases such as age-related macula degeneration, glaucoma, and diabetic retinopathy, for which the fovea, optic disc (OD), and optic cup (OC) are important anatomical landmarks. Identification of those anatomical landmarks is of great clinical importance. However, the presence of lesions, drusen, and other abnormalities during retinal degeneration severely complicates automatic landmark detection and segmentation. Most existing works treat the identification of each landmark as a single task and typically do not make use of any clinical prior information. In this paper, we present a novel method, named JOINED, for prior guided multi-task learning for joint OD/OC segmentation and fovea detection. An auxiliary branch for distance prediction, in addition to a segmentation branch and a detection branch, is constructed to effectively utilize the distance information from each image pixel to landmarks of interest. Our proposed JOINED pipeline consists of a coarse stage and a fine stage. At the coarse stage, we obtain the OD/OC coarse segmentation and the heatmap localization of fovea through a joint segmentation and detection module. Afterwards, we crop the regions of interest for subsequent fine processing and use predictions obtained at the coarse stage as additional information for better performance and faster convergence. Experimental results reveal that our proposed JOINED outperforms existing state-of-the-art approaches on the publicly-available GAMMA, PALM, and REFUGE datasets of fundus images. Furthermore, JOINED ranked the 5th on the OD/OC segmentation and fovea detection tasks in the GAMMA challenge hosted by the MICCAI2021 workshop OMIA8.
COROLLA: An Efficient Multi-Modality Fusion Framework with Supervised Contrastive Learning for Glaucoma Grading
Jan 25, 2022

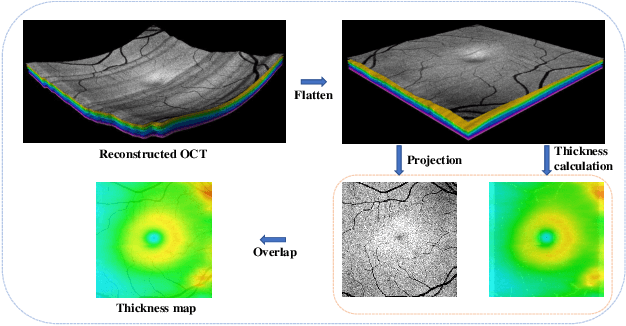

Glaucoma is one of the ophthalmic diseases that may cause blindness, for which early detection and treatment are very important. Fundus images and optical coherence tomography (OCT) images are both widely-used modalities in diagnosing glaucoma. However, existing glaucoma grading approaches mainly utilize a single modality, ignoring the complementary information between fundus and OCT. In this paper, we propose an efficient multi-modality supervised contrastive learning framework, named COROLLA, for glaucoma grading. Through layer segmentation as well as thickness calculation and projection, retinal thickness maps are extracted from the original OCT volumes and used as a replacing modality, resulting in more efficient calculations with less memory usage. Given the high structure and distribution similarities across medical image samples, we employ supervised contrastive learning to increase our models' discriminative power with better convergence. Moreover, feature-level fusion of paired fundus image and thickness map is conducted for enhanced diagnosis accuracy. On the GAMMA dataset, our COROLLA framework achieves overwhelming glaucoma grading performance compared to state-of-the-art methods.
Safe Multi-Agent Reinforcement Learning through Decentralized Multiple Control Barrier Functions
Mar 23, 2021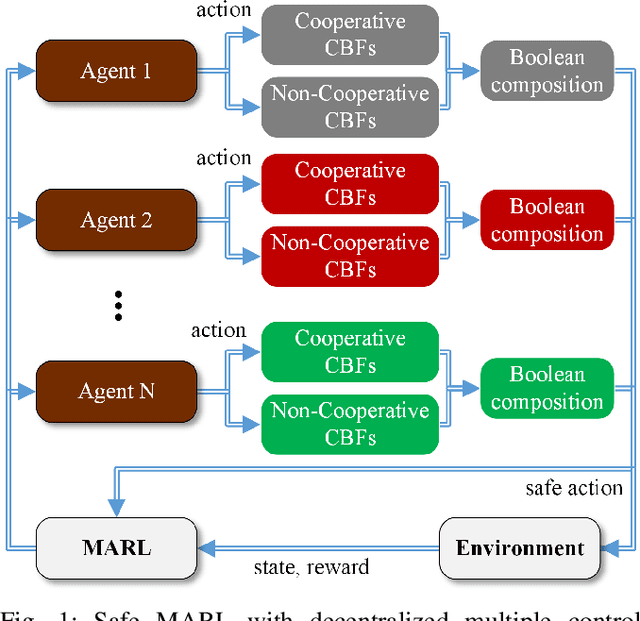
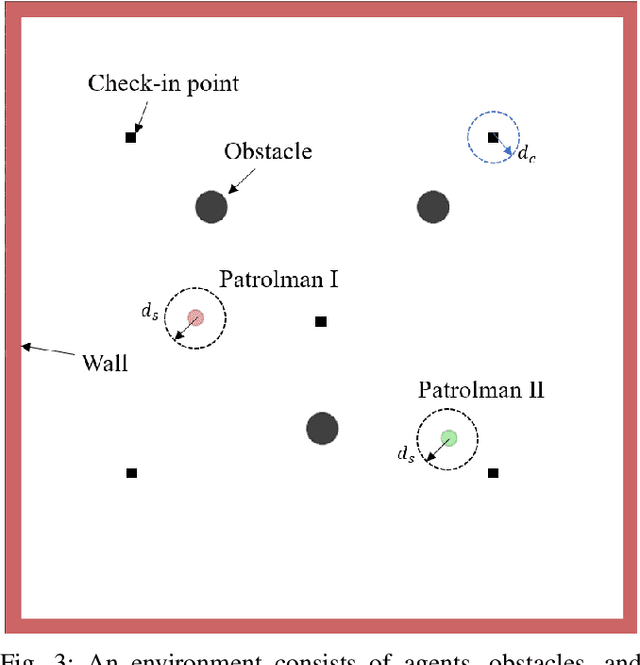
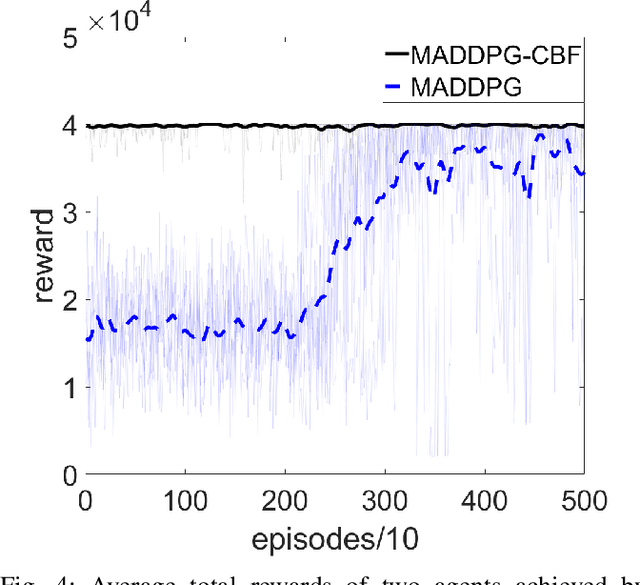
Multi-Agent Reinforcement Learning (MARL) algorithms show amazing performance in simulation in recent years, but placing MARL in real-world applications may suffer safety problems. MARL with centralized shields was proposed and verified in safety games recently. However, centralized shielding approaches can be infeasible in several real-world multi-agent applications that involve non-cooperative agents or communication delay. Thus, we propose to combine MARL with decentralized Control Barrier Function (CBF) shields based on available local information. We establish a safe MARL framework with decentralized multiple CBFs and develop Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to Multi-Agent Deep Deterministic Policy Gradient with decentralized multiple Control Barrier Functions (MADDPG-CBF). Based on a collision-avoidance problem that includes not only cooperative agents but obstacles, we demonstrate the construction of multiple CBFs with safety guarantees in theory. Experiments are conducted and experiment results verify that the proposed safe MARL framework can guarantee the safety of agents included in MARL.