 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff4MMLiTS: Advanced Multimodal Liver Tumor Segmentation via Diffusion-Based Image Synthesis and Alignment
Dec 29, 2024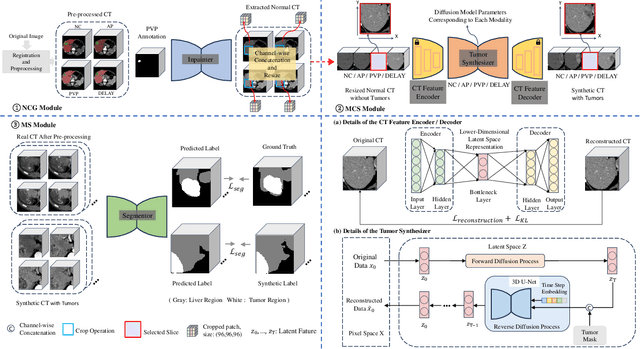
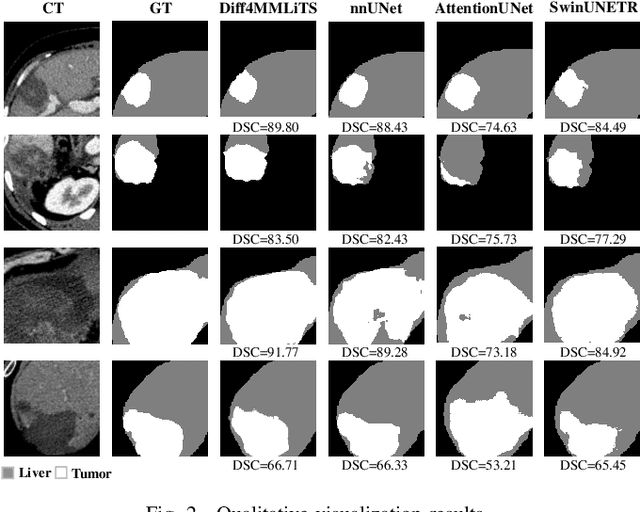
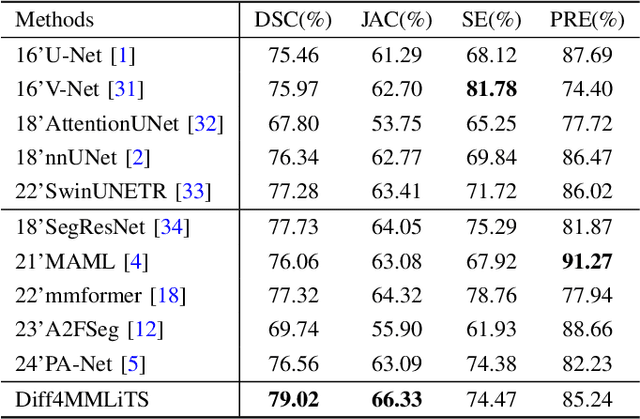
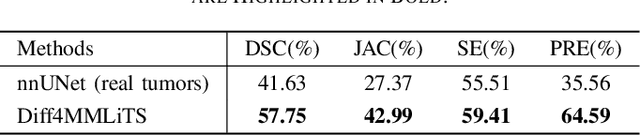
Multimodal learning has been demonstrated to enhance performance across various clinical tasks, owing to the diverse perspectives offered by different modalities of data. However, existing multimodal segmentation methods rely on well-registered multimodal data, which is unrealistic for real-world clinical images, particularly for indistinct and diffuse regions such as liver tumors. In this paper, we introduce Diff4MMLiTS, a four-stage multimodal liver tumor segmentation pipeline: pre-registration of the target organs in multimodal CTs; dilation of the annotated modality's mask and followed by its use in inpainting to obtain multimodal normal CTs without tumors; synthesis of strictly aligned multimodal CTs with tumors using the latent diffusion model based on multimodal CT features and randomly generated tumor masks; and finally, training the segmentation model, thus eliminating the need for strictly aligned multimodal data. Extensive experiments on public and internal datasets demonstrate the superiority of Diff4MMLiTS over other state-of-the-art multimodal segmentation methods.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024



Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
InsightMapper: A Closer Look at Inner-instance Information for Vectorized High-Definition Mapping
Aug 16, 2023Vectorized high-definition (HD) maps contain detailed information about surrounding road elements, which are crucial for various downstream tasks in modern autonomous driving vehicles, such as vehicle planning and control. Recent works have attempted to directly detect the vectorized HD map as a point set prediction task, resulting in significant improvements in detection performance. However, these approaches fail to analyze and exploit the inner-instance correlations between predicted points, impeding further advancements. To address these challenges, we investigate the utilization of inner-$\textbf{INS}$tance information for vectorized h$\textbf{IGH}$-definition mapping through $\textbf{T}$ransformers and introduce InsightMapper. This paper presents three novel designs within InsightMapper that leverage inner-instance information in distinct ways, including hybrid query generation, inner-instance query fusion, and inner-instance feature aggregation. Comparative experiments are conducted on the NuScenes dataset, showcasing the superiority of our proposed method. InsightMapper surpasses previous state-of-the-art (SOTA) methods by 5.78 mAP and 5.12 TOPO, which assess topology correctness. Simultaneously, InsightMapper maintains high efficiency during both training and inference phases, resulting in remarkable comprehensive performance. The project page for this work is available at https://tonyxuqaq.github.io/projects/InsightMapper .
Unifying and Personalizing Weakly-supervised Federated Medical Image Segmentation via Adaptive Representation and Aggregation
Apr 12, 2023Federated learning (FL) enables multiple sites to collaboratively train powerful deep models without compromising data privacy and security. The statistical heterogeneity (e.g., non-IID data and domain shifts) is a primary obstacle in FL, impairing the generalization performance of the global model. Weakly supervised segmentation, which uses sparsely-grained (i.e., point-, bounding box-, scribble-, block-wise) supervision, is increasingly being paid attention to due to its great potential of reducing annotation costs. However, there may exist label heterogeneity, i.e., different annotation forms across sites. In this paper, we propose a novel personalized FL framework for medical image segmentation, named FedICRA, which uniformly leverages heterogeneous weak supervision via adaptIve Contrastive Representation and Aggregation. Concretely, to facilitate personalized modeling and to avoid confusion, a channel selection based site contrastive representation module is employed to adaptively cluster intra-site embeddings and separate inter-site ones. To effectively integrate the common knowledge from the global model with the unique knowledge from each local model, an adaptive aggregation module is applied for updating and initializing local models at the element level. Additionally, a weakly supervised objective function that leverages a multiscale tree energy loss and a gated CRF loss is employed to generate more precise pseudo-labels and further boost the segmentation performance. Through extensive experiments on two distinct medical image segmentation tasks of different modalities, the proposed FedICRA demonstrates overwhelming performance over other state-of-the-art personalized FL methods. Its performance even approaches that of fully supervised training on centralized data. Our code and data are available at https://github.com/llmir/FedICRA.
GlocalFuse-Depth: Fusing Transformers and CNNs for All-day Self-supervised Monocular Depth Estimation
Feb 20, 2023

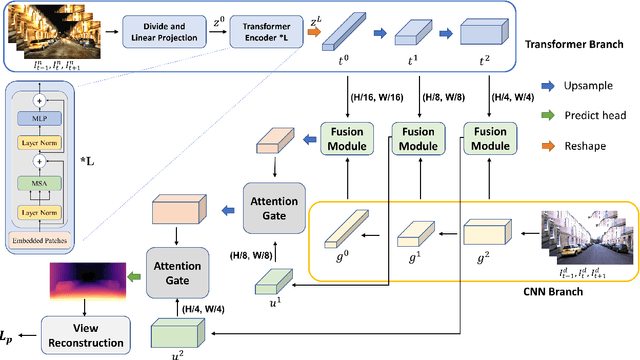

In recent years, self-supervised monocular depth estimation has drawn much attention since it frees of depth annotations and achieved remarkable results on standard benchmarks. However, most of existing methods only focus on either daytime or nighttime images, thus their performance degrades on the other domain because of the large domain shift between daytime and nighttime images. To address this problem, in this paper we propose a two-branch network named GlocalFuse-Depth for self-supervised depth estimation of all-day images. The daytime and nighttime image in input image pair are fed into the two branches: CNN branch and Transformer branch, respectively, where both fine-grained details and global dependency can be efficiently captured. Besides, a novel fusion module is proposed to fuse multi-dimensional features from the two branches. Extensive experiments demonstrate that GlocalFuse-Depth achieves state-of-the-art results for all-day images on the Oxford RobotCar dataset, which proves the superiority of our method.
YoloCurvSeg: You Only Label One Noisy Skeleton for Vessel-style Curvilinear Structure Segmentation
Dec 11, 2022



Weakly-supervised learning (WSL) has been proposed to alleviate the conflict between data annotation cost and model performance through employing sparsely-grained (i.e., point-, box-, scribble-wise) supervision and has shown promising performance, particularly in the image segmentation field. However, it is still a very challenging problem due to the limited supervision, especially when only a small number of labeled samples are available. Additionally, almost all existing WSL segmentation methods are designed for star-convex structures which are very different from curvilinear structures such as vessels and nerves. In this paper, we propose a novel sparsely annotated segmentation framework for curvilinear structures, named YoloCurvSeg, based on image synthesis. A background generator delivers image backgrounds that closely match real distributions through inpainting dilated skeletons. The extracted backgrounds are then combined with randomly emulated curves generated by a Space Colonization Algorithm-based foreground generator and through a multilayer patch-wise contrastive learning synthesizer. In this way, a synthetic dataset with both images and curve segmentation labels is obtained, at the cost of only one or a few noisy skeleton annotations. Finally, a segmenter is trained with the generated dataset and possibly an unlabeled dataset. The proposed YoloCurvSeg is evaluated on four publicly available datasets (OCTA500, CORN, DRIVE and CHASEDB1) and the results show that YoloCurvSeg outperforms state-of-the-art WSL segmentation methods by large margins. With only one noisy skeleton annotation (respectively 0.14%, 0.02%, 1.4%, and 0.65% of the full annotation), YoloCurvSeg achieves more than 97% of the fully-supervised performance on each dataset. Code and datasets will be released at https://github.com/llmir/YoloCurvSeg.