 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRing-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024



Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
Unifying and Personalizing Weakly-supervised Federated Medical Image Segmentation via Adaptive Representation and Aggregation
Apr 12, 2023Federated learning (FL) enables multiple sites to collaboratively train powerful deep models without compromising data privacy and security. The statistical heterogeneity (e.g., non-IID data and domain shifts) is a primary obstacle in FL, impairing the generalization performance of the global model. Weakly supervised segmentation, which uses sparsely-grained (i.e., point-, bounding box-, scribble-, block-wise) supervision, is increasingly being paid attention to due to its great potential of reducing annotation costs. However, there may exist label heterogeneity, i.e., different annotation forms across sites. In this paper, we propose a novel personalized FL framework for medical image segmentation, named FedICRA, which uniformly leverages heterogeneous weak supervision via adaptIve Contrastive Representation and Aggregation. Concretely, to facilitate personalized modeling and to avoid confusion, a channel selection based site contrastive representation module is employed to adaptively cluster intra-site embeddings and separate inter-site ones. To effectively integrate the common knowledge from the global model with the unique knowledge from each local model, an adaptive aggregation module is applied for updating and initializing local models at the element level. Additionally, a weakly supervised objective function that leverages a multiscale tree energy loss and a gated CRF loss is employed to generate more precise pseudo-labels and further boost the segmentation performance. Through extensive experiments on two distinct medical image segmentation tasks of different modalities, the proposed FedICRA demonstrates overwhelming performance over other state-of-the-art personalized FL methods. Its performance even approaches that of fully supervised training on centralized data. Our code and data are available at https://github.com/llmir/FedICRA.
YoloCurvSeg: You Only Label One Noisy Skeleton for Vessel-style Curvilinear Structure Segmentation
Dec 11, 2022



Weakly-supervised learning (WSL) has been proposed to alleviate the conflict between data annotation cost and model performance through employing sparsely-grained (i.e., point-, box-, scribble-wise) supervision and has shown promising performance, particularly in the image segmentation field. However, it is still a very challenging problem due to the limited supervision, especially when only a small number of labeled samples are available. Additionally, almost all existing WSL segmentation methods are designed for star-convex structures which are very different from curvilinear structures such as vessels and nerves. In this paper, we propose a novel sparsely annotated segmentation framework for curvilinear structures, named YoloCurvSeg, based on image synthesis. A background generator delivers image backgrounds that closely match real distributions through inpainting dilated skeletons. The extracted backgrounds are then combined with randomly emulated curves generated by a Space Colonization Algorithm-based foreground generator and through a multilayer patch-wise contrastive learning synthesizer. In this way, a synthetic dataset with both images and curve segmentation labels is obtained, at the cost of only one or a few noisy skeleton annotations. Finally, a segmenter is trained with the generated dataset and possibly an unlabeled dataset. The proposed YoloCurvSeg is evaluated on four publicly available datasets (OCTA500, CORN, DRIVE and CHASEDB1) and the results show that YoloCurvSeg outperforms state-of-the-art WSL segmentation methods by large margins. With only one noisy skeleton annotation (respectively 0.14%, 0.02%, 1.4%, and 0.65% of the full annotation), YoloCurvSeg achieves more than 97% of the fully-supervised performance on each dataset. Code and datasets will be released at https://github.com/llmir/YoloCurvSeg.
BSDA-Net: A Boundary Shape and Distance Aware Joint Learning Framework for Segmenting and Classifying OCTA Images
Jul 13, 2021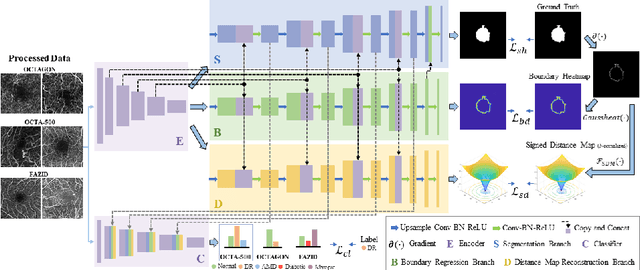

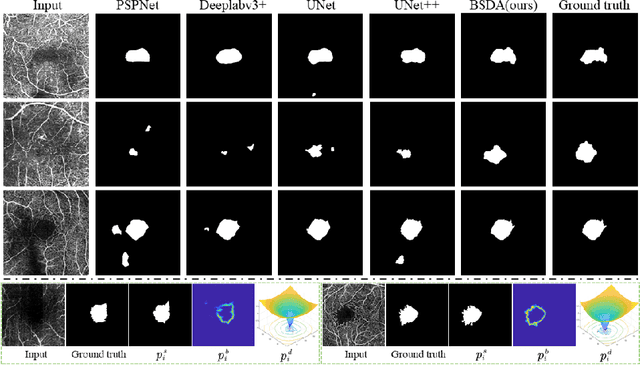
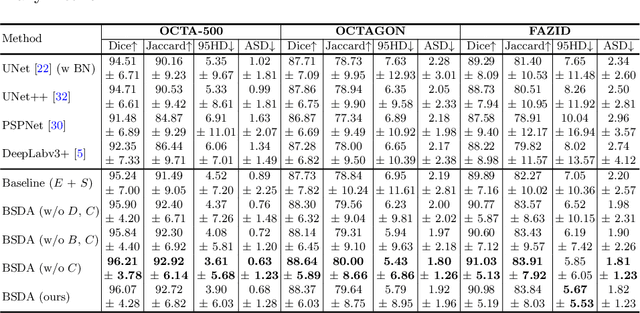
Optical coherence tomography angiography (OCTA) is a novel non-invasive imaging technique that allows visualizations of vasculature and foveal avascular zone (FAZ) across retinal layers. Clinical researches suggest that the morphology and contour irregularity of FAZ are important biomarkers of various ocular pathologies. Therefore, precise segmentation of FAZ has great clinical interest. Also, there is no existing research reporting that FAZ features can improve the performance of deep diagnostic classification networks. In this paper, we propose a novel multi-level boundary shape and distance aware joint learning framework, named BSDA-Net, for FAZ segmentation and diagnostic classification from OCTA images. Two auxiliary branches, namely boundary heatmap regression and signed distance map reconstruction branches, are constructed in addition to the segmentation branch to improve the segmentation performance, resulting in more accurate FAZ contours and fewer outliers. Moreover, both low-level and high-level features from the aforementioned three branches, including shape, size, boundary, and signed directional distance map of FAZ, are fused hierarchically with features from the diagnostic classifier. Through extensive experiments, the proposed BSDA-Net is found to yield state-of-the-art segmentation and classification results on the OCTA-500, OCTAGON, and FAZID datasets.