 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOINEDTrans: Prior Guided Multi-task Transformer for Joint Optic Disc/Cup Segmentation and Fovea Detection
May 19, 2023



Deep learning-based image segmentation and detection models have largely improved the efficiency of analyzing retinal landmarks such as optic disc (OD), optic cup (OC), and fovea. However, factors including ophthalmic disease-related lesions and low image quality issues may severely complicate automatic OD/OC segmentation and fovea detection. Most existing works treat the identification of each landmark as a single task, and take into account no prior information. To address these issues, we propose a prior guided multi-task transformer framework for joint OD/OC segmentation and fovea detection, named JOINEDTrans. JOINEDTrans effectively combines various spatial features of the fundus images, relieving the structural distortions induced by lesions and other imaging issues. It contains a segmentation branch and a detection branch. To be noted, we employ an encoder pretrained in a vessel segmentation task to effectively exploit the positional relationship among vessel, OD/OC, and fovea, successfully incorporating spatial prior into the proposed JOINEDTrans framework. There are a coarse stage and a fine stage in JOINEDTrans. In the coarse stage, OD/OC coarse segmentation and fovea heatmap localization are obtained through a joint segmentation and detection module. In the fine stage, we crop regions of interest for subsequent refinement and use predictions obtained in the coarse stage to provide additional information for better performance and faster convergence. Experimental results demonstrate that JOINEDTrans outperforms existing state-of-the-art methods on the publicly available GAMMA, REFUGE, and PALM fundus image datasets. We make our code available at https://github.com/HuaqingHe/JOINEDTrans
Learning Enhancement From Degradation: A Diffusion Model For Fundus Image Enhancement
Mar 08, 2023The quality of a fundus image can be compromised by numerous factors, many of which are challenging to be appropriately and mathematically modeled. In this paper, we introduce a novel diffusion model based framework, named Learning Enhancement from Degradation (LED), for enhancing fundus images. Specifically, we first adopt a data-driven degradation framework to learn degradation mappings from unpaired high-quality to low-quality images. We then apply a conditional diffusion model to learn the inverse enhancement process in a paired manner. The proposed LED is able to output enhancement results that maintain clinically important features with better clarity. Moreover, in the inference phase, LED can be easily and effectively integrated with any existing fundus image enhancement framework. We evaluate the proposed LED on several downstream tasks with respect to various clinically-relevant metrics, successfully demonstrating its superiority over existing state-of-the-art methods both quantitatively and qualitatively. The source code is available at https://github.com/QtacierP/LED.
YoloCurvSeg: You Only Label One Noisy Skeleton for Vessel-style Curvilinear Structure Segmentation
Dec 11, 2022Weakly-supervised learning (WSL) has been proposed to alleviate the conflict between data annotation cost and model performance through employing sparsely-grained (i.e., point-, box-, scribble-wise) supervision and has shown promising performance, particularly in the image segmentation field. However, it is still a very challenging problem due to the limited supervision, especially when only a small number of labeled samples are available. Additionally, almost all existing WSL segmentation methods are designed for star-convex structures which are very different from curvilinear structures such as vessels and nerves. In this paper, we propose a novel sparsely annotated segmentation framework for curvilinear structures, named YoloCurvSeg, based on image synthesis. A background generator delivers image backgrounds that closely match real distributions through inpainting dilated skeletons. The extracted backgrounds are then combined with randomly emulated curves generated by a Space Colonization Algorithm-based foreground generator and through a multilayer patch-wise contrastive learning synthesizer. In this way, a synthetic dataset with both images and curve segmentation labels is obtained, at the cost of only one or a few noisy skeleton annotations. Finally, a segmenter is trained with the generated dataset and possibly an unlabeled dataset. The proposed YoloCurvSeg is evaluated on four publicly available datasets (OCTA500, CORN, DRIVE and CHASEDB1) and the results show that YoloCurvSeg outperforms state-of-the-art WSL segmentation methods by large margins. With only one noisy skeleton annotation (respectively 0.14%, 0.02%, 1.4%, and 0.65% of the full annotation), YoloCurvSeg achieves more than 97% of the fully-supervised performance on each dataset. Code and datasets will be released at https://github.com/llmir/YoloCurvSeg.
Uni4Eye: Unified 2D and 3D Self-supervised Pre-training via Masked Image Modeling Transformer for Ophthalmic Image Classification
Mar 12, 2022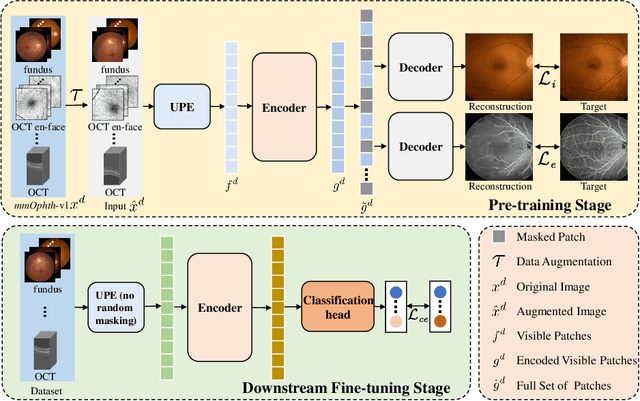

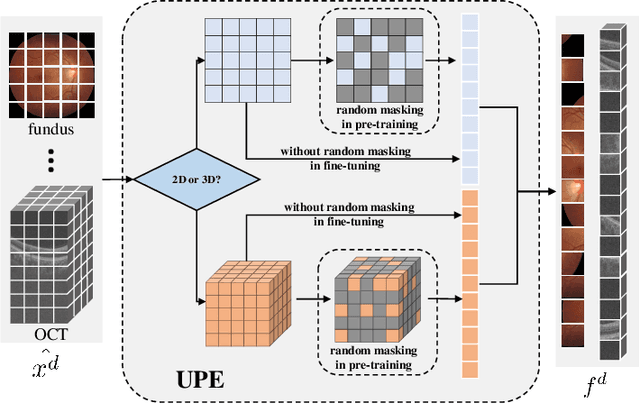
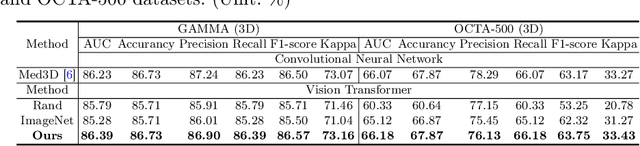
A large-scale labeled dataset is a key factor for the success of supervised deep learning in computer vision. However, a limited number of annotated data is very common, especially in ophthalmic image analysis, since manual annotation is time-consuming and labor-intensive. Self-supervised learning (SSL) methods bring huge opportunities for better utilizing unlabeled data, as they do not need massive annotations. With an attempt to use as many as possible unlabeled ophthalmic images, it is necessary to break the dimension barrier, simultaneously making use of both 2D and 3D images. In this paper, we propose a universal self-supervised Transformer framework, named Uni4Eye, to discover the inherent image property and capture domain-specific feature embedding in ophthalmic images. Uni4Eye can serve as a global feature extractor, which builds its basis on a Masked Image Modeling task with a Vision Transformer (ViT) architecture. We employ a Unified Patch Embedding module to replace the origin patch embedding module in ViT for jointly processing both 2D and 3D input images. Besides, we design a dual-branch multitask decoder module to simultaneously perform two reconstruction tasks on the input image and its gradient map, delivering discriminative representations for better convergence. We evaluate the performance of our pre-trained Uni4Eye encoder by fine-tuning it on six downstream ophthalmic image classification tasks. The superiority of Uni4Eye is successfully established through comparisons to other state-of-the-art SSL pre-training methods.
Student Become Decathlon Master in Retinal Vessel Segmentation via Dual-teacher Multi-target Domain Adaptation
Mar 09, 2022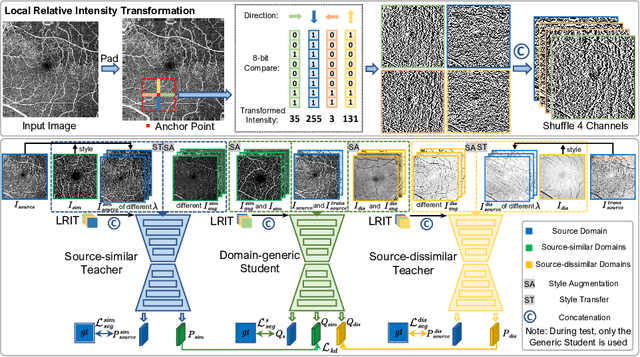
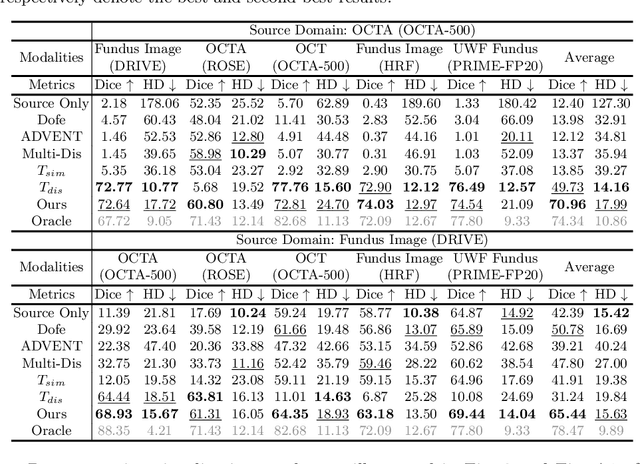
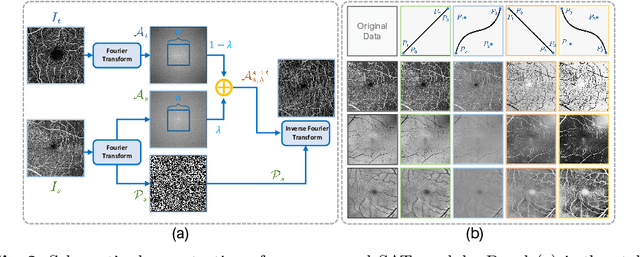
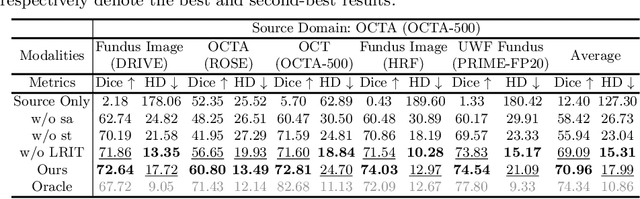
Unsupervised domain adaptation has been proposed recently to tackle the so-called domain shift between training data and test data with different distributions. However, most of them only focus on single-target domain adaptation and cannot be applied to the scenario with multiple target domains. In this paper, we propose RVms, a novel unsupervised multi-target domain adaptation approach to segment retinal vessels (RVs) from multimodal and multicenter retinal images. RVms mainly consists of a style augmentation and transfer (SAT) module and a dual-teacher knowledge distillation (DTKD) module. SAT augments and clusters images into source-similar domains and source-dissimilar domains via B\'ezier and Fourier transformations. DTKD utilizes the augmented and transformed data to train two teachers, one for source-similar domains and the other for source-dissimilar domains. Afterwards, knowledge distillation is performed to iteratively distill different domain knowledge from teachers to a generic student. The local relative intensity transformation is employed to characterize RVs in a domain invariant manner and promote the generalizability of teachers and student models. Moreover, we construct a new multimodal and multicenter vascular segmentation dataset from existing publicly-available datasets, which can be used to benchmark various domain adaptation and domain generalization methods. Through extensive experiments, RVms is found to be very close to the target-trained Oracle in terms of segmenting the RVs, largely outperforming other state-of-the-art methods.
JOINED : Prior Guided Multi-task Learning for Joint Optic Disc/Cup Segmentation and Fovea Detection
Mar 01, 2022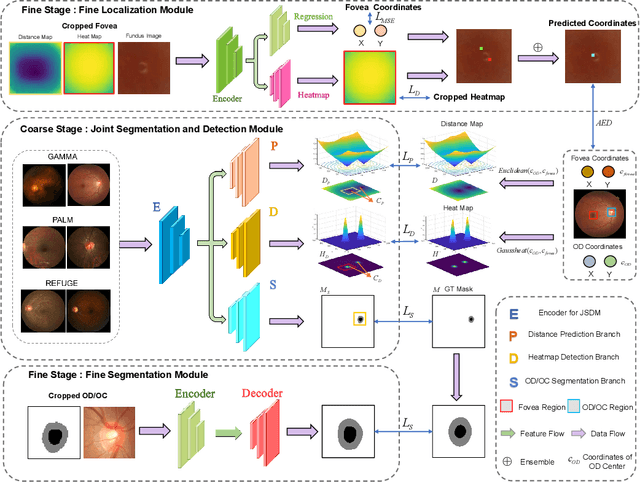
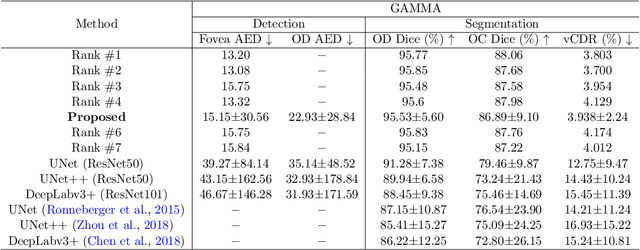

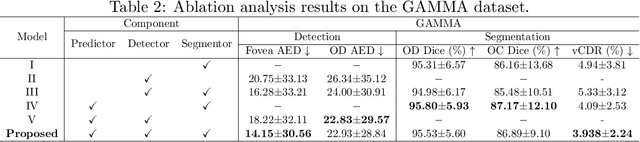
Fundus photography has been routinely used to document the presence and severity of various retinal degenerative diseases such as age-related macula degeneration, glaucoma, and diabetic retinopathy, for which the fovea, optic disc (OD), and optic cup (OC) are important anatomical landmarks. Identification of those anatomical landmarks is of great clinical importance. However, the presence of lesions, drusen, and other abnormalities during retinal degeneration severely complicates automatic landmark detection and segmentation. Most existing works treat the identification of each landmark as a single task and typically do not make use of any clinical prior information. In this paper, we present a novel method, named JOINED, for prior guided multi-task learning for joint OD/OC segmentation and fovea detection. An auxiliary branch for distance prediction, in addition to a segmentation branch and a detection branch, is constructed to effectively utilize the distance information from each image pixel to landmarks of interest. Our proposed JOINED pipeline consists of a coarse stage and a fine stage. At the coarse stage, we obtain the OD/OC coarse segmentation and the heatmap localization of fovea through a joint segmentation and detection module. Afterwards, we crop the regions of interest for subsequent fine processing and use predictions obtained at the coarse stage as additional information for better performance and faster convergence. Experimental results reveal that our proposed JOINED outperforms existing state-of-the-art approaches on the publicly-available GAMMA, PALM, and REFUGE datasets of fundus images. Furthermore, JOINED ranked the 5th on the OD/OC segmentation and fovea detection tasks in the GAMMA challenge hosted by the MICCAI2021 workshop OMIA8.
COROLLA: An Efficient Multi-Modality Fusion Framework with Supervised Contrastive Learning for Glaucoma Grading
Jan 25, 2022

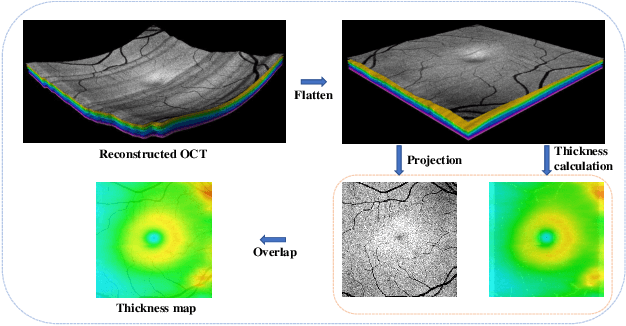

Glaucoma is one of the ophthalmic diseases that may cause blindness, for which early detection and treatment are very important. Fundus images and optical coherence tomography (OCT) images are both widely-used modalities in diagnosing glaucoma. However, existing glaucoma grading approaches mainly utilize a single modality, ignoring the complementary information between fundus and OCT. In this paper, we propose an efficient multi-modality supervised contrastive learning framework, named COROLLA, for glaucoma grading. Through layer segmentation as well as thickness calculation and projection, retinal thickness maps are extracted from the original OCT volumes and used as a replacing modality, resulting in more efficient calculations with less memory usage. Given the high structure and distribution similarities across medical image samples, we employ supervised contrastive learning to increase our models' discriminative power with better convergence. Moreover, feature-level fusion of paired fundus image and thickness map is conducted for enhanced diagnosis accuracy. On the GAMMA dataset, our COROLLA framework achieves overwhelming glaucoma grading performance compared to state-of-the-art methods.