 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGS: 3D Tumor-Adaptive Guidance for SAM
May 21, 2025Foundation models (FMs) such as CLIP and SAM have recently shown great promise in image segmentation tasks, yet their adaptation to 3D medical imaging-particularly for pathology detection and segmentation-remains underexplored. A critical challenge arises from the domain gap between natural images and medical volumes: existing FMs, pre-trained on 2D data, struggle to capture 3D anatomical context, limiting their utility in clinical applications like tumor segmentation. To address this, we propose an adaptation framework called TAGS: Tumor Adaptive Guidance for SAM, which unlocks 2D FMs for 3D medical tasks through multi-prompt fusion. By preserving most of the pre-trained weights, our approach enhances SAM's spatial feature extraction using CLIP's semantic insights and anatomy-specific prompts. Extensive experiments on three open-source tumor segmentation datasets prove that our model surpasses the state-of-the-art medical image segmentation models (+46.88% over nnUNet), interactive segmentation frameworks, and other established medical FMs, including SAM-Med2D, SAM-Med3D, SegVol, Universal, 3D-Adapter, and SAM-B (at least +13% over them). This highlights the robustness and adaptability of our proposed framework across diverse medical segmentation tasks.
VideoAds for Fast-Paced Video Understanding: Where Opensource Foundation Models Beat GPT-4o & Gemini-1.5 Pro
Apr 12, 2025Advertisement videos serve as a rich and valuable source of purpose-driven information, encompassing high-quality visual, textual, and contextual cues designed to engage viewers. They are often more complex than general videos of similar duration due to their structured narratives and rapid scene transitions, posing significant challenges to multi-modal large language models (MLLMs). In this work, we introduce VideoAds, the first dataset tailored for benchmarking the performance of MLLMs on advertisement videos. VideoAds comprises well-curated advertisement videos with complex temporal structures, accompanied by \textbf{manually} annotated diverse questions across three core tasks: visual finding, video summary, and visual reasoning. We propose a quantitative measure to compare VideoAds against existing benchmarks in terms of video complexity. Through extensive experiments, we find that Qwen2.5-VL-72B, an opensource MLLM, achieves 73.35\% accuracy on VideoAds, outperforming GPT-4o (66.82\%) and Gemini-1.5 Pro (69.66\%); the two proprietary models especially fall behind the opensource model in video summarization and reasoning, but perform the best in visual finding. Notably, human experts easily achieve a remarkable accuracy of 94.27\%. These results underscore the necessity of advancing MLLMs' temporal modeling capabilities and highlight VideoAds as a potentially pivotal benchmark for future research in understanding video that requires high FPS sampling. The dataset and evaluation code will be publicly available at https://videoadsbenchmark.netlify.app.
Optimizing Synthetic Data for Enhanced Pancreatic Tumor Segmentation
Jul 27, 2024



Pancreatic cancer remains one of the leading causes of cancer-related mortality worldwide. Precise segmentation of pancreatic tumors from medical images is a bottleneck for effective clinical decision-making. However, achieving a high accuracy is often limited by the small size and availability of real patient data for training deep learning models. Recent approaches have employed synthetic data generation to augment training datasets. While promising, these methods may not yet meet the performance benchmarks required for real-world clinical use. This study critically evaluates the limitations of existing generative-AI based frameworks for pancreatic tumor segmentation. We conduct a series of experiments to investigate the impact of synthetic \textit{tumor size} and \textit{boundary definition} precision on model performance. Our findings demonstrate that: (1) strategically selecting a combination of synthetic tumor sizes is crucial for optimal segmentation outcomes, and (2) generating synthetic tumors with precise boundaries significantly improves model accuracy. These insights highlight the importance of utilizing refined synthetic data augmentation for enhancing the clinical utility of segmentation models in pancreatic cancer decision making including diagnosis, prognosis, and treatment plans. Our code will be available at https://github.com/lkpengcs/SynTumorAnalyzer.
Pronunciation Assessment with Multi-modal Large Language Models
Jul 12, 2024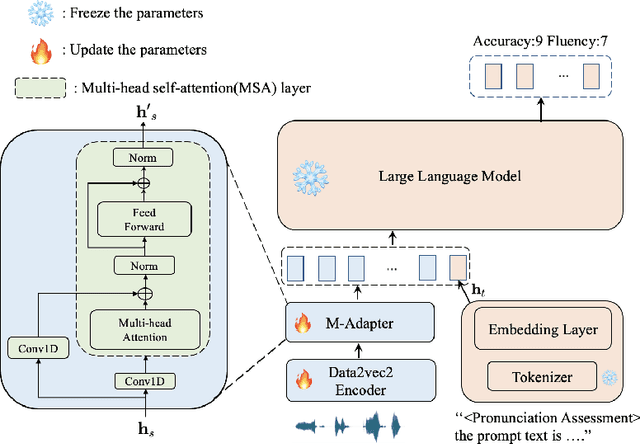

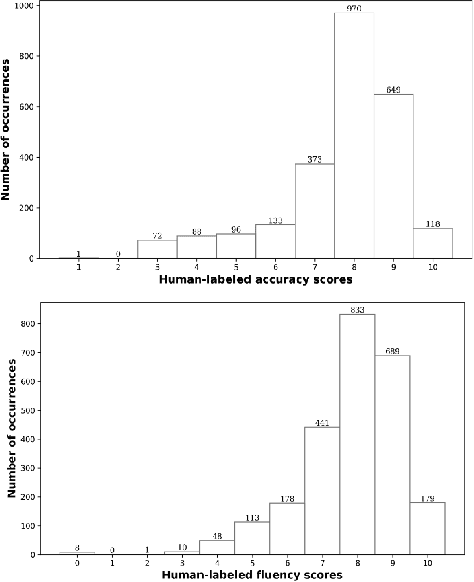
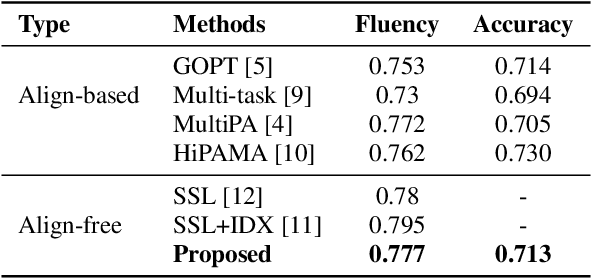
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.
Large-Scale Multi-Center CT and MRI Segmentation of Pancreas with Deep Learning
May 20, 2024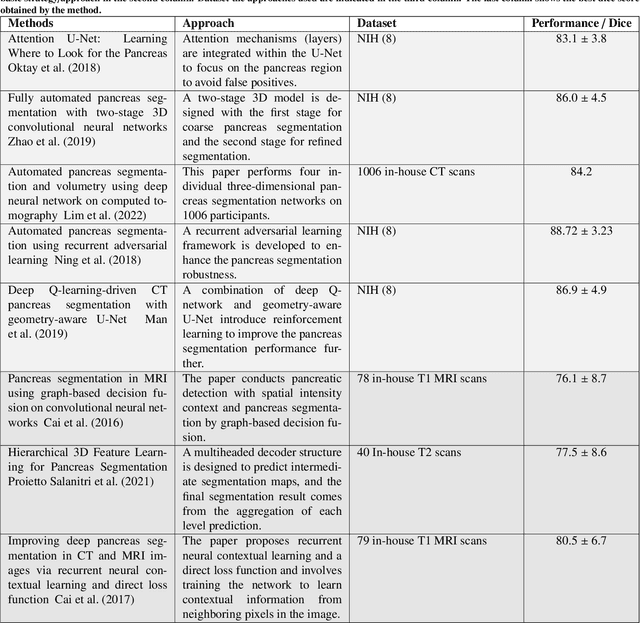
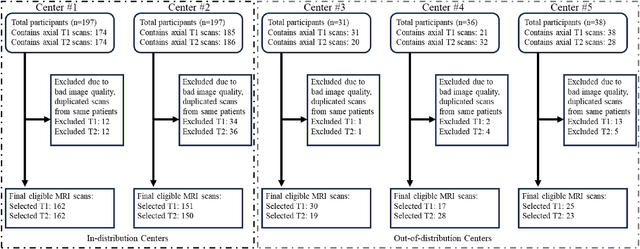
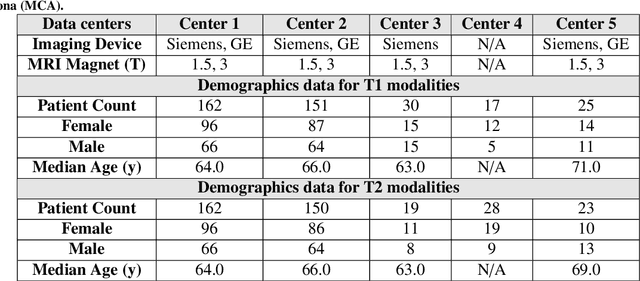
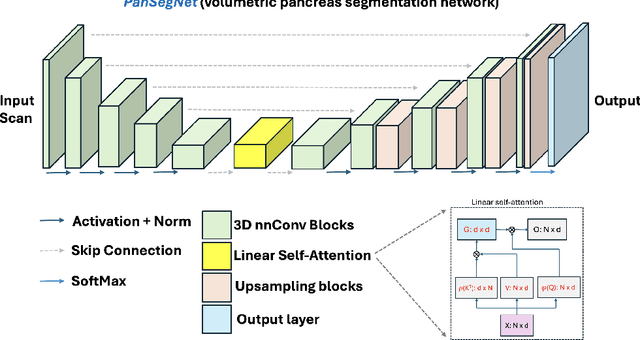
Automated volumetric segmentation of the pancreas on cross-sectional imaging is needed for diagnosis and follow-up of pancreatic diseases. While CT-based pancreatic segmentation is more established, MRI-based segmentation methods are understudied, largely due to a lack of publicly available datasets, benchmarking research efforts, and domain-specific deep learning methods. In this retrospective study, we collected a large dataset (767 scans from 499 participants) of T1-weighted (T1W) and T2-weighted (T2W) abdominal MRI series from five centers between March 2004 and November 2022. We also collected CT scans of 1,350 patients from publicly available sources for benchmarking purposes. We developed a new pancreas segmentation method, called PanSegNet, combining the strengths of nnUNet and a Transformer network with a new linear attention module enabling volumetric computation. We tested PanSegNet's accuracy in cross-modality (a total of 2,117 scans) and cross-center settings with Dice and Hausdorff distance (HD95) evaluation metrics. We used Cohen's kappa statistics for intra and inter-rater agreement evaluation and paired t-tests for volume and Dice comparisons, respectively. For segmentation accuracy, we achieved Dice coefficients of 88.3% (std: 7.2%, at case level) with CT, 85.0% (std: 7.9%) with T1W MRI, and 86.3% (std: 6.4%) with T2W MRI. There was a high correlation for pancreas volume prediction with R^2 of 0.91, 0.84, and 0.85 for CT, T1W, and T2W, respectively. We found moderate inter-observer (0.624 and 0.638 for T1W and T2W MRI, respectively) and high intra-observer agreement scores. All MRI data is made available at https://osf.io/kysnj/. Our source code is available at https://github.com/NUBagciLab/PaNSegNet.
Spoken Language Intelligence of Large Language Models for Language Learning
Aug 28, 2023



People have long hoped for a conversational system that can assist in real-life situations, and recent progress on large language models (LLMs) is bringing this idea closer to reality. While LLMs are often impressive in performance, their efficacy in real-world scenarios that demand expert knowledge remains unclear. LLMs are believed to hold the most potential and value in education, especially in the development of Artificial intelligence (AI) based virtual teachers capable of facilitating language learning. Our focus is centered on evaluating the efficacy of LLMs in the realm of education, specifically in the areas of spoken language learning which encompass phonetics, phonology, and second language acquisition. We introduce a new multiple-choice question dataset to evaluate the effectiveness of LLMs in the aforementioned scenarios, including understanding and application of spoken language knowledge. In addition, we investigate the influence of various prompting techniques such as zero- and few-shot method (prepending the question with question-answer exemplars), chain-of-thought (CoT, think step-by-step), in-domain exampler and external tools (Google, Wikipedia). We conducted large-scale evaluation on popular LLMs (20 distinct models) using these methods. We achieved significant performance improvements compared to the zero-shot baseline in the practical questions reasoning (GPT-3.5, 49.1% -> 63.1%; LLaMA2-70B-Chat, 42.2% -> 48.6%). We found that models of different sizes have good understanding of concepts in phonetics, phonology, and second language acquisition, but show limitations in reasoning for real-world problems. Additionally, we also explore preliminary findings on conversational communication.
YoloCurvSeg: You Only Label One Noisy Skeleton for Vessel-style Curvilinear Structure Segmentation
Dec 11, 2022



Weakly-supervised learning (WSL) has been proposed to alleviate the conflict between data annotation cost and model performance through employing sparsely-grained (i.e., point-, box-, scribble-wise) supervision and has shown promising performance, particularly in the image segmentation field. However, it is still a very challenging problem due to the limited supervision, especially when only a small number of labeled samples are available. Additionally, almost all existing WSL segmentation methods are designed for star-convex structures which are very different from curvilinear structures such as vessels and nerves. In this paper, we propose a novel sparsely annotated segmentation framework for curvilinear structures, named YoloCurvSeg, based on image synthesis. A background generator delivers image backgrounds that closely match real distributions through inpainting dilated skeletons. The extracted backgrounds are then combined with randomly emulated curves generated by a Space Colonization Algorithm-based foreground generator and through a multilayer patch-wise contrastive learning synthesizer. In this way, a synthetic dataset with both images and curve segmentation labels is obtained, at the cost of only one or a few noisy skeleton annotations. Finally, a segmenter is trained with the generated dataset and possibly an unlabeled dataset. The proposed YoloCurvSeg is evaluated on four publicly available datasets (OCTA500, CORN, DRIVE and CHASEDB1) and the results show that YoloCurvSeg outperforms state-of-the-art WSL segmentation methods by large margins. With only one noisy skeleton annotation (respectively 0.14%, 0.02%, 1.4%, and 0.65% of the full annotation), YoloCurvSeg achieves more than 97% of the fully-supervised performance on each dataset. Code and datasets will be released at https://github.com/llmir/YoloCurvSeg.
Text-Aware End-to-end Mispronunciation Detection and Diagnosis
Jun 15, 2022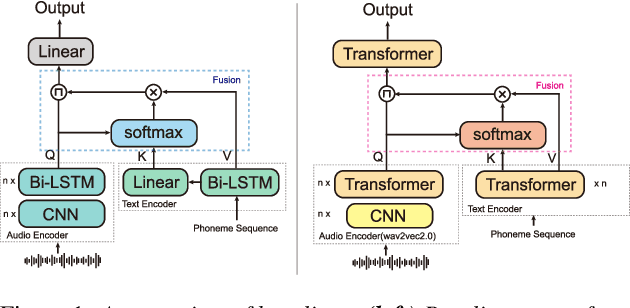
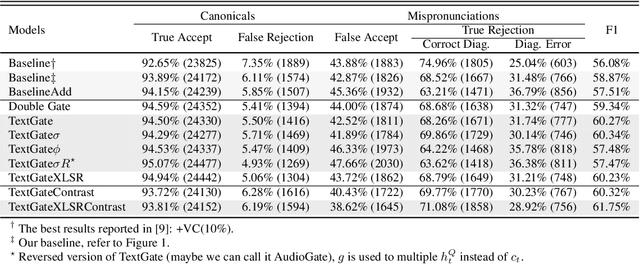
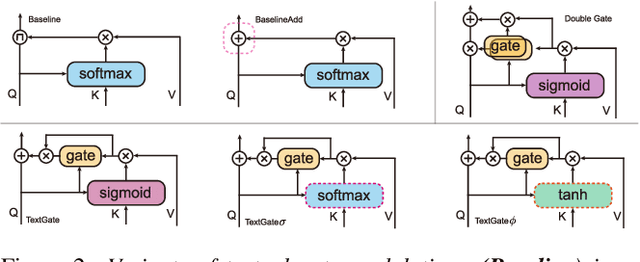
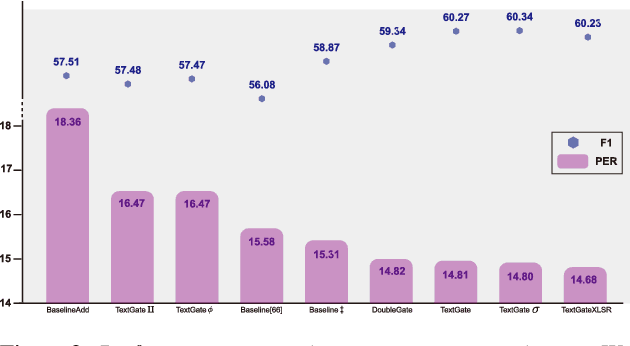
Mispronunciation detection and diagnosis (MDD) technology is a key component of computer-assisted pronunciation training system (CAPT). In the field of assessing the pronunciation quality of constrained speech, the given transcriptions can play the role of a teacher. Conventional methods have fully utilized the prior texts for the model construction or improving the system performance, e.g. forced-alignment and extended recognition networks. Recently, some end-to-end based methods attempt to incorporate the prior texts into model training and preliminarily show the effectiveness. However, previous studies mostly consider applying raw attention mechanism to fuse audio representations with text representations, without taking possible text-pronunciation mismatch into account. In this paper, we present a gating strategy that assigns more importance to the relevant audio features while suppressing irrelevant text information. Moreover, given the transcriptions, we design an extra contrastive loss to reduce the gap between the learning objective of phoneme recognition and MDD. We conducted experiments using two publicly available datasets (TIMIT and L2-Arctic) and our best model improved the F1 score from $57.51\%$ to $61.75\%$ compared to the baselines. Besides, we provide a detailed analysis to shed light on the effectiveness of gating mechanism and contrastive learning on MDD.
Student Become Decathlon Master in Retinal Vessel Segmentation via Dual-teacher Multi-target Domain Adaptation
Mar 09, 2022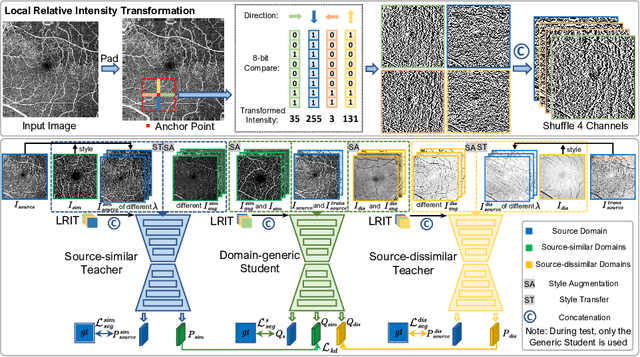
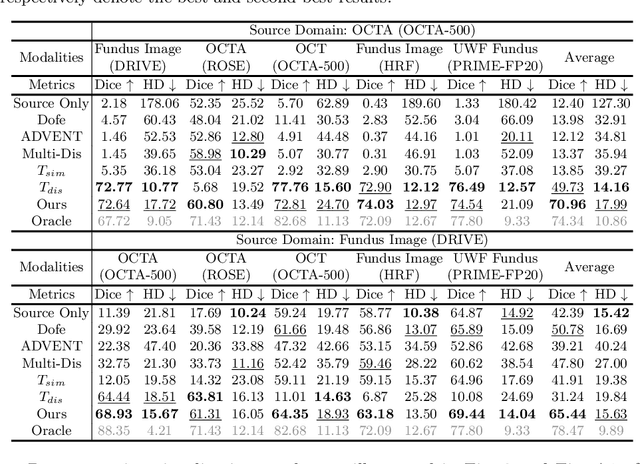
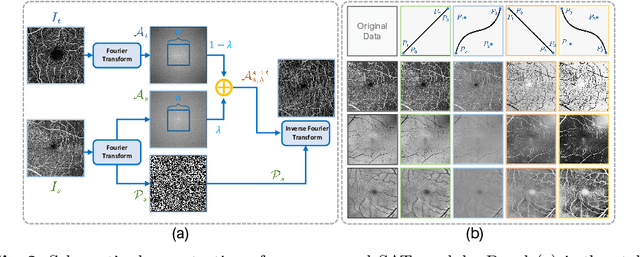
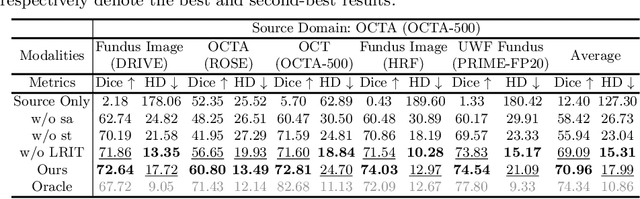
Unsupervised domain adaptation has been proposed recently to tackle the so-called domain shift between training data and test data with different distributions. However, most of them only focus on single-target domain adaptation and cannot be applied to the scenario with multiple target domains. In this paper, we propose RVms, a novel unsupervised multi-target domain adaptation approach to segment retinal vessels (RVs) from multimodal and multicenter retinal images. RVms mainly consists of a style augmentation and transfer (SAT) module and a dual-teacher knowledge distillation (DTKD) module. SAT augments and clusters images into source-similar domains and source-dissimilar domains via B\'ezier and Fourier transformations. DTKD utilizes the augmented and transformed data to train two teachers, one for source-similar domains and the other for source-dissimilar domains. Afterwards, knowledge distillation is performed to iteratively distill different domain knowledge from teachers to a generic student. The local relative intensity transformation is employed to characterize RVs in a domain invariant manner and promote the generalizability of teachers and student models. Moreover, we construct a new multimodal and multicenter vascular segmentation dataset from existing publicly-available datasets, which can be used to benchmark various domain adaptation and domain generalization methods. Through extensive experiments, RVms is found to be very close to the target-trained Oracle in terms of segmenting the RVs, largely outperforming other state-of-the-art methods.
Multi-modal Brain Tumor Segmentation via Missing Modality Synthesis and Modality-level Attention Fusion
Mar 09, 2022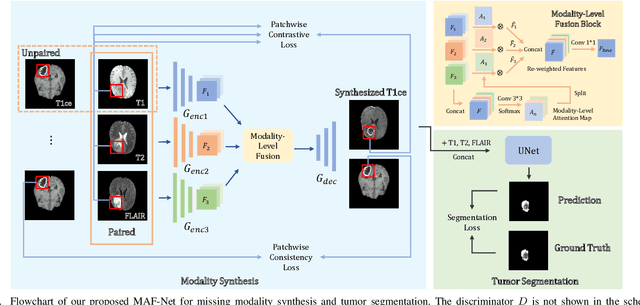
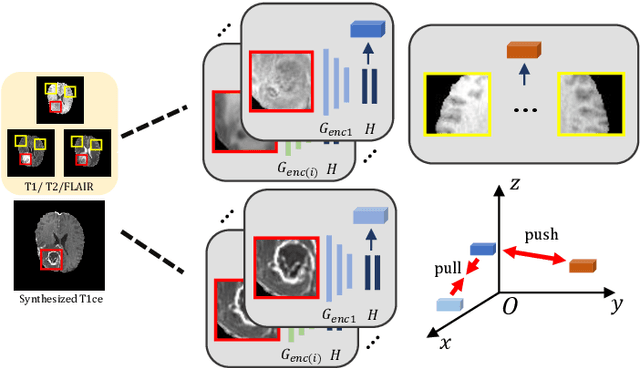
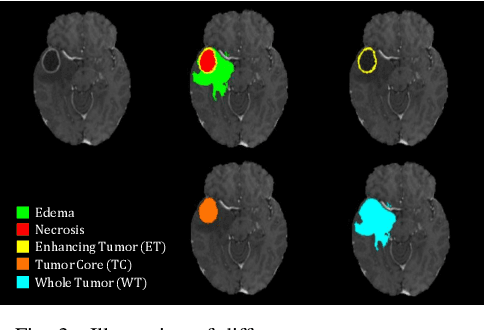
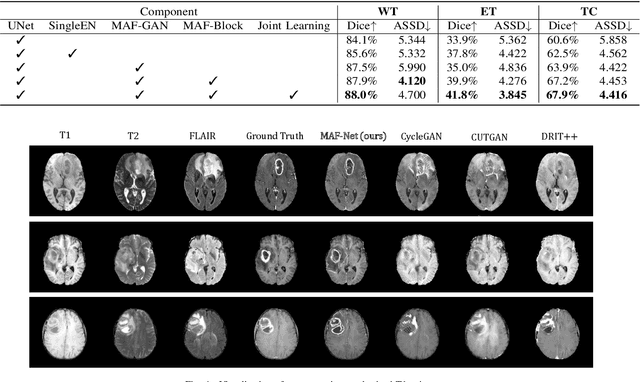
Multi-modal magnetic resonance (MR) imaging provides great potential for diagnosing and analyzing brain gliomas. In clinical scenarios, common MR sequences such as T1, T2 and FLAIR can be obtained simultaneously in a single scanning process. However, acquiring contrast enhanced modalities such as T1ce requires additional time, cost, and injection of contrast agent. As such, it is clinically meaningful to develop a method to synthesize unavailable modalities which can also be used as additional inputs to downstream tasks (e.g., brain tumor segmentation) for performance enhancing. In this work, we propose an end-to-end framework named Modality-Level Attention Fusion Network (MAF-Net), wherein we innovatively conduct patchwise contrastive learning for extracting multi-modal latent features and dynamically assigning attention weights to fuse different modalities. Through extensive experiments on BraTS2020, our proposed MAF-Net is found to yield superior T1ce synthesis performance (SSIM of 0.8879 and PSNR of 22.78) and accurate brain tumor segmentation (mean Dice scores of 67.9%, 41.8% and 88.0% on segmenting the tumor core, enhancing tumor and whole tumor).