 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Aware End-to-end Mispronunciation Detection and Diagnosis
Paper and Code
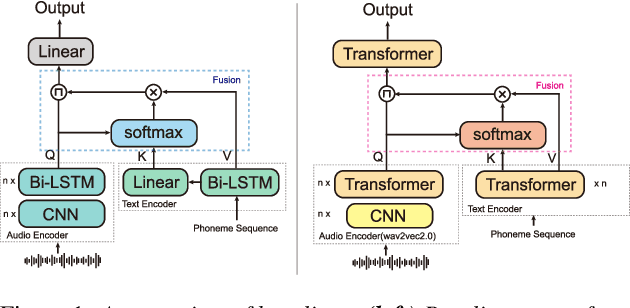
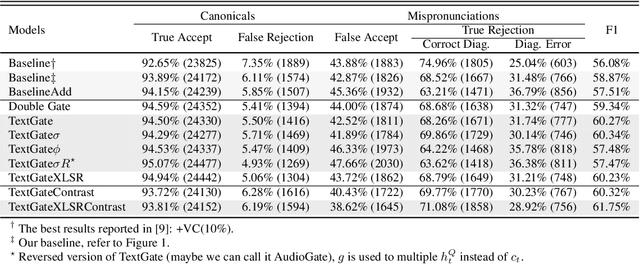
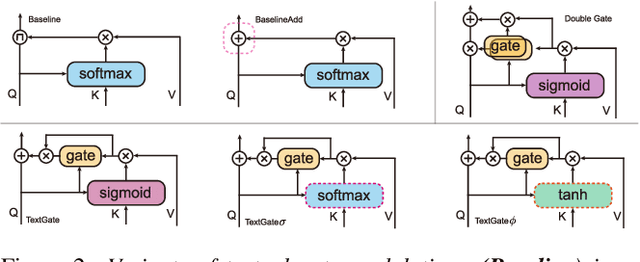
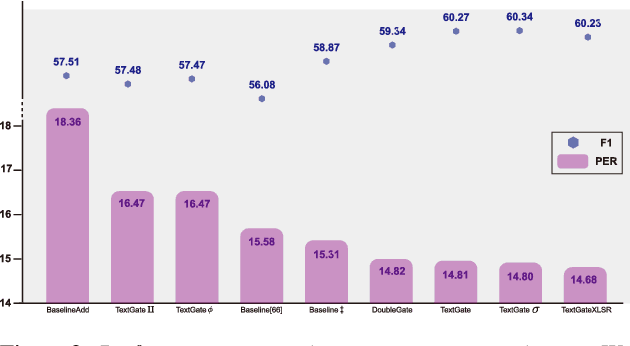
Mispronunciation detection and diagnosis (MDD) technology is a key component of computer-assisted pronunciation training system (CAPT). In the field of assessing the pronunciation quality of constrained speech, the given transcriptions can play the role of a teacher. Conventional methods have fully utilized the prior texts for the model construction or improving the system performance, e.g. forced-alignment and extended recognition networks. Recently, some end-to-end based methods attempt to incorporate the prior texts into model training and preliminarily show the effectiveness. However, previous studies mostly consider applying raw attention mechanism to fuse audio representations with text representations, without taking possible text-pronunciation mismatch into account. In this paper, we present a gating strategy that assigns more importance to the relevant audio features while suppressing irrelevant text information. Moreover, given the transcriptions, we design an extra contrastive loss to reduce the gap between the learning objective of phoneme recognition and MDD. We conducted experiments using two publicly available datasets (TIMIT and L2-Arctic) and our best model improved the F1 score from $57.51\%$ to $61.75\%$ compared to the baselines. Besides, we provide a detailed analysis to shed light on the effectiveness of gating mechanism and contrastive learning on MDD.