 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Aware End-to-end Mispronunciation Detection and Diagnosis
Jun 15, 2022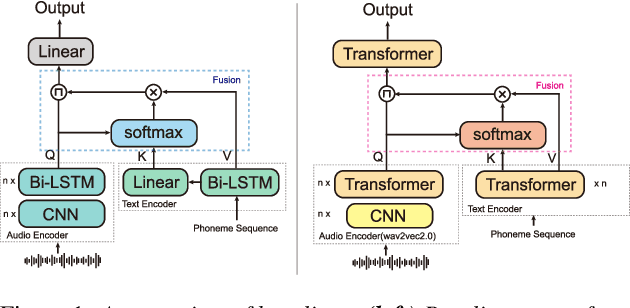
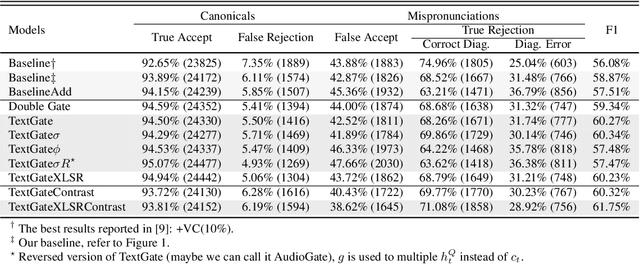
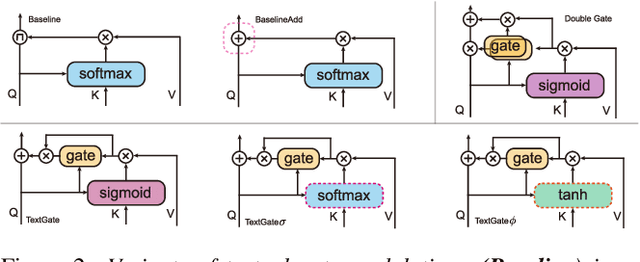
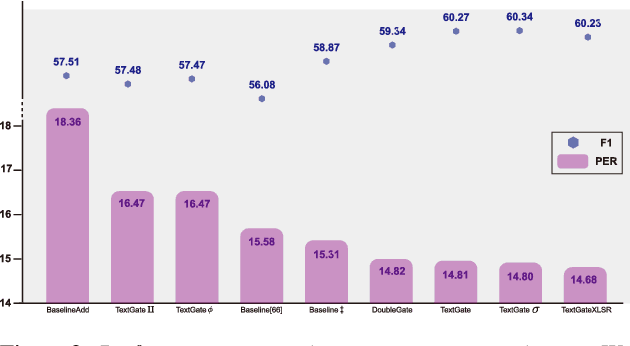
Mispronunciation detection and diagnosis (MDD) technology is a key component of computer-assisted pronunciation training system (CAPT). In the field of assessing the pronunciation quality of constrained speech, the given transcriptions can play the role of a teacher. Conventional methods have fully utilized the prior texts for the model construction or improving the system performance, e.g. forced-alignment and extended recognition networks. Recently, some end-to-end based methods attempt to incorporate the prior texts into model training and preliminarily show the effectiveness. However, previous studies mostly consider applying raw attention mechanism to fuse audio representations with text representations, without taking possible text-pronunciation mismatch into account. In this paper, we present a gating strategy that assigns more importance to the relevant audio features while suppressing irrelevant text information. Moreover, given the transcriptions, we design an extra contrastive loss to reduce the gap between the learning objective of phoneme recognition and MDD. We conducted experiments using two publicly available datasets (TIMIT and L2-Arctic) and our best model improved the F1 score from $57.51\%$ to $61.75\%$ compared to the baselines. Besides, we provide a detailed analysis to shed light on the effectiveness of gating mechanism and contrastive learning on MDD.
Speech Enhancement using Separable Polling Attention and Global Layer Normalization followed with PReLU
May 06, 2021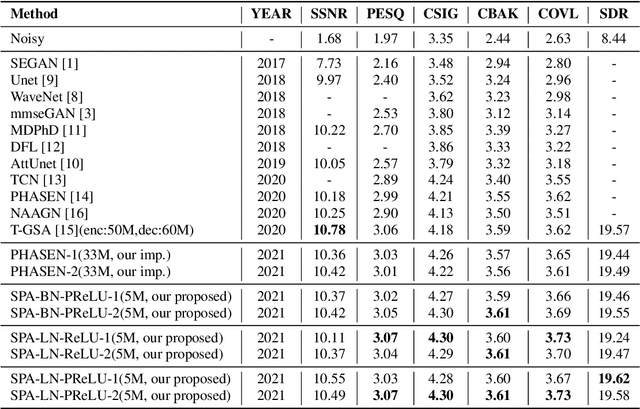
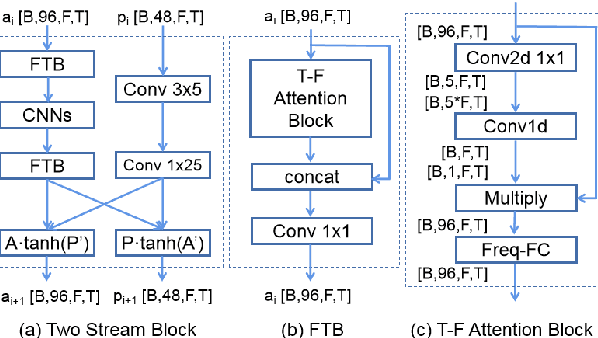


Single channel speech enhancement is a challenging task in speech community. Recently, various neural networks based methods have been applied to speech enhancement. Among these models, PHASEN and T-GSA achieve state-of-the-art performances on the publicly opened VoiceBank+DEMAND corpus. Both of the models reach the COVL score of 3.62. PHASEN achieves the highest CSIG score of 4.21 while T-GSA gets the highest PESQ score of 3.06. However, both of these two models are very large. The contradiction between the model performance and the model size is hard to reconcile. In this paper, we introduce three kinds of techniques to shrink the PHASEN model and improve the performance. Firstly, seperable polling attention is proposed to replace the frequency transformation blocks in PHASEN. Secondly, global layer normalization followed with PReLU is used to replace batch normalization followed with ReLU. Finally, BLSTM in PHASEN is replaced with Conv2d operation and the phase stream is simplified. With all these modifications, the size of the PHASEN model is shrunk from 33M parameters to 5M parameters, while the performance on VoiceBank+DEMAND is improved to the CSIG score of 4.30, the PESQ score of 3.07 and the COVL score of 3.73.
A Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques
Apr 17, 2021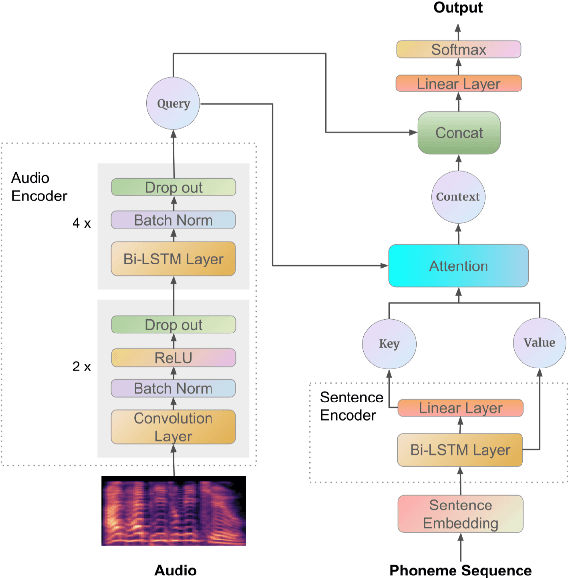
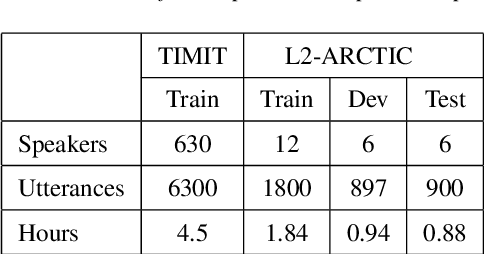
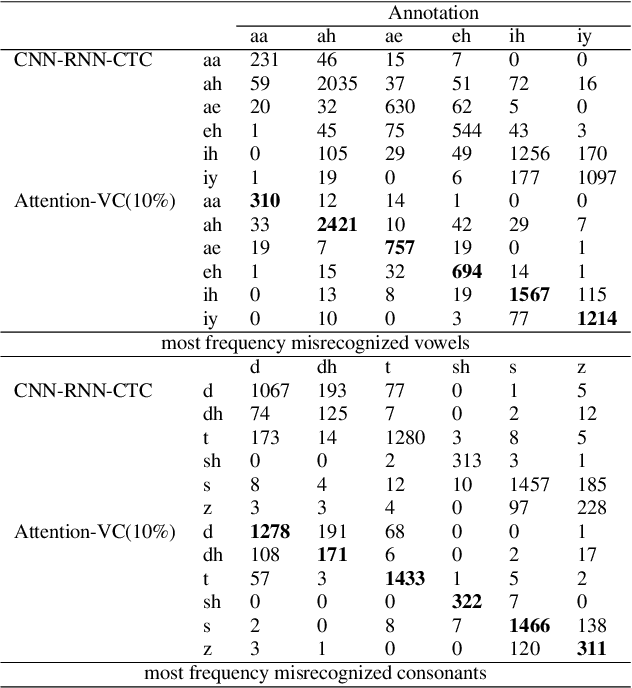
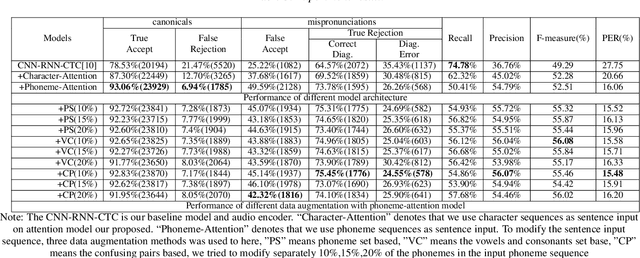
Recently, end-to-end mispronunciation detection and diagnosis (MD&D) systems has become a popular alternative to greatly simplify the model-building process of conventional hybrid DNN-HMM systems by representing complicated modules with a single deep network architecture. In this paper, in order to utilize the prior text in the end-to-end structure, we present a novel text-dependent model which is difference with sed-mdd, the model achieves a fully end-to-end system by aligning the audio with the phoneme sequences of the prior text inside the model through the attention mechanism. Moreover, the prior text as input will be a problem of imbalance between positive and negative samples in the phoneme sequence. To alleviate this problem, we propose three simple data augmentation methods, which effectively improve the ability of model to capture mispronounced phonemes. We conduct experiments on L2-ARCTIC, and our best performance improved from 49.29% to 56.08% in F-measure metric compared to the CNN-RNN-CTC model.
Convolution Forgetting Curve Model for Repeated Learning
Jan 19, 2019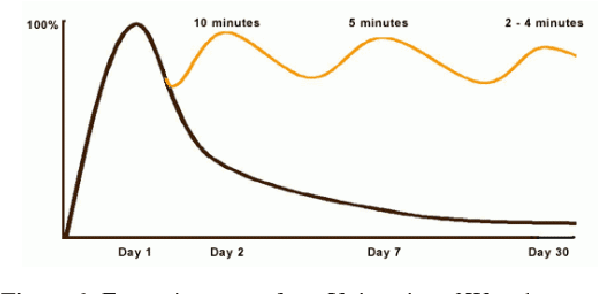
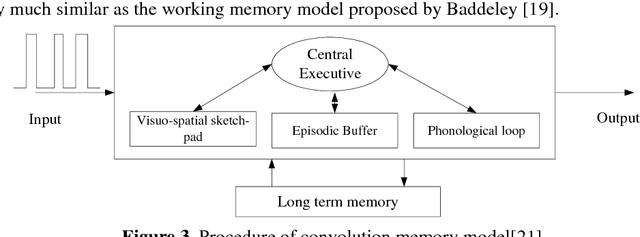
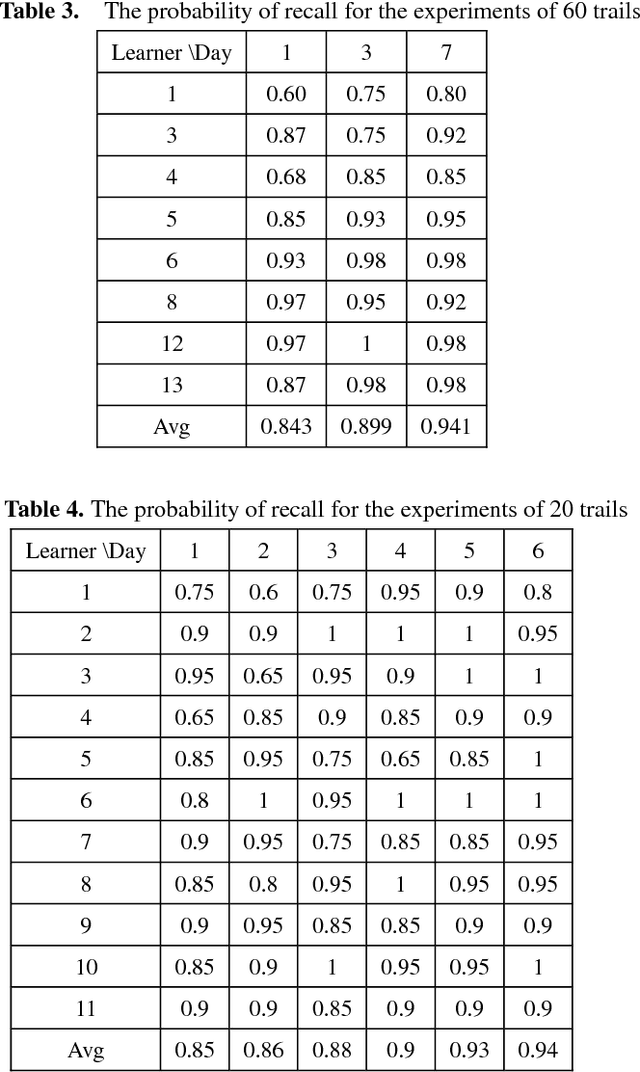
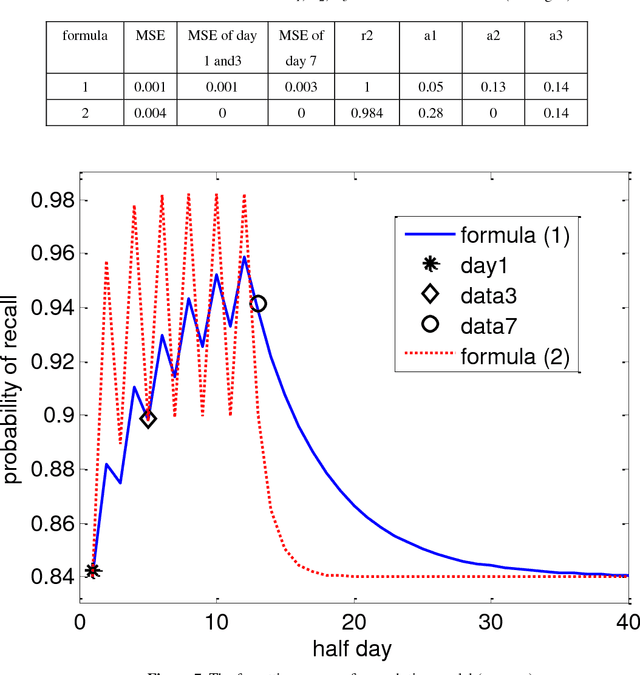
Most of mathematic forgetting curve models fit well with the forgetting data under the learning condition of one time rather than repeated. In the paper, a convolution model of forgetting curve is proposed to simulate the memory process during learning. In this model, the memory ability (i.e. the central procedure in the working memory model) and learning material (i.e. the input in the working memory model) is regarded as the system function and the input function, respectively. The status of forgetting (i.e. the output in the working memory model) is regarded as output function or the convolution result of the memory ability and learning material. The model is applied to simulate the forgetting curves in different situations. The results show that the model is able to simulate the forgetting curves not only in one time learning condition but also in multi-times condition. The model is further verified in the experiments of Mandarin tone learning for Japanese learners. And the predicted curve fits well on the test points.