 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3DP: Real-Time 3D-Aware Policy for Embodied Manipulation
Mar 15, 2026Embodied manipulation requires accurate 3D understanding of objects and their spatial relations to plan and execute contact-rich actions. While large-scale 3D vision models provide strong priors, their computational cost incurs prohibitive latency for real-time control. We propose Real-time 3D-aware Policy (R3DP), which integrates powerful 3D priors into manipulation policies without sacrificing real-time performance. A core innovation of R3DP is the asynchronous fast-slow collaboration module, which seamlessly integrates large-scale 3D priors into the policy without compromising real-time performance. The system maintains real-time efficiency by querying the pre-trained slow system (VGGT) only on sparse key frames, while simultaneously employing a lightweight Temporal Feature Prediction Network (TFPNet) to predict features for all intermediate frames. By leveraging historical data to exploit temporal correlations, TFPNet explicitly improves task success rates through consistent feature estimation. Additionally, to enable more effective multi-view fusion, we introduce a Multi-View Feature Fuser (MVFF) that aggregates features across views by explicitly incorporating camera intrinsics and extrinsics. R3DP offers a plug-and-play solution for integrating large models into real-time inference systems. We evaluate R3DP against multiple baselines across different visual configurations. R3DP effectively harnesses large-scale 3D priors to achieve superior results, outperforming single-view and multi-view DP by 32.9% and 51.4% in average success rate, respectively. Furthermore, by decoupling heavy 3D reasoning from policy execution, R3DP achieves a 44.8% reduction in inference time compared to a naive DP+VGGT integration.
Where to Go Next Day: Multi-scale Spatial-Temporal Decoupled Model for Mid-term Human Mobility Prediction
Jan 11, 2025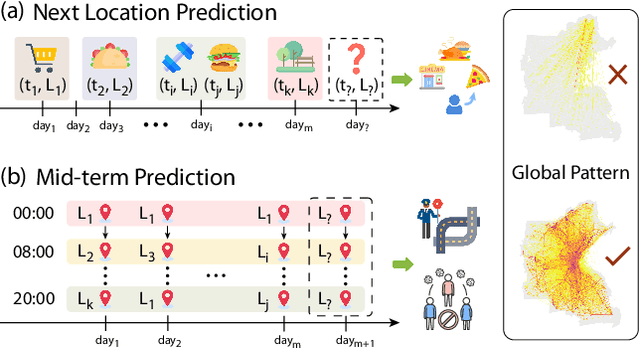
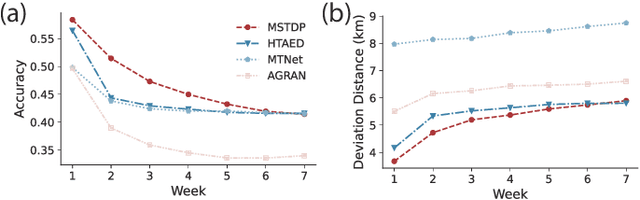
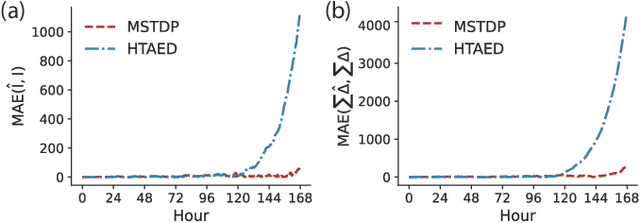
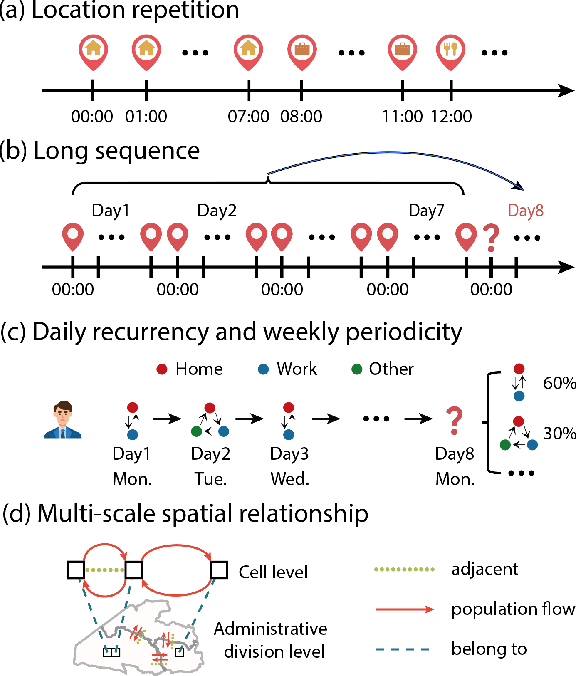
Predicting individual mobility patterns is crucial across various applications. While current methods mainly focus on predicting the next location for personalized services like recommendations, they often fall short in supporting broader applications such as traffic management and epidemic control, which require longer period forecasts of human mobility. This study addresses mid-term mobility prediction, aiming to capture daily travel patterns and forecast trajectories for the upcoming day or week. We propose a novel Multi-scale Spatial-Temporal Decoupled Predictor (MSTDP) designed to efficiently extract spatial and temporal information by decoupling daily trajectories into distinct location-duration chains. Our approach employs a hierarchical encoder to model multi-scale temporal patterns, including daily recurrence and weekly periodicity, and utilizes a transformer-based decoder to globally attend to predicted information in the location or duration chain. Additionally, we introduce a spatial heterogeneous graph learner to capture multi-scale spatial relationships, enhancing semantic-rich representations. Extensive experiments, including statistical physics analysis, are conducted on large-scale mobile phone records in five cities (Boston, Los Angeles, SF Bay Area, Shanghai, and Tokyo), to demonstrate MSTDP's advantages. Applied to epidemic modeling in Boston, MSTDP significantly outperforms the best-performing baseline, achieving a remarkable 62.8% reduction in MAE for cumulative new cases.
TrajGEOS: Trajectory Graph Enhanced Orientation-based Sequential Network for Mobility Prediction
Dec 26, 2024Human mobility studies how people move to access their needed resources and plays a significant role in urban planning and location-based services. As a paramount task of human mobility modeling, next location prediction is challenging because of the diversity of users' historical trajectories that gives rise to complex mobility patterns and various contexts. Deep sequential models have been widely used to predict the next location by leveraging the inherent sequentiality of trajectory data. However, they do not fully leverage the relationship between locations and fail to capture users' multi-level preferences. This work constructs a trajectory graph from users' historical traces and proposes a \textbf{Traj}ectory \textbf{G}raph \textbf{E}nhanced \textbf{O}rientation-based \textbf{S}equential network (TrajGEOS) for next-location prediction tasks. TrajGEOS introduces hierarchical graph convolution to capture location and user embeddings. Such embeddings consider not only the contextual feature of locations but also the relation between them, and serve as additional features in downstream modules. In addition, we design an orientation-based module to learn users' mid-term preferences from sequential modeling modules and their recent trajectories. Extensive experiments on three real-world LBSN datasets corroborate the value of graph and orientation-based modules and demonstrate that TrajGEOS outperforms the state-of-the-art methods on the next location prediction task.
Optimizing Multispectral Object Detection: A Bag of Tricks and Comprehensive Benchmarks
Nov 27, 2024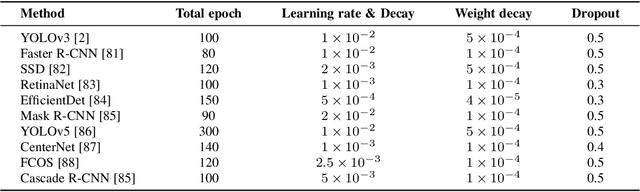
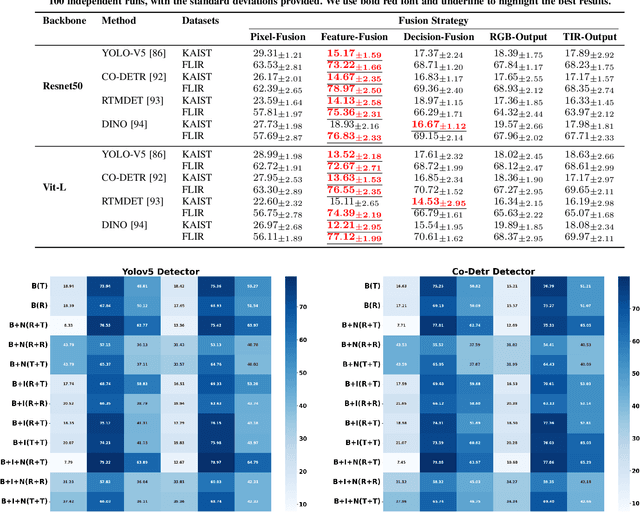
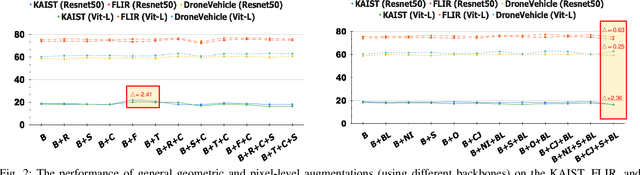
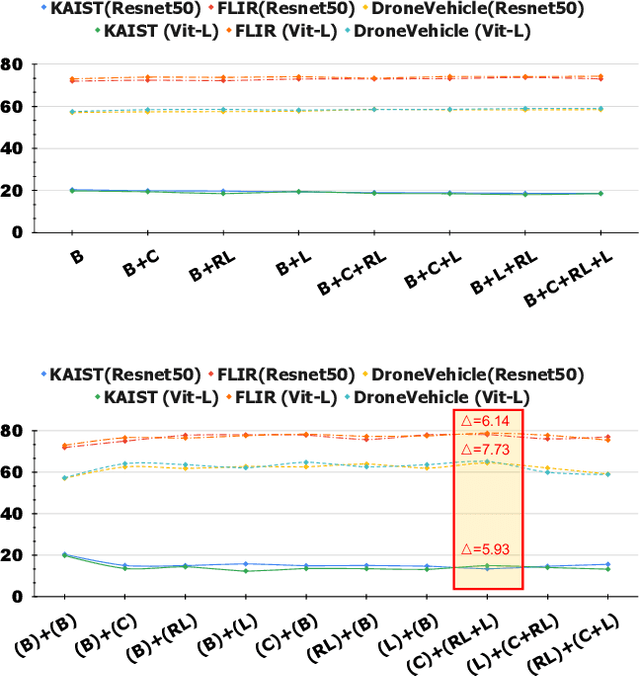
Multispectral object detection, utilizing RGB and TIR (thermal infrared) modalities, is widely recognized as a challenging task. It requires not only the effective extraction of features from both modalities and robust fusion strategies, but also the ability to address issues such as spectral discrepancies, spatial misalignment, and environmental dependencies between RGB and TIR images. These challenges significantly hinder the generalization of multispectral detection systems across diverse scenarios. Although numerous studies have attempted to overcome these limitations, it remains difficult to clearly distinguish the performance gains of multispectral detection systems from the impact of these "optimization techniques". Worse still, despite the rapid emergence of high-performing single-modality detection models, there is still a lack of specialized training techniques that can effectively adapt these models for multispectral detection tasks. The absence of a standardized benchmark with fair and consistent experimental setups also poses a significant barrier to evaluating the effectiveness of new approaches. To this end, we propose the first fair and reproducible benchmark specifically designed to evaluate the training "techniques", which systematically classifies existing multispectral object detection methods, investigates their sensitivity to hyper-parameters, and standardizes the core configurations. A comprehensive evaluation is conducted across multiple representative multispectral object detection datasets, utilizing various backbone networks and detection frameworks. Additionally, we introduce an efficient and easily deployable multispectral object detection framework that can seamlessly optimize high-performing single-modality models into dual-modality models, integrating our advanced training techniques.
Learning Chemical Reaction Representation with Reactant-Product Alignment
Nov 26, 2024



Organic synthesis stands as a cornerstone of chemical industry. The development of robust machine learning models to support tasks associated with organic reactions is of significant interest. However, current methods rely on hand-crafted features or direct adaptations of model architectures from other domains, which lacks feasibility as data scales increase or overlook the rich chemical information inherent in reactions. To address these issues, this paper introduces {\modelname}, a novel chemical reaction representation learning model tailored for a variety of organic-reaction-related tasks. By integrating atomic correspondence between reactants and products, our model discerns the molecular transformations that occur during the reaction, thereby enhancing the comprehension of the reaction mechanism. We have designed an adapter structure to incorporate reaction conditions into the chemical reaction representation, allowing the model to handle diverse reaction conditions and adapt to various datasets and downstream tasks, e.g., reaction performance prediction. Additionally, we introduce a reaction-center aware attention mechanism that enables the model to concentrate on key functional groups, thereby generating potent representations for chemical reactions. Our model has been evaluated on a range of downstream tasks, including reaction condition prediction, reaction yield prediction, and reaction selectivity prediction. Experimental results indicate that our model markedly outperforms existing chemical reaction representation learning architectures across all tasks. Notably, our model significantly outperforms all the baselines with up to 25\% (top-1) and 16\% (top-10) increased accuracy over the strongest baseline on USPTO\_CONDITION dataset for reaction condition prediction. We plan to open-source the code contingent upon the acceptance of the paper.
Text-Augmented Multimodal LLMs for Chemical Reaction Condition Recommendation
Jul 21, 2024High-throughput reaction condition (RC) screening is fundamental to chemical synthesis. However, current RC screening suffers from laborious and costly trial-and-error workflows. Traditional computer-aided synthesis planning (CASP) tools fail to find suitable RCs due to data sparsity and inadequate reaction representations. Nowadays, large language models (LLMs) are capable of tackling chemistry-related problems, such as molecule design, and chemical logic Q\&A tasks. However, LLMs have not yet achieved accurate predictions of chemical reaction conditions. Here, we present MM-RCR, a text-augmented multimodal LLM that learns a unified reaction representation from SMILES, reaction graphs, and textual corpus for chemical reaction recommendation (RCR). To train MM-RCR, we construct 1.2 million pair-wised Q\&A instruction datasets. Our experimental results demonstrate that MM-RCR achieves state-of-the-art performance on two open benchmark datasets and exhibits strong generalization capabilities on out-of-domain (OOD) and High-Throughput Experimentation (HTE) datasets. MM-RCR has the potential to accelerate high-throughput condition screening in chemical synthesis.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
Swap-based Deep Reinforcement Learning for Facility Location Problems in Networks
Dec 25, 2023Facility location problems on graphs are ubiquitous in real world and hold significant importance, yet their resolution is often impeded by NP-hardness. Recently, machine learning methods have been proposed to tackle such classical problems, but they are limited to the myopic constructive pattern and only consider the problems in Euclidean space. To overcome these limitations, we propose a general swap-based framework that addresses the p-median problem and the facility relocation problem on graphs and a novel reinforcement learning model demonstrating a keen awareness of complex graph structures. Striking a harmonious balance between solution quality and running time, our method surpasses handcrafted heuristics on intricate graph datasets. Additionally, we introduce a graph generation process to simulate real-world urban road networks with demand, facilitating the construction of large datasets for the classic problem. For the initialization of the locations of facilities, we introduce a physics-inspired strategy for the p-median problem, reaching more stable solutions than the random strategy. The proposed pipeline coupling the classic swap-based method with deep reinforcement learning marks a significant step forward in addressing the practical challenges associated with facility location on graphs.
Modeling Complex Mathematical Reasoning via Large Language Model based MathAgent
Dec 17, 2023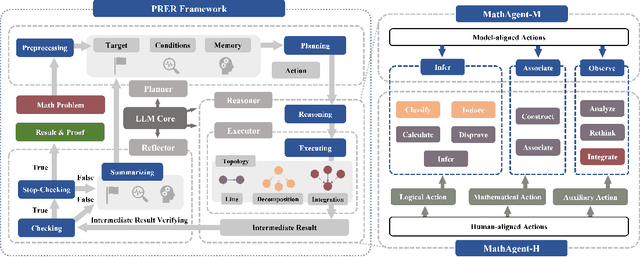
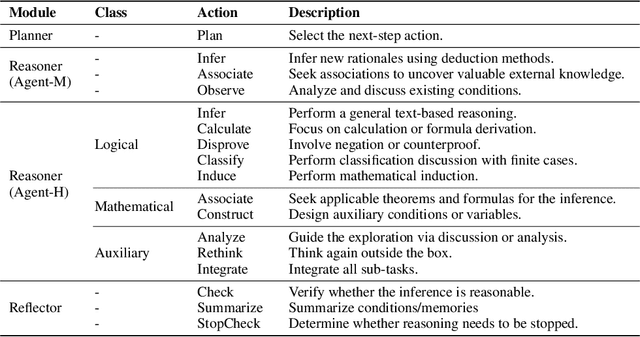
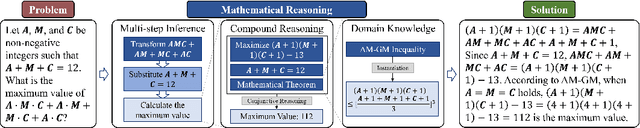
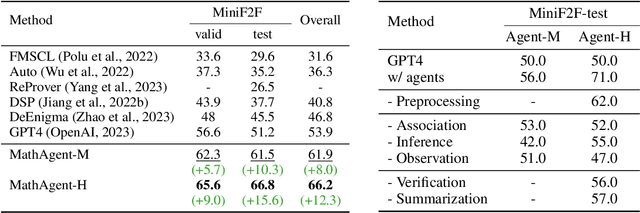
Large language models (LLMs) face challenges in solving complex mathematical problems that require comprehensive capacities to parse the statements, associate domain knowledge, perform compound logical reasoning, and integrate the intermediate rationales. Tackling all these problems once could be arduous for LLMs, thus leading to confusion in generation. In this work, we explore the potential of enhancing LLMs with agents by meticulous decomposition and modeling of mathematical reasoning process. Specifically, we propose a formal description of the mathematical solving and extend LLMs with an agent-based zero-shot framework named $\bf{P}$lanner-$\bf{R}$easoner-$\bf{E}$xecutor-$\bf{R}$eflector (PRER). We further provide and implement two MathAgents that define the logical forms and inherent relations via a pool of actions in different grains and orientations: MathAgent-M adapts its actions to LLMs, while MathAgent-H aligns with humankind. Experiments on miniF2F and MATH have demonstrated the effectiveness of PRER and proposed MathAgents, achieving an increase of $12.3\%$($53.9\%\xrightarrow{}66.2\%$) on the MiniF2F, $9.2\%$ ($49.8\%\xrightarrow{}59.0\%$) on MATH, and $13.2\%$($23.2\%\xrightarrow{}35.4\%$) for level-5 problems of MATH against GPT-4. Further analytical results provide more insightful perspectives on exploiting the behaviors of LLMs as agents.
Human Mobility Prediction with Causal and Spatial-constrained Multi-task Network
Jun 12, 2022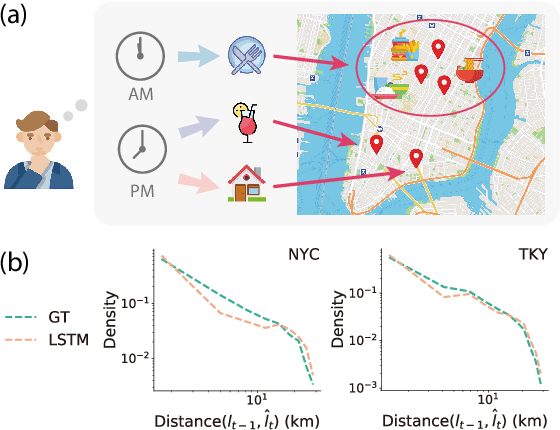
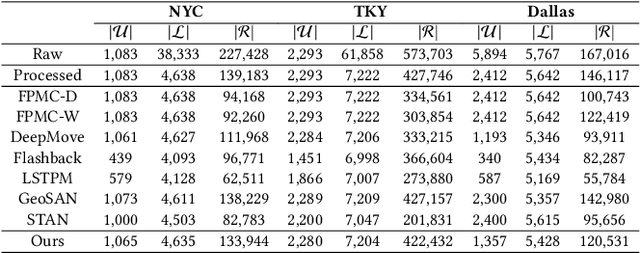
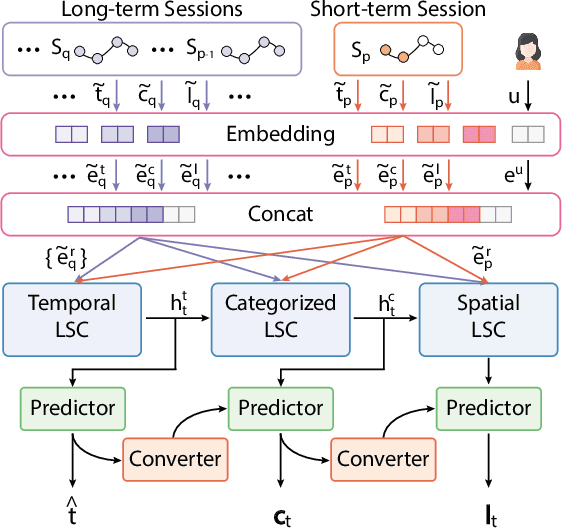
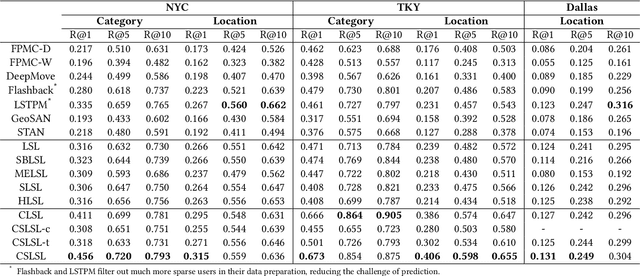
Modeling human mobility helps to understand how people are accessing resources and physically contacting with each other in cities, and thus contributes to various applications such as urban planning, epidemic control, and location-based advertisement. Next location prediction is one decisive task in individual human mobility modeling and is usually viewed as sequence modeling, solved with Markov or RNN-based methods. However, the existing models paid little attention to the logic of individual travel decisions and the reproducibility of the collective behavior of population. To this end, we propose a Causal and Spatial-constrained Long and Short-term Learner (CSLSL) for next location prediction. CSLSL utilizes a causal structure based on multi-task learning to explicitly model the "when$\rightarrow$what$\rightarrow$where", a.k.a. "time$\rightarrow$activity$\rightarrow$location" decision logic. We next propose a spatial-constrained loss function as an auxiliary task, to ensure the consistency between the predicted and actual spatial distribution of travelers' destinations. Moreover, CSLSL adopts modules named Long and Short-term Capturer (LSC) to learn the transition regularities across different time spans. Extensive experiments on three real-world datasets show a 33.4% performance improvement of CSLSL over baselines and confirm the effectiveness of introducing the causality and consistency constraints. The implementation is available at https://github.com/urbanmobility/CSLSL.