 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rollout from Sampling:An R1-Style Tokenized Traffic Simulation Model
Mar 26, 2026Learning diverse and high-fidelity traffic simulations from human driving demonstrations is crucial for autonomous driving evaluation. The recent next-token prediction (NTP) paradigm, widely adopted in large language models (LLMs), has been applied to traffic simulation and achieves iterative improvements via supervised fine-tuning (SFT). However, such methods limit active exploration of potentially valuable motion tokens, particularly in suboptimal regions. Entropy patterns provide a promising perspective for enabling exploration driven by motion token uncertainty. Motivated by this insight, we propose a novel tokenized traffic simulation policy, R1Sim, which represents an initial attempt to explore reinforcement learning based on motion token entropy patterns, and systematically analyzes the impact of different motion tokens on simulation outcomes. Specifically, we introduce an entropy-guided adaptive sampling mechanism that focuses on previously overlooked motion tokens with high uncertainty yet high potential. We further optimize motion behaviors using Group Relative Policy Optimization (GRPO), guided by a safety-aware reward design. Overall, these components enable a balanced exploration-exploitation trade-off through diverse high-uncertainty sampling and group-wise comparative estimation, resulting in realistic, safe, and diverse multi-agent behaviors. Extensive experiments on the Waymo Sim Agent benchmark demonstrate that R1Sim achieves competitive performance compared to state-of-the-art methods.
Connect the Dots: Knowledge Graph-Guided Crawler Attack on Retrieval-Augmented Generation Systems
Jan 22, 2026Retrieval-augmented generation (RAG) systems integrate document retrieval with large language models and have been widely adopted. However, in privacy-related scenarios, RAG introduces a new privacy risk: adversaries can issue carefully crafted queries to exfiltrate sensitive content from the underlying corpus gradually. Although recent studies have demonstrated multi-turn extraction attacks, they rely on heuristics and fail to perform long-term extraction planning. To address these limitations, we formulate the RAG extraction attack as an adaptive stochastic coverage problem (ASCP). In ASCP, each query is treated as a probabilistic action that aims to maximize conditional marginal gain (CMG), enabling principled long-term planning under uncertainty. However, integrating ASCP with practical RAG attack faces three key challenges: unobservable CMG, intractability in the action space, and feasibility constraints. To overcome these challenges, we maintain a global attacker-side state to guide the attack. Building on this idea, we introduce RAGCRAWLER, which builds a knowledge graph to represent revealed information, uses this global state to estimate CMG, and plans queries in semantic space that target unretrieved regions. In comprehensive experiments across diverse RAG architectures and datasets, our proposed method, RAGCRAWLER, consistently outperforms all baselines. It achieves up to 84.4% corpus coverage within a fixed query budget and deliver an average improvement of 20.7% over the top-performing baseline. It also maintains high semantic fidelity and strong content reconstruction accuracy with low attack cost. Crucially, RAGCRAWLER proves its robustness by maintaining effectiveness against advanced RAG systems employing query rewriting and multi-query retrieval strategies. Our work reveals significant security gaps and highlights the pressing need for stronger safeguards for RAG.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025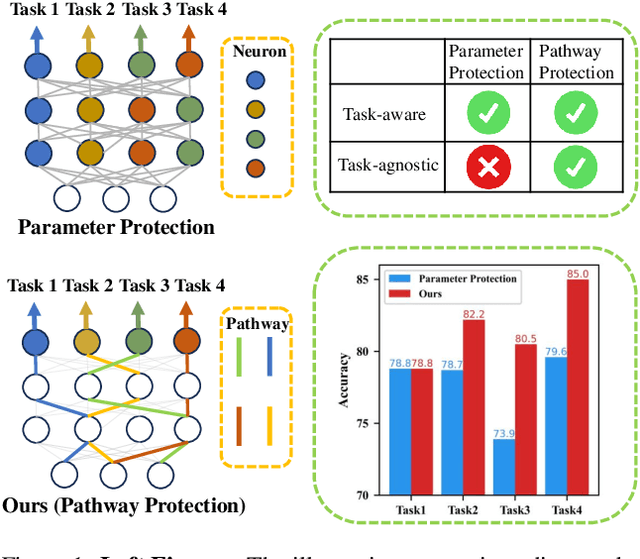
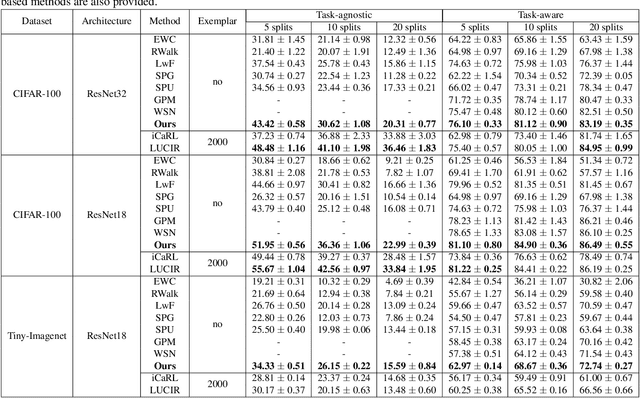
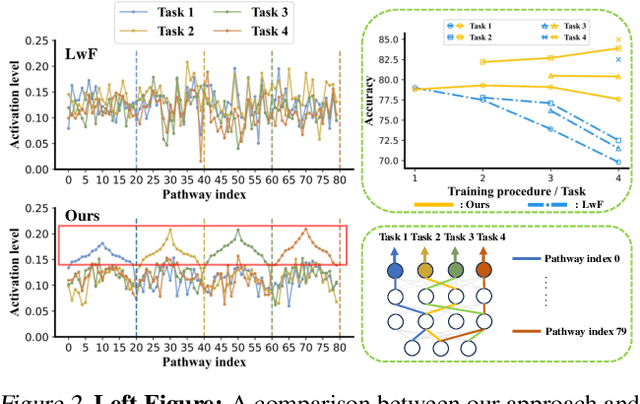
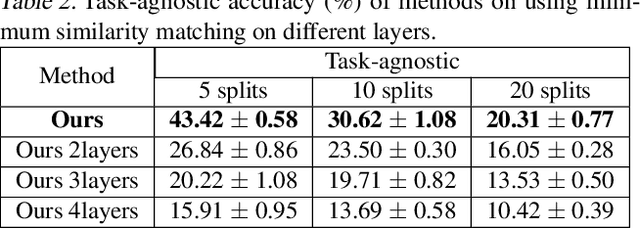
Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
A Unified and Scalable Membership Inference Method for Visual Self-supervised Encoder via Part-aware Capability
May 15, 2025Self-supervised learning shows promise in harnessing extensive unlabeled data, but it also confronts significant privacy concerns, especially in vision. In this paper, we perform membership inference on visual self-supervised models in a more realistic setting: self-supervised training method and details are unknown for an adversary when attacking as he usually faces a black-box system in practice. In this setting, considering that self-supervised model could be trained by completely different self-supervised paradigms, e.g., masked image modeling and contrastive learning, with complex training details, we propose a unified membership inference method called PartCrop. It is motivated by the shared part-aware capability among models and stronger part response on the training data. Specifically, PartCrop crops parts of objects in an image to query responses within the image in representation space. We conduct extensive attacks on self-supervised models with different training protocols and structures using three widely used image datasets. The results verify the effectiveness and generalization of PartCrop. Moreover, to defend against PartCrop, we evaluate two common approaches, i.e., early stop and differential privacy, and propose a tailored method called shrinking crop scale range. The defense experiments indicate that all of them are effective. Finally, besides prototype testing on toy visual encoders and small-scale image datasets, we quantitatively study the impacts of scaling from both data and model aspects in a realistic scenario and propose a scalable PartCrop-v2 by introducing two structural improvements to PartCrop. Our code is at https://github.com/JiePKU/PartCrop.
Moss: Proxy Model-based Full-Weight Aggregation in Federated Learning with Heterogeneous Models
Mar 13, 2025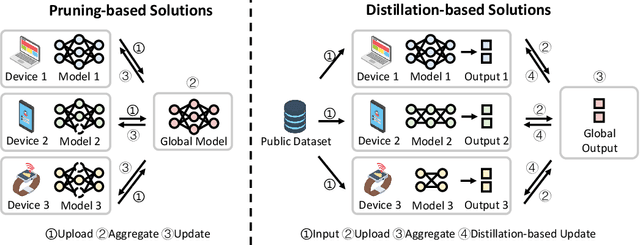
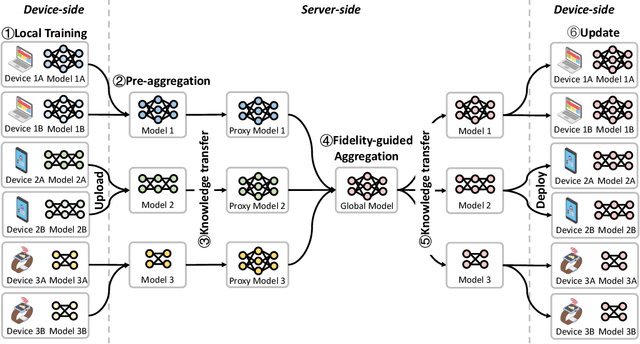

Modern Federated Learning (FL) has become increasingly essential for handling highly heterogeneous mobile devices. Current approaches adopt a partial model aggregation paradigm that leads to sub-optimal model accuracy and higher training overhead. In this paper, we challenge the prevailing notion of partial-model aggregation and propose a novel "full-weight aggregation" method named Moss, which aggregates all weights within heterogeneous models to preserve comprehensive knowledge. Evaluation across various applications demonstrates that Moss significantly accelerates training, reduces on-device training time and energy consumption, enhances accuracy, and minimizes network bandwidth utilization when compared to state-of-the-art baselines.
TEESlice: Protecting Sensitive Neural Network Models in Trusted Execution Environments When Attackers have Pre-Trained Models
Nov 15, 2024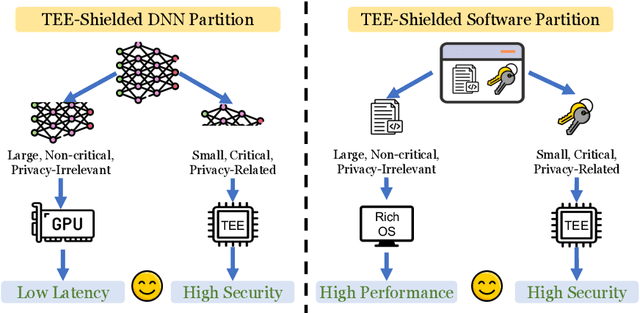
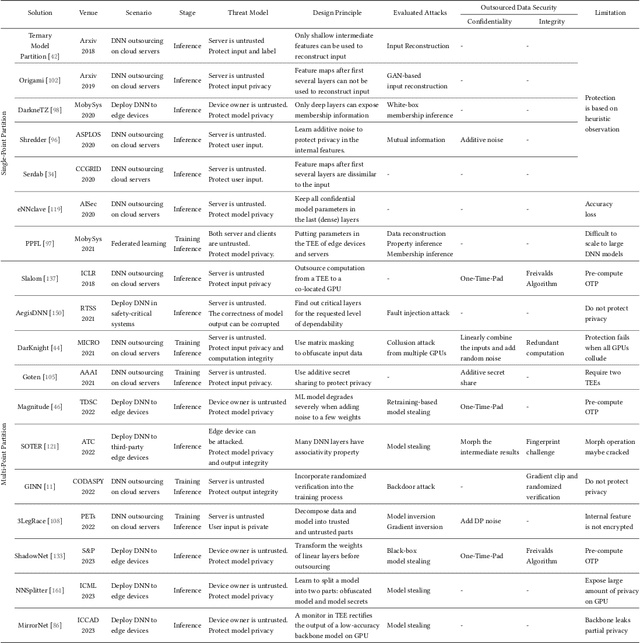
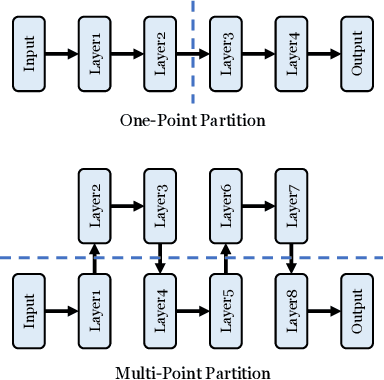
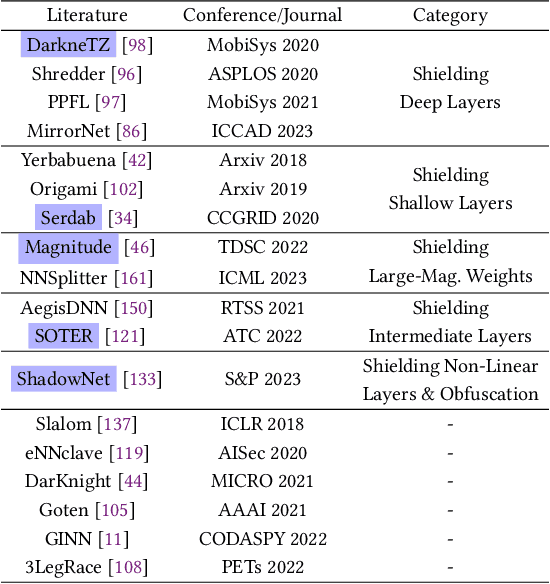
Trusted Execution Environments (TEE) are used to safeguard on-device models. However, directly employing TEEs to secure the entire DNN model is challenging due to the limited computational speed. Utilizing GPU can accelerate DNN's computation speed but commercial widely-available GPUs usually lack security protection. To this end, scholars introduce TSDP, a method that protects privacy-sensitive weights within TEEs and offloads insensitive weights to GPUs. Nevertheless, current methods do not consider the presence of a knowledgeable adversary who can access abundant publicly available pre-trained models and datasets. This paper investigates the security of existing methods against such a knowledgeable adversary and reveals their inability to fulfill their security promises. Consequently, we introduce a novel partition before training strategy, which effectively separates privacy-sensitive weights from other components of the model. Our evaluation demonstrates that our approach can offer full model protection with a computational cost reduced by a factor of 10. In addition to traditional CNN models, we also demonstrate the scalability to large language models. Our approach can compress the private functionalities of the large language model to lightweight slices and achieve the same level of protection as the shielding-whole-model baseline.
Text-Augmented Multimodal LLMs for Chemical Reaction Condition Recommendation
Jul 21, 2024High-throughput reaction condition (RC) screening is fundamental to chemical synthesis. However, current RC screening suffers from laborious and costly trial-and-error workflows. Traditional computer-aided synthesis planning (CASP) tools fail to find suitable RCs due to data sparsity and inadequate reaction representations. Nowadays, large language models (LLMs) are capable of tackling chemistry-related problems, such as molecule design, and chemical logic Q\&A tasks. However, LLMs have not yet achieved accurate predictions of chemical reaction conditions. Here, we present MM-RCR, a text-augmented multimodal LLM that learns a unified reaction representation from SMILES, reaction graphs, and textual corpus for chemical reaction recommendation (RCR). To train MM-RCR, we construct 1.2 million pair-wised Q\&A instruction datasets. Our experimental results demonstrate that MM-RCR achieves state-of-the-art performance on two open benchmark datasets and exhibits strong generalization capabilities on out-of-domain (OOD) and High-Throughput Experimentation (HTE) datasets. MM-RCR has the potential to accelerate high-throughput condition screening in chemical synthesis.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024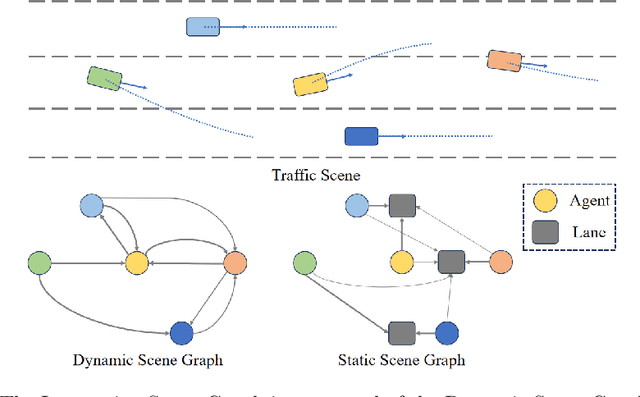
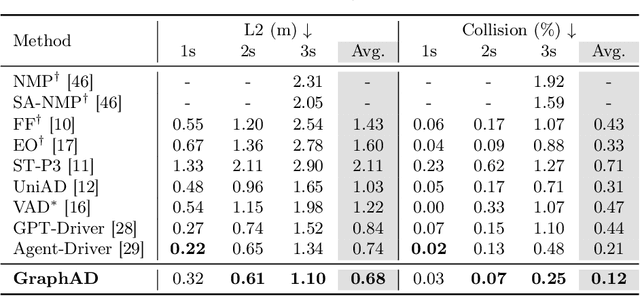
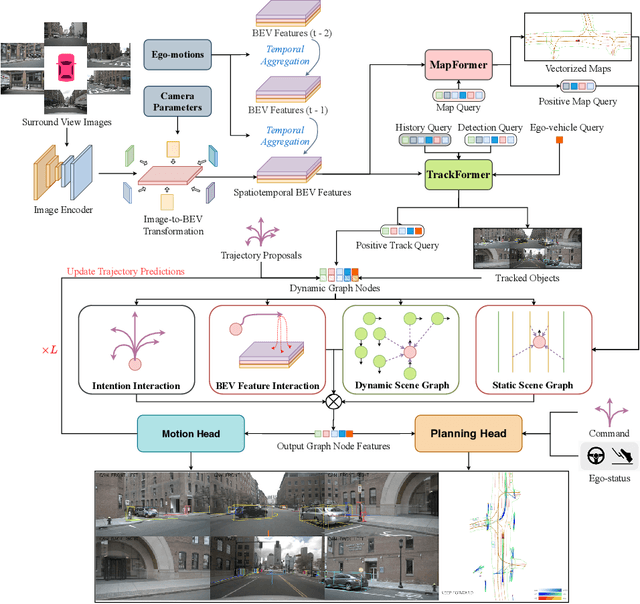
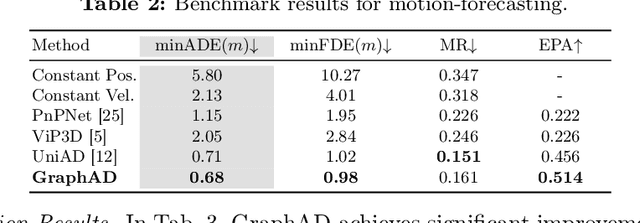
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
A Unified Membership Inference Method for Visual Self-supervised Encoder via Part-aware Capability
Apr 03, 2024

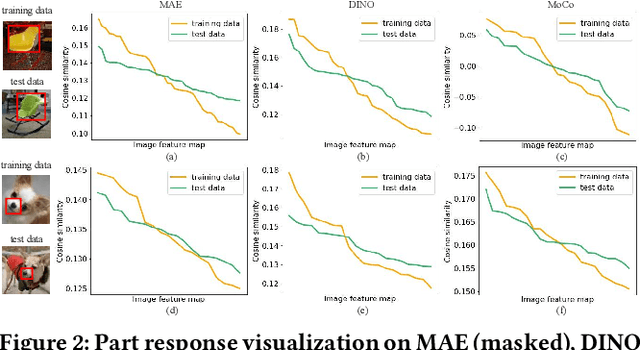
Self-supervised learning shows promise in harnessing extensive unlabeled data, but it also confronts significant privacy concerns, especially in vision. In this paper, we aim to perform membership inference on visual self-supervised models in a more realistic setting: self-supervised training method and details are unknown for an adversary when attacking as he usually faces a black-box system in practice. In this setting, considering that self-supervised model could be trained by completely different self-supervised paradigms, e.g., masked image modeling and contrastive learning, with complex training details, we propose a unified membership inference method called PartCrop. It is motivated by the shared part-aware capability among models and stronger part response on the training data. Specifically, PartCrop crops parts of objects in an image to query responses with the image in representation space. We conduct extensive attacks on self-supervised models with different training protocols and structures using three widely used image datasets. The results verify the effectiveness and generalization of PartCrop. Moreover, to defend against PartCrop, we evaluate two common approaches, i.e., early stop and differential privacy, and propose a tailored method called shrinking crop scale range. The defense experiments indicate that all of them are effective. Our code is available at https://github.com/JiePKU/PartCrop
No Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
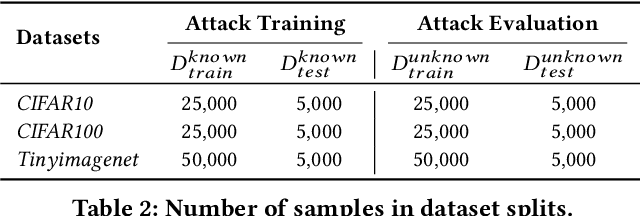
Oct 11, 2023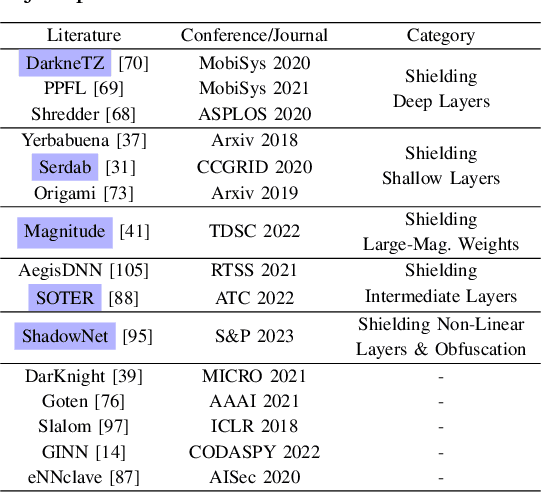
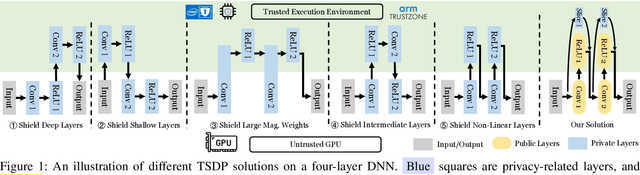
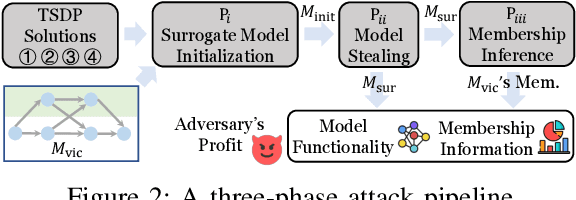
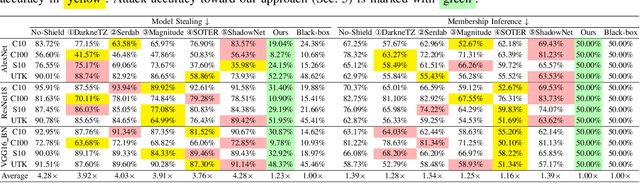
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.