 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
Paper and Code
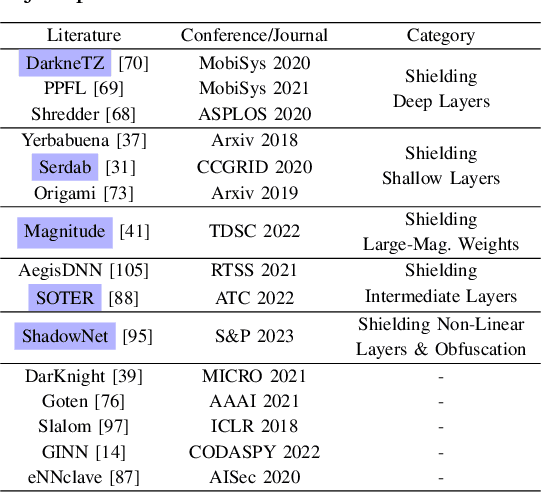
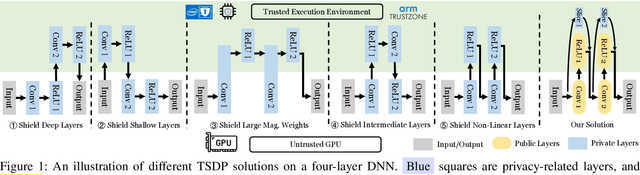
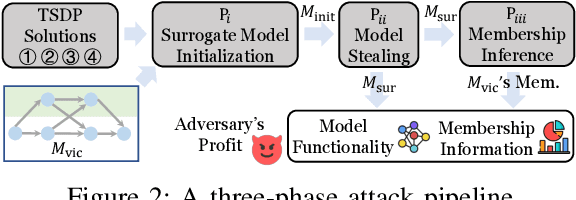
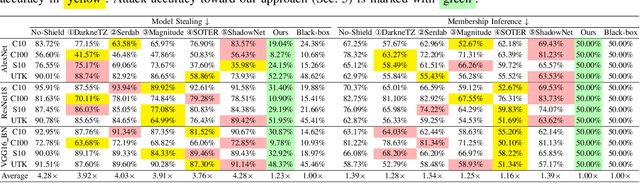
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.