 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnect the Dots: Knowledge Graph-Guided Crawler Attack on Retrieval-Augmented Generation Systems
Jan 22, 2026Retrieval-augmented generation (RAG) systems integrate document retrieval with large language models and have been widely adopted. However, in privacy-related scenarios, RAG introduces a new privacy risk: adversaries can issue carefully crafted queries to exfiltrate sensitive content from the underlying corpus gradually. Although recent studies have demonstrated multi-turn extraction attacks, they rely on heuristics and fail to perform long-term extraction planning. To address these limitations, we formulate the RAG extraction attack as an adaptive stochastic coverage problem (ASCP). In ASCP, each query is treated as a probabilistic action that aims to maximize conditional marginal gain (CMG), enabling principled long-term planning under uncertainty. However, integrating ASCP with practical RAG attack faces three key challenges: unobservable CMG, intractability in the action space, and feasibility constraints. To overcome these challenges, we maintain a global attacker-side state to guide the attack. Building on this idea, we introduce RAGCRAWLER, which builds a knowledge graph to represent revealed information, uses this global state to estimate CMG, and plans queries in semantic space that target unretrieved regions. In comprehensive experiments across diverse RAG architectures and datasets, our proposed method, RAGCRAWLER, consistently outperforms all baselines. It achieves up to 84.4% corpus coverage within a fixed query budget and deliver an average improvement of 20.7% over the top-performing baseline. It also maintains high semantic fidelity and strong content reconstruction accuracy with low attack cost. Crucially, RAGCRAWLER proves its robustness by maintaining effectiveness against advanced RAG systems employing query rewriting and multi-query retrieval strategies. Our work reveals significant security gaps and highlights the pressing need for stronger safeguards for RAG.
Moss: Proxy Model-based Full-Weight Aggregation in Federated Learning with Heterogeneous Models
Mar 13, 2025
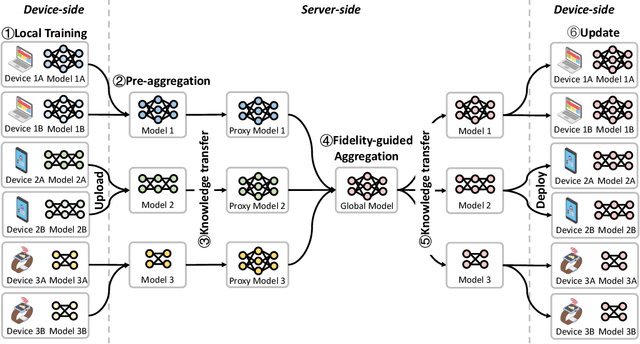

Modern Federated Learning (FL) has become increasingly essential for handling highly heterogeneous mobile devices. Current approaches adopt a partial model aggregation paradigm that leads to sub-optimal model accuracy and higher training overhead. In this paper, we challenge the prevailing notion of partial-model aggregation and propose a novel "full-weight aggregation" method named Moss, which aggregates all weights within heterogeneous models to preserve comprehensive knowledge. Evaluation across various applications demonstrates that Moss significantly accelerates training, reduces on-device training time and energy consumption, enhances accuracy, and minimizes network bandwidth utilization when compared to state-of-the-art baselines.
TEESlice: Protecting Sensitive Neural Network Models in Trusted Execution Environments When Attackers have Pre-Trained Models
Nov 15, 2024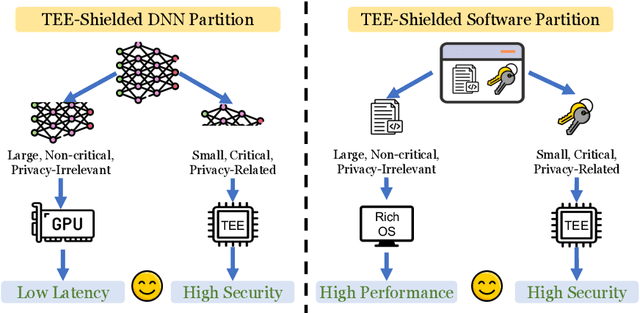
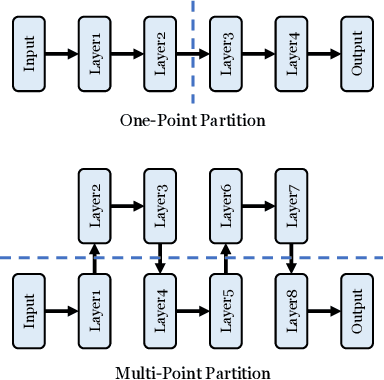
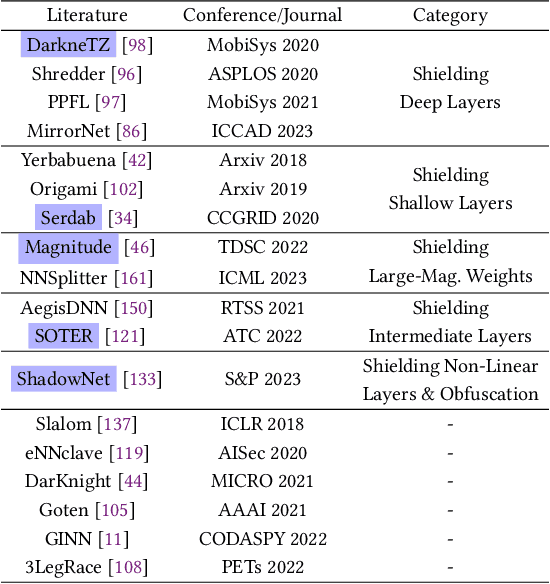
Trusted Execution Environments (TEE) are used to safeguard on-device models. However, directly employing TEEs to secure the entire DNN model is challenging due to the limited computational speed. Utilizing GPU can accelerate DNN's computation speed but commercial widely-available GPUs usually lack security protection. To this end, scholars introduce TSDP, a method that protects privacy-sensitive weights within TEEs and offloads insensitive weights to GPUs. Nevertheless, current methods do not consider the presence of a knowledgeable adversary who can access abundant publicly available pre-trained models and datasets. This paper investigates the security of existing methods against such a knowledgeable adversary and reveals their inability to fulfill their security promises. Consequently, we introduce a novel partition before training strategy, which effectively separates privacy-sensitive weights from other components of the model. Our evaluation demonstrates that our approach can offer full model protection with a computational cost reduced by a factor of 10. In addition to traditional CNN models, we also demonstrate the scalability to large language models. Our approach can compress the private functionalities of the large language model to lightweight slices and achieve the same level of protection as the shielding-whole-model baseline.
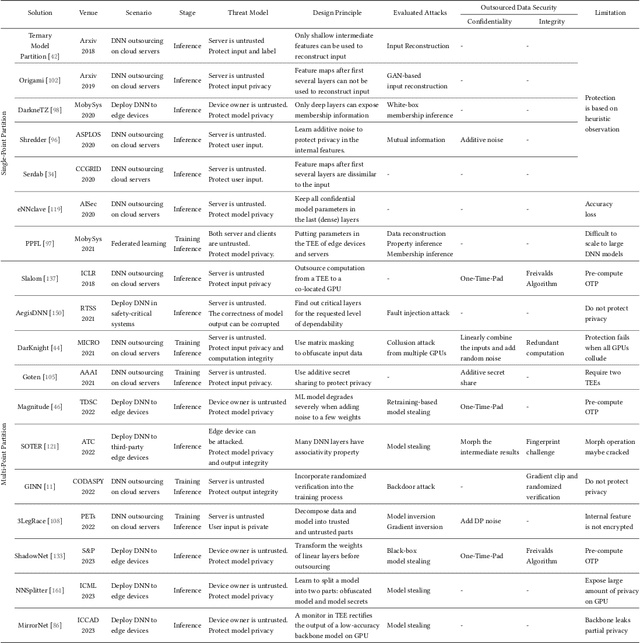
No Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
Oct 11, 2023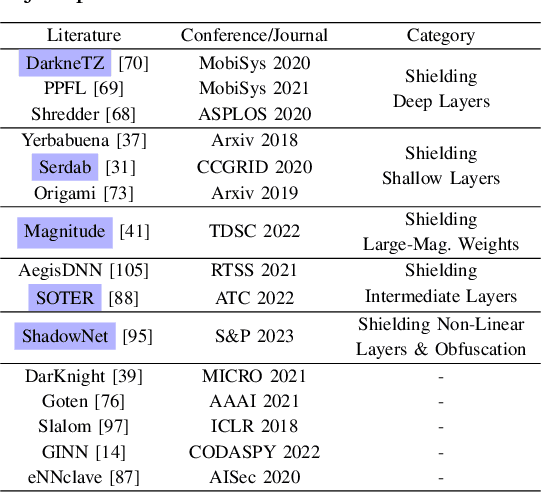
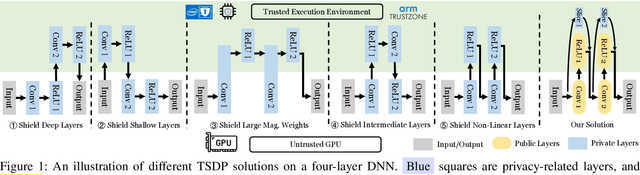
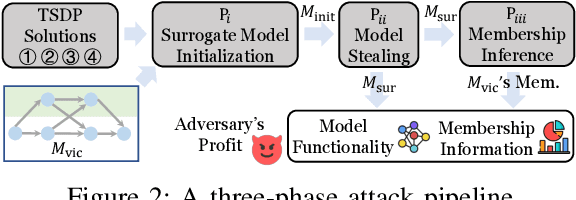
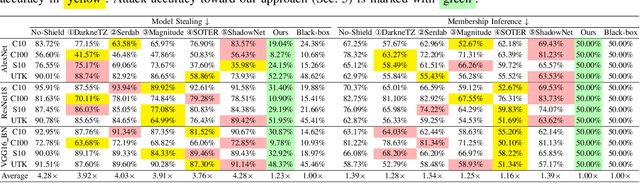
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.
DistFL: Distribution-aware Federated Learning for Mobile Scenarios
Oct 22, 2021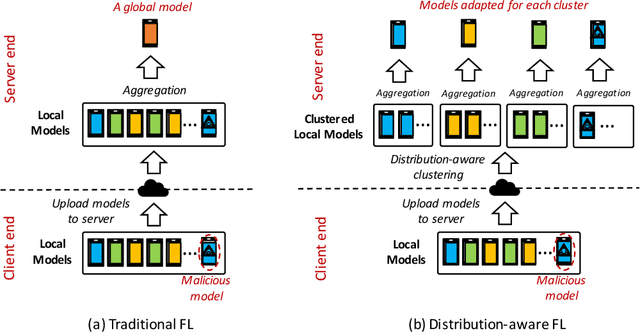
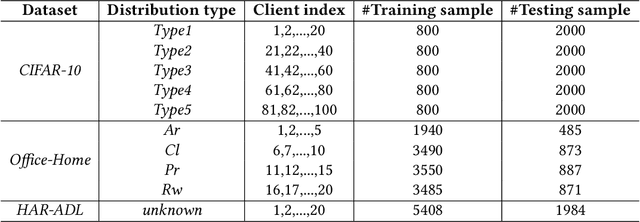
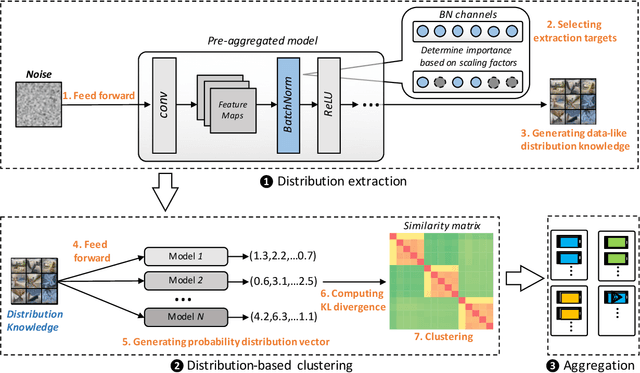
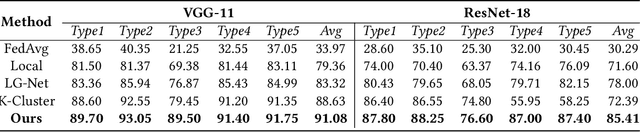
Federated learning (FL) has emerged as an effective solution to decentralized and privacy-preserving machine learning for mobile clients. While traditional FL has demonstrated its superiority, it ignores the non-iid (independently identically distributed) situation, which widely exists in mobile scenarios. Failing to handle non-iid situations could cause problems such as performance decreasing and possible attacks. Previous studies focus on the "symptoms" directly, as they try to improve the accuracy or detect possible attacks by adding extra steps to conventional FL models. However, previous techniques overlook the root causes for the "symptoms": blindly aggregating models with the non-iid distributions. In this paper, we try to fundamentally address the issue by decomposing the overall non-iid situation into several iid clusters and conducting aggregation in each cluster. Specifically, we propose \textbf{DistFL}, a novel framework to achieve automated and accurate \textbf{Dist}ribution-aware \textbf{F}ederated \textbf{L}earning in a cost-efficient way. DistFL achieves clustering via extracting and comparing the \textit{distribution knowledge} from the uploaded models. With this framework, we are able to generate multiple personalized models with distinctive distributions and assign them to the corresponding clients. Extensive experiments on mobile scenarios with popular model architectures have demonstrated the effectiveness of DistFL.
PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
Mar 08, 2021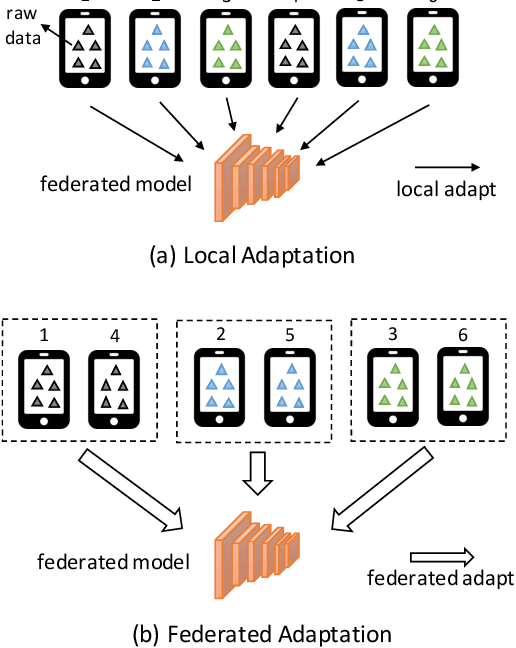

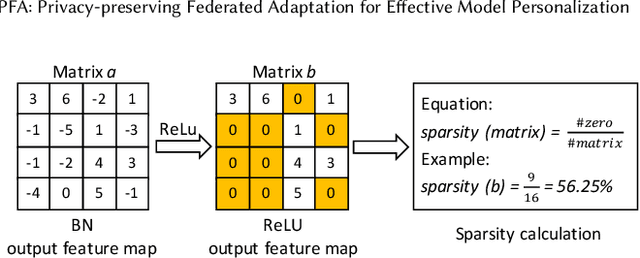
Federated learning (FL) has become a prevalent distributed machine learning paradigm with improved privacy. After learning, the resulting federated model should be further personalized to each different client. While several methods have been proposed to achieve personalization, they are typically limited to a single local device, which may incur bias or overfitting since data in a single device is extremely limited. In this paper, we attempt to realize personalization beyond a single client. The motivation is that during FL, there may exist many clients with similar data distribution, and thus the personalization performance could be significantly boosted if these similar clients can cooperate with each other. Inspired by this, this paper introduces a new concept called federated adaptation, targeting at adapting the trained model in a federated manner to achieve better personalization results. However, the key challenge for federated adaptation is that we could not outsource any raw data from the client during adaptation, due to privacy concerns. In this paper, we propose PFA, a framework to accomplish Privacy-preserving Federated Adaptation. PFA leverages the sparsity property of neural networks to generate privacy-preserving representations and uses them to efficiently identify clients with similar data distributions. Based on the grouping results, PFA conducts an FL process in a group-wise way on the federated model to accomplish the adaptation. For evaluation, we manually construct several practical FL datasets based on public datasets in order to simulate both the class-imbalance and background-difference conditions. Extensive experiments on these datasets and popular model architectures demonstrate the effectiveness of PFA, outperforming other state-of-the-art methods by a large margin while ensuring user privacy. We will release our code at: https://github.com/lebyni/PFA.
TransTailor: Pruning the Pre-trained Model for Improved Transfer Learning
Mar 02, 2021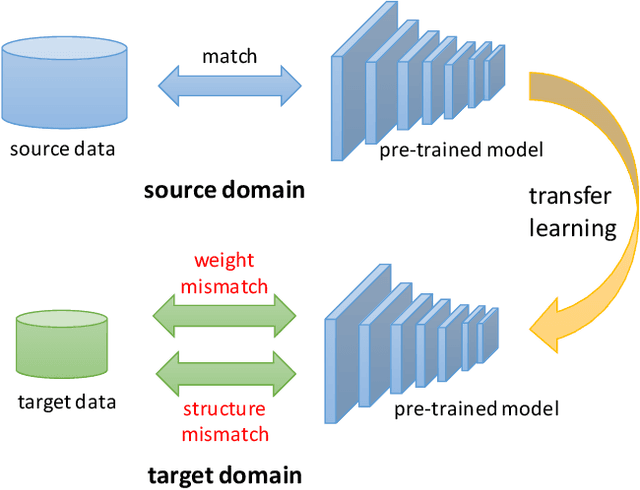
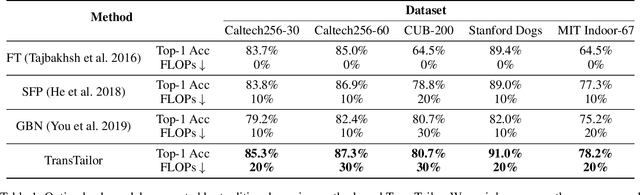
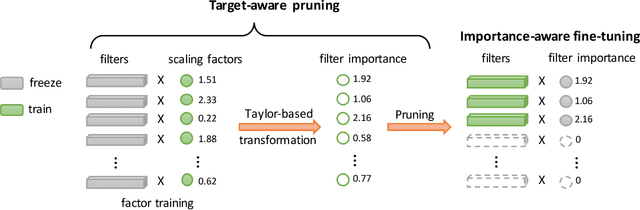
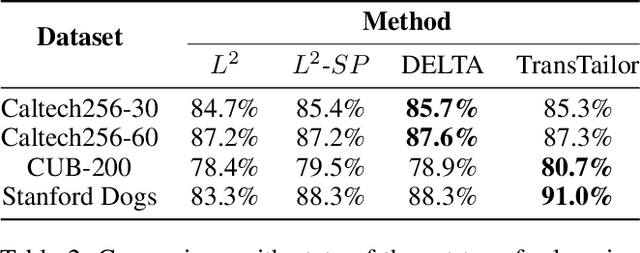
The increasing of pre-trained models has significantly facilitated the performance on limited data tasks with transfer learning. However, progress on transfer learning mainly focuses on optimizing the weights of pre-trained models, which ignores the structure mismatch between the model and the target task. This paper aims to improve the transfer performance from another angle - in addition to tuning the weights, we tune the structure of pre-trained models, in order to better match the target task. To this end, we propose TransTailor, targeting at pruning the pre-trained model for improved transfer learning. Different from traditional pruning pipelines, we prune and fine-tune the pre-trained model according to the target-aware weight importance, generating an optimal sub-model tailored for a specific target task. In this way, we transfer a more suitable sub-structure that can be applied during fine-tuning to benefit the final performance. Extensive experiments on multiple pre-trained models and datasets demonstrate that TransTailor outperforms the traditional pruning methods and achieves competitive or even better performance than other state-of-the-art transfer learning methods while using a smaller model. Notably, on the Stanford Dogs dataset, TransTailor can achieve 2.7% accuracy improvement over other transfer methods with 20% fewer FLOPs.
S3ML: A Secure Serving System for Machine Learning Inference
Oct 13, 2020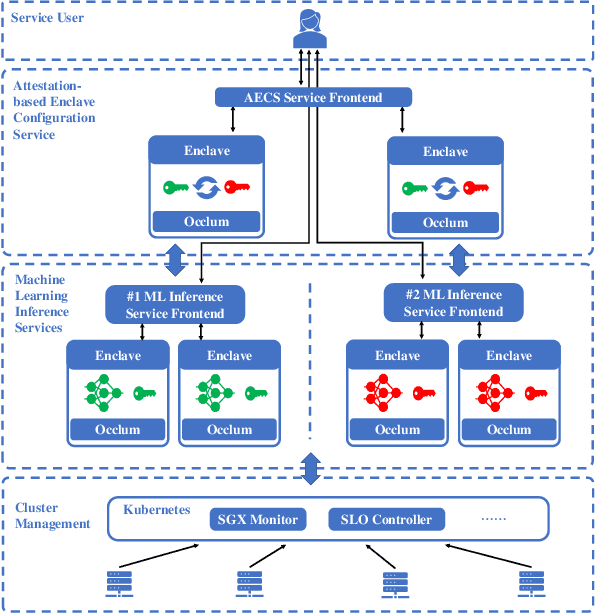
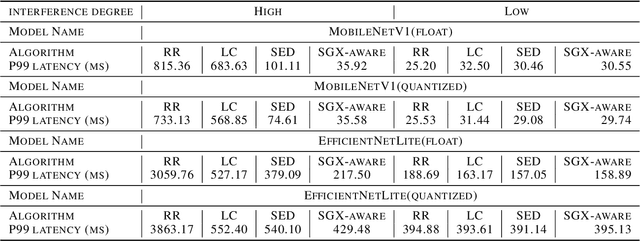
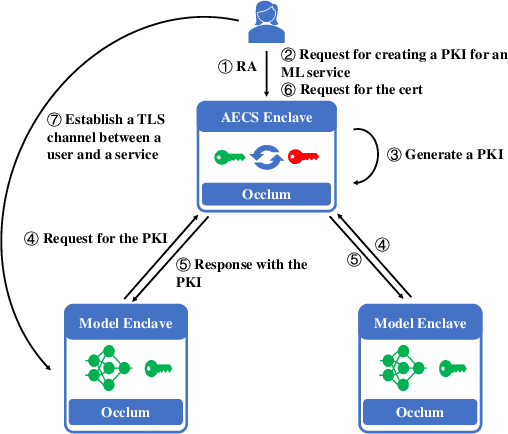
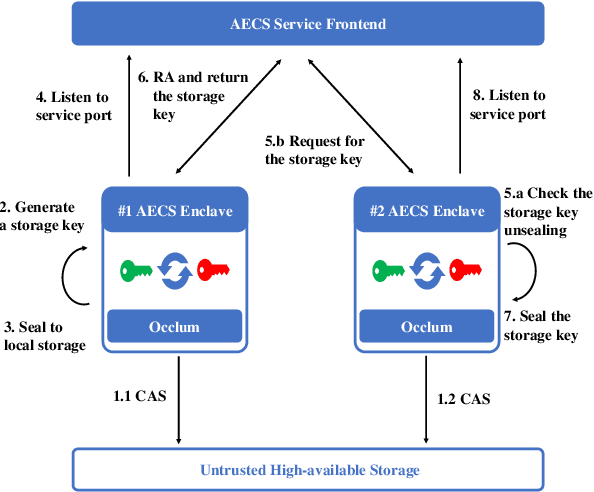
We present S3ML, a secure serving system for machine learning inference in this paper. S3ML runs machine learning models in Intel SGX enclaves to protect users' privacy. S3ML designs a secure key management service to construct flexible privacy-preserving server clusters and proposes novel SGX-aware load balancing and scaling methods to satisfy users' Service-Level Objectives. We have implemented S3ML based on Kubernetes as a low-overhead, high-available, and scalable system. We demonstrate the system performance and effectiveness of S3ML through extensive experiments on a series of widely-used models.
Adversarial Attacks on Monocular Depth Estimation
Mar 23, 2020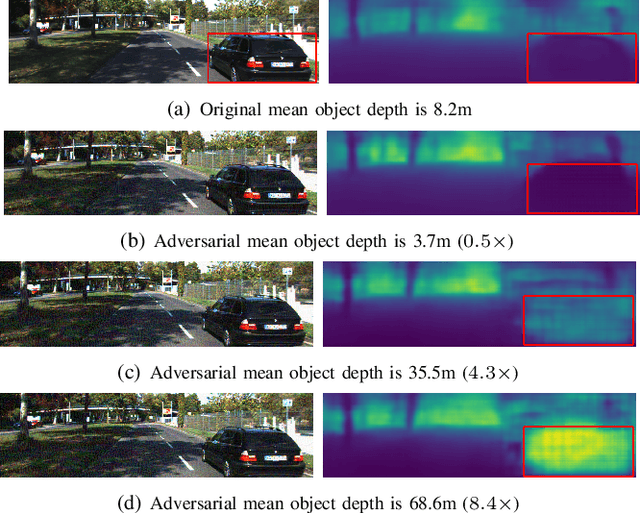

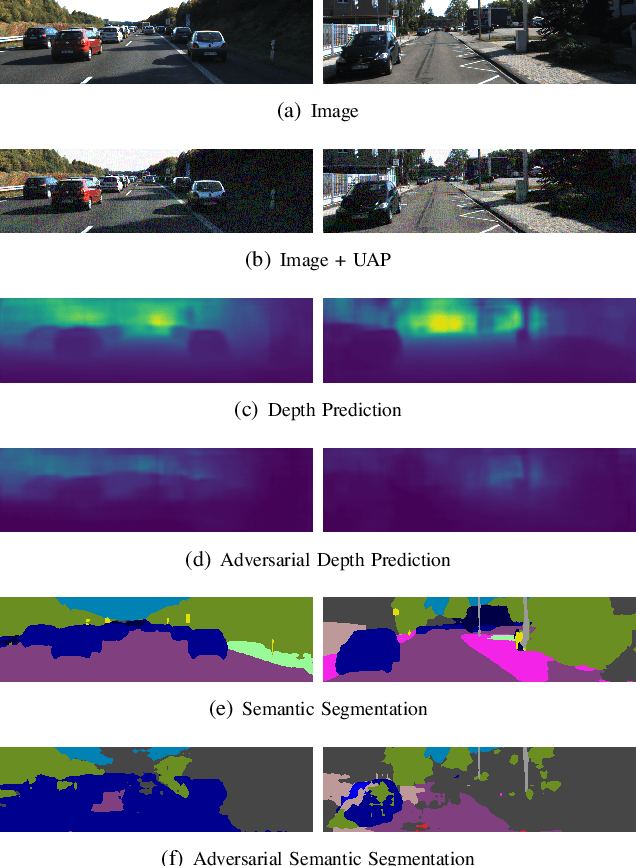
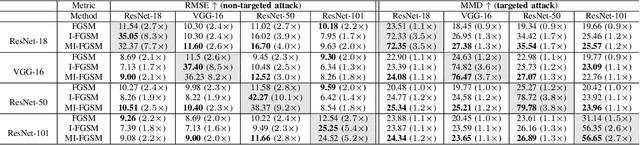
Recent advances of deep learning have brought exceptional performance on many computer vision tasks such as semantic segmentation and depth estimation. However, the vulnerability of deep neural networks towards adversarial examples have caused grave concerns for real-world deployment. In this paper, we present to the best of our knowledge the first systematic study of adversarial attacks on monocular depth estimation, an important task of 3D scene understanding in scenarios such as autonomous driving and robot navigation. In order to understand the impact of adversarial attacks on depth estimation, we first define a taxonomy of different attack scenarios for depth estimation, including non-targeted attacks, targeted attacks and universal attacks. We then adapt several state-of-the-art attack methods for classification on the field of depth estimation. Besides, multi-task attacks are introduced to further improve the attack performance for universal attacks. Experimental results show that it is possible to generate significant errors on depth estimation. In particular, we demonstrate that our methods can conduct targeted attacks on given objects (such as a car), resulting in depth estimation 3-4x away from the ground truth (e.g., from 20m to 80m).
Traffic Danger Recognition With Surveillance Cameras Without Training Data
Nov 29, 2018
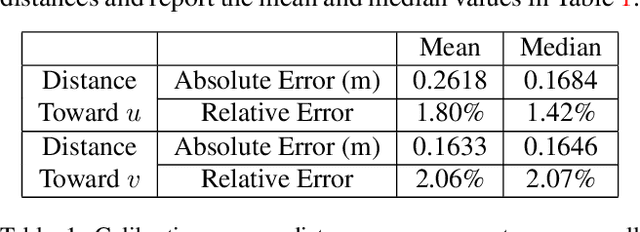

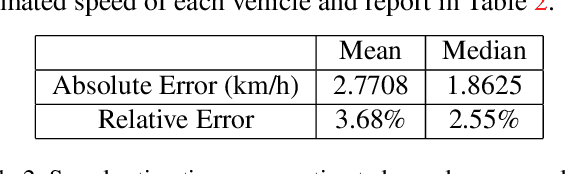
We propose a traffic danger recognition model that works with arbitrary traffic surveillance cameras to identify and predict car crashes. There are too many cameras to monitor manually. Therefore, we developed a model to predict and identify car crashes from surveillance cameras based on a 3D reconstruction of the road plane and prediction of trajectories. For normal traffic, it supports real-time proactive safety checks of speeds and distances between vehicles to provide insights about possible high-risk areas. We achieve good prediction and recognition of car crashes without using any labeled training data of crashes. Experiments on the BrnoCompSpeed dataset show that our model can accurately monitor the road, with mean errors of 1.80% for distance measurement, 2.77 km/h for speed measurement, 0.24 m for car position prediction, and 2.53 km/h for speed prediction.