 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
Paper and Code
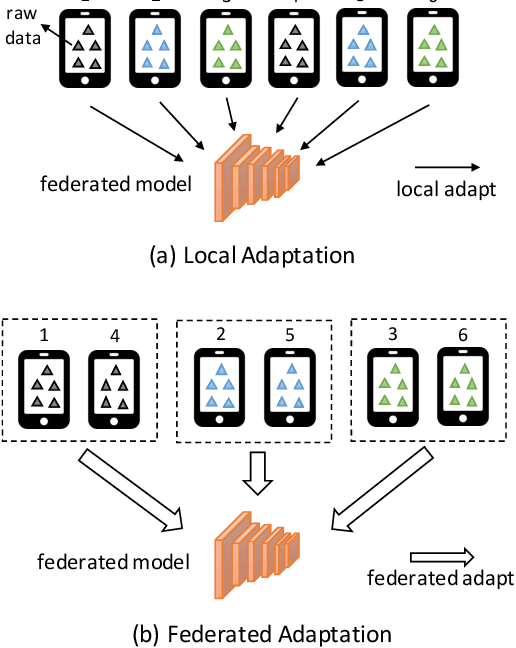

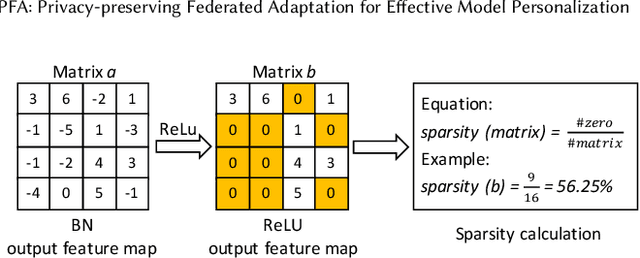
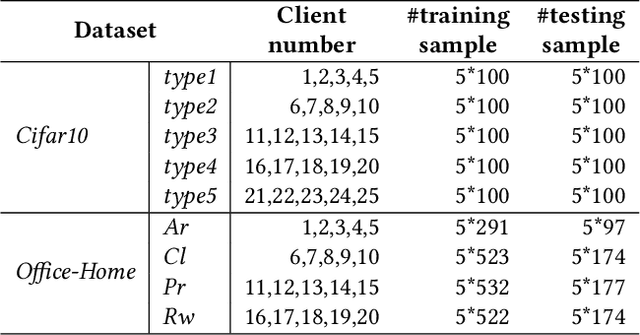
Federated learning (FL) has become a prevalent distributed machine learning paradigm with improved privacy. After learning, the resulting federated model should be further personalized to each different client. While several methods have been proposed to achieve personalization, they are typically limited to a single local device, which may incur bias or overfitting since data in a single device is extremely limited. In this paper, we attempt to realize personalization beyond a single client. The motivation is that during FL, there may exist many clients with similar data distribution, and thus the personalization performance could be significantly boosted if these similar clients can cooperate with each other. Inspired by this, this paper introduces a new concept called federated adaptation, targeting at adapting the trained model in a federated manner to achieve better personalization results. However, the key challenge for federated adaptation is that we could not outsource any raw data from the client during adaptation, due to privacy concerns. In this paper, we propose PFA, a framework to accomplish Privacy-preserving Federated Adaptation. PFA leverages the sparsity property of neural networks to generate privacy-preserving representations and uses them to efficiently identify clients with similar data distributions. Based on the grouping results, PFA conducts an FL process in a group-wise way on the federated model to accomplish the adaptation. For evaluation, we manually construct several practical FL datasets based on public datasets in order to simulate both the class-imbalance and background-difference conditions. Extensive experiments on these datasets and popular model architectures demonstrate the effectiveness of PFA, outperforming other state-of-the-art methods by a large margin while ensuring user privacy. We will release our code at: https://github.com/lebyni/PFA.