 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnect the Dots: Knowledge Graph-Guided Crawler Attack on Retrieval-Augmented Generation Systems
Jan 22, 2026Retrieval-augmented generation (RAG) systems integrate document retrieval with large language models and have been widely adopted. However, in privacy-related scenarios, RAG introduces a new privacy risk: adversaries can issue carefully crafted queries to exfiltrate sensitive content from the underlying corpus gradually. Although recent studies have demonstrated multi-turn extraction attacks, they rely on heuristics and fail to perform long-term extraction planning. To address these limitations, we formulate the RAG extraction attack as an adaptive stochastic coverage problem (ASCP). In ASCP, each query is treated as a probabilistic action that aims to maximize conditional marginal gain (CMG), enabling principled long-term planning under uncertainty. However, integrating ASCP with practical RAG attack faces three key challenges: unobservable CMG, intractability in the action space, and feasibility constraints. To overcome these challenges, we maintain a global attacker-side state to guide the attack. Building on this idea, we introduce RAGCRAWLER, which builds a knowledge graph to represent revealed information, uses this global state to estimate CMG, and plans queries in semantic space that target unretrieved regions. In comprehensive experiments across diverse RAG architectures and datasets, our proposed method, RAGCRAWLER, consistently outperforms all baselines. It achieves up to 84.4% corpus coverage within a fixed query budget and deliver an average improvement of 20.7% over the top-performing baseline. It also maintains high semantic fidelity and strong content reconstruction accuracy with low attack cost. Crucially, RAGCRAWLER proves its robustness by maintaining effectiveness against advanced RAG systems employing query rewriting and multi-query retrieval strategies. Our work reveals significant security gaps and highlights the pressing need for stronger safeguards for RAG.
Research on the Proximity Relationships of Psychosomatic Disease Knowledge Graph Modules Extracted by Large Language Models
Dec 24, 2024As social changes accelerate, the incidence of psychosomatic disorders has significantly increased, becoming a major challenge in global health issues. This necessitates an innovative knowledge system and analytical methods to aid in diagnosis and treatment. Here, we establish the ontology model and entity types, using the BERT model and LoRA-tuned LLM for named entity recognition, constructing the knowledge graph with 9668 triples. Next, by analyzing the network distances between disease, symptom, and drug modules, it was found that closer network distances among diseases can predict greater similarities in their clinical manifestations, treatment approaches, and psychological mechanisms, and closer distances between symptoms indicate that they are more likely to co-occur. Lastly, by comparing the proximity d and proximity z score, it was shown that symptom-disease pairs in primary diagnostic relationships have a stronger association and are of higher referential value than those in diagnostic relationships. The research results revealed the potential connections between diseases, co-occurring symptoms, and similarities in treatment strategies, providing new perspectives for the diagnosis and treatment of psychosomatic disorders and valuable information for future mental health research and practice.
TEESlice: Protecting Sensitive Neural Network Models in Trusted Execution Environments When Attackers have Pre-Trained Models
Nov 15, 2024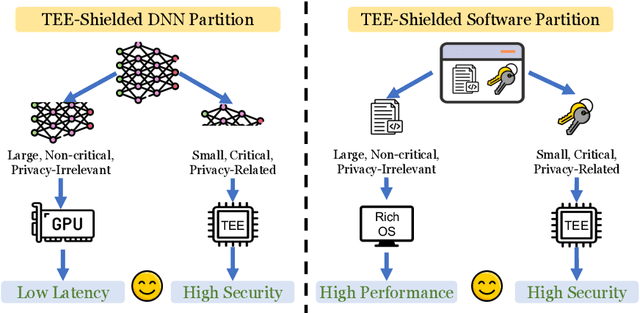
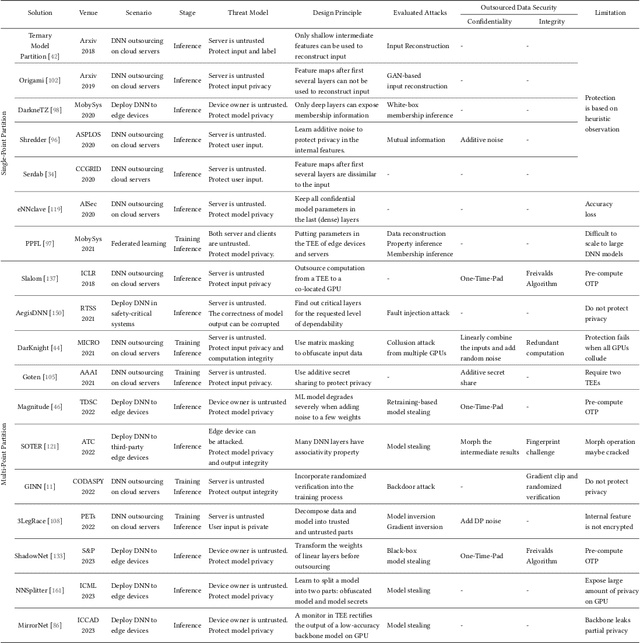
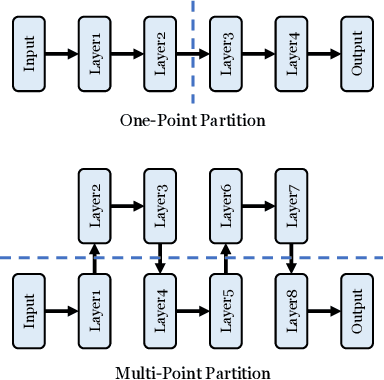
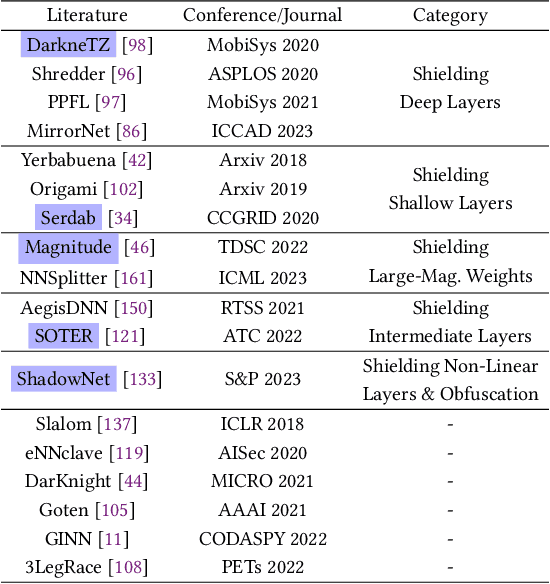
Trusted Execution Environments (TEE) are used to safeguard on-device models. However, directly employing TEEs to secure the entire DNN model is challenging due to the limited computational speed. Utilizing GPU can accelerate DNN's computation speed but commercial widely-available GPUs usually lack security protection. To this end, scholars introduce TSDP, a method that protects privacy-sensitive weights within TEEs and offloads insensitive weights to GPUs. Nevertheless, current methods do not consider the presence of a knowledgeable adversary who can access abundant publicly available pre-trained models and datasets. This paper investigates the security of existing methods against such a knowledgeable adversary and reveals their inability to fulfill their security promises. Consequently, we introduce a novel partition before training strategy, which effectively separates privacy-sensitive weights from other components of the model. Our evaluation demonstrates that our approach can offer full model protection with a computational cost reduced by a factor of 10. In addition to traditional CNN models, we also demonstrate the scalability to large language models. Our approach can compress the private functionalities of the large language model to lightweight slices and achieve the same level of protection as the shielding-whole-model baseline.