 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-PINNs: Regulating Feature Distributions in Physics-Informed Neural Networks
May 09, 2025Physics-Informed Neural Networks (PINNs) are a class of deep learning models designed to solve partial differential equations by incorporating physical laws directly into the loss function. However, the internal covariate shift, which has been largely overlooked, hinders the effective utilization of neural network capacity in PINNs. To this end, we propose Mask-PINNs, a novel architecture designed to address this issue in PINNs. Unlike traditional normalization methods such as BatchNorm or LayerNorm, we introduce a learnable, nonlinear mask function that constrains the feature distributions without violating underlying physics. The experimental results show that the proposed method significantly improves feature distribution stability, accuracy, and robustness across various activation functions and PDE benchmarks. Furthermore, it enables the stable and efficient training of wider networks a capability that has been largely overlooked in PINNs.
Research on the Proximity Relationships of Psychosomatic Disease Knowledge Graph Modules Extracted by Large Language Models
Dec 24, 2024As social changes accelerate, the incidence of psychosomatic disorders has significantly increased, becoming a major challenge in global health issues. This necessitates an innovative knowledge system and analytical methods to aid in diagnosis and treatment. Here, we establish the ontology model and entity types, using the BERT model and LoRA-tuned LLM for named entity recognition, constructing the knowledge graph with 9668 triples. Next, by analyzing the network distances between disease, symptom, and drug modules, it was found that closer network distances among diseases can predict greater similarities in their clinical manifestations, treatment approaches, and psychological mechanisms, and closer distances between symptoms indicate that they are more likely to co-occur. Lastly, by comparing the proximity d and proximity z score, it was shown that symptom-disease pairs in primary diagnostic relationships have a stronger association and are of higher referential value than those in diagnostic relationships. The research results revealed the potential connections between diseases, co-occurring symptoms, and similarities in treatment strategies, providing new perspectives for the diagnosis and treatment of psychosomatic disorders and valuable information for future mental health research and practice.
LLaVA-MR: Large Language-and-Vision Assistant for Video Moment Retrieval
Nov 21, 2024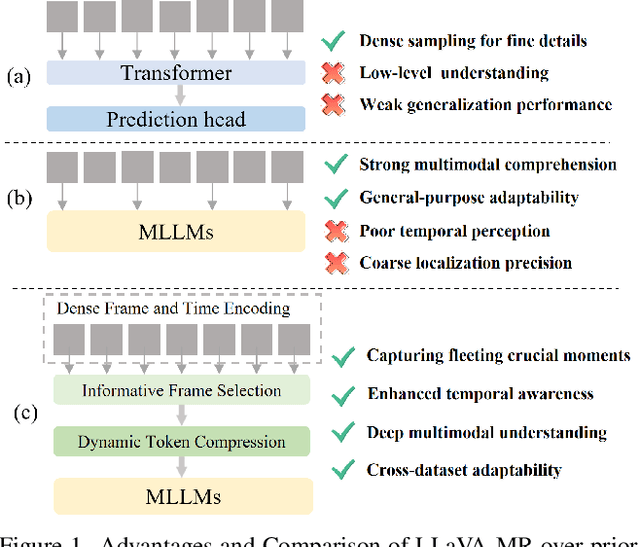
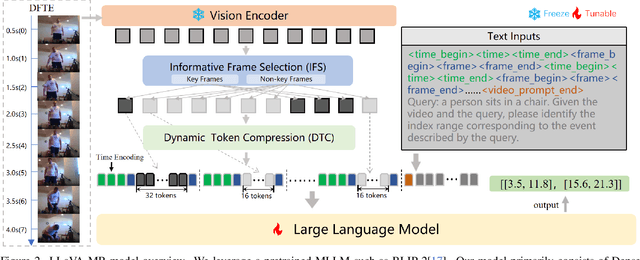
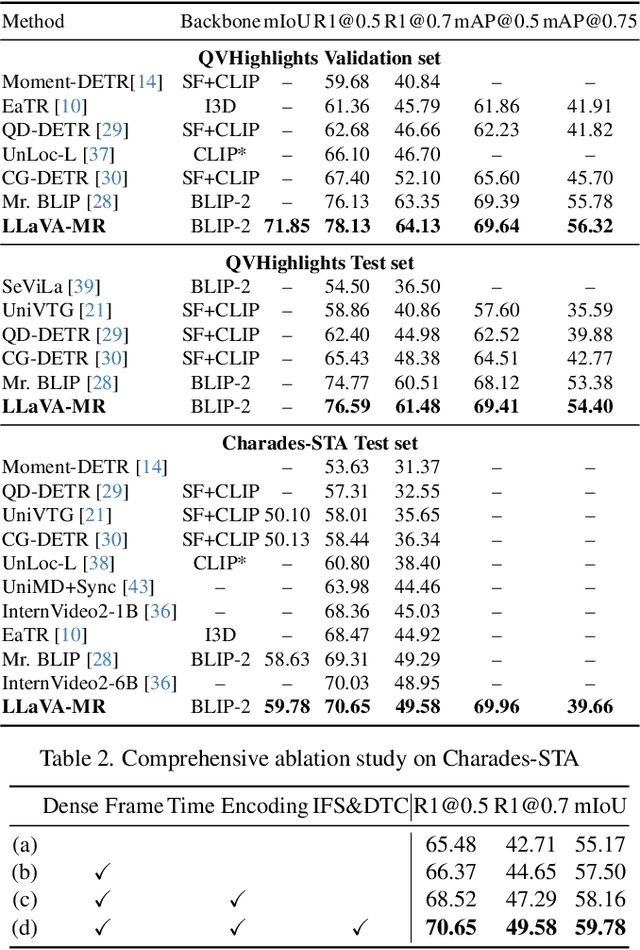
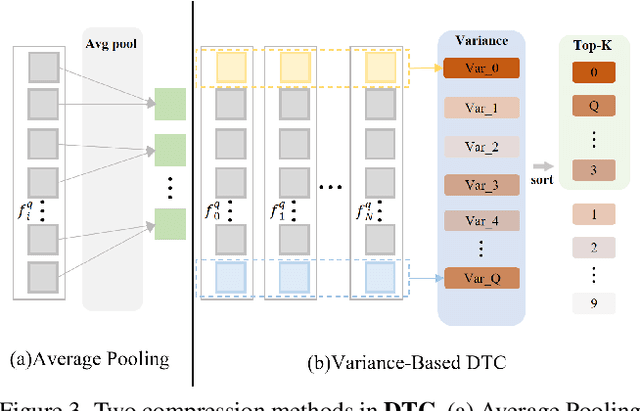
Multimodal Large Language Models (MLLMs) are widely used for visual perception, understanding, and reasoning. However, long video processing and precise moment retrieval remain challenging due to LLMs' limited context size and coarse frame extraction. We propose the Large Language-and-Vision Assistant for Moment Retrieval (LLaVA-MR), which enables accurate moment retrieval and contextual grounding in videos using MLLMs. LLaVA-MR combines Dense Frame and Time Encoding (DFTE) for spatial-temporal feature extraction, Informative Frame Selection (IFS) for capturing brief visual and motion patterns, and Dynamic Token Compression (DTC) to manage LLM context limitations. Evaluations on benchmarks like Charades-STA and QVHighlights demonstrate that LLaVA-MR outperforms 11 state-of-the-art methods, achieving an improvement of 1.82% in R1@0.5 and 1.29% in mAP@0.5 on the QVHighlights dataset. Our implementation will be open-sourced upon acceptance.
Element-wise Multiplication Based Physics-informed Neural Networks
Jun 06, 2024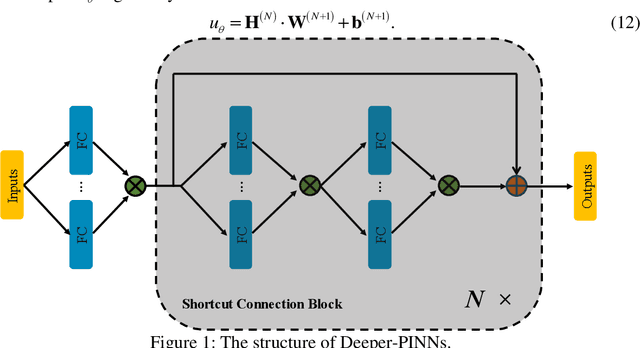
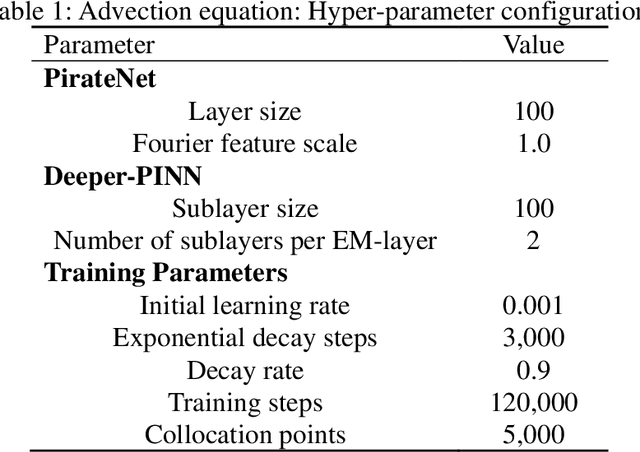
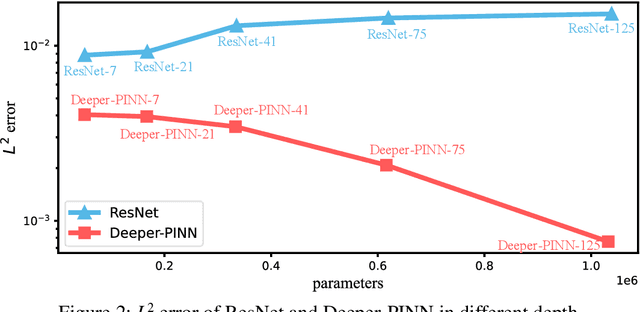
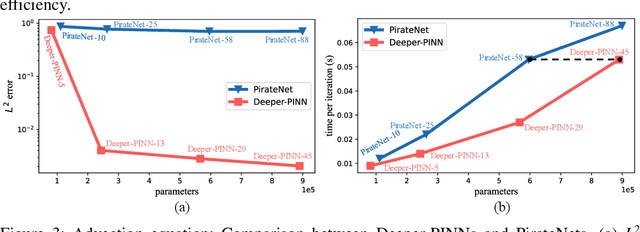
As a promising framework for resolving partial differential equations (PDEs), physics-informed neural networks (PINNs) have received widespread attention from industrial and scientific fields. However, lack of expressive ability and initialization pathology issues are found to prevent the application of PINNs in complex PDEs. In this work, we propose Element-wise Multiplication Based Physics-informed Neural Networks (EM-PINNs) to resolve these issues. The element-wise multiplication operation is adopted to transform features into high-dimensional, non-linear spaces, which effectively enhance the expressive capability of PINNs. Benefiting from element-wise multiplication operation, EM-PINNs can eliminate the initialization pathologies of PINNs. The proposed structure is verified on various benchmarks. The results show that EM-PINNs have strong expressive ability.
Spatio-temporal Attention-based Hidden Physics-informed Neural Network for Remaining Useful Life Prediction
May 20, 2024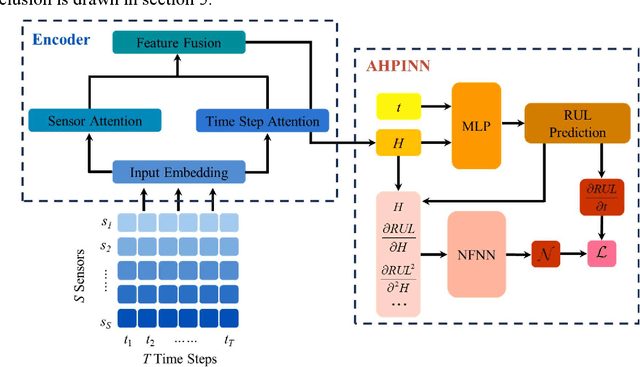

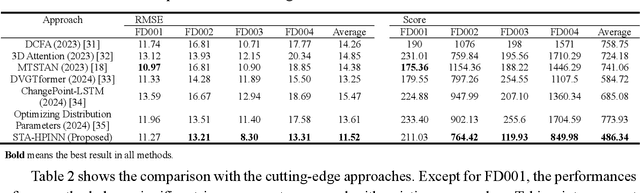
Predicting the Remaining Useful Life (RUL) is essential in Prognostic Health Management (PHM) for industrial systems. Although deep learning approaches have achieved considerable success in predicting RUL, challenges such as low prediction accuracy and interpretability pose significant challenges, hindering their practical implementation. In this work, we introduce a Spatio-temporal Attention-based Hidden Physics-informed Neural Network (STA-HPINN) for RUL prediction, which can utilize the associated physics of the system degradation. The spatio-temporal attention mechanism can extract important features from the input data. With the self-attention mechanism on both the sensor dimension and time step dimension, the proposed model can effectively extract degradation information. The hidden physics-informed neural network is utilized to capture the physics mechanisms that govern the evolution of RUL. With the constraint of physics, the model can achieve higher accuracy and reasonable predictions. The approach is validated on a benchmark dataset, demonstrating exceptional performance when compared to cutting-edge methods, especially in the case of complex conditions.
Densely Multiplied Physics Informed Neural Networks
Feb 12, 2024

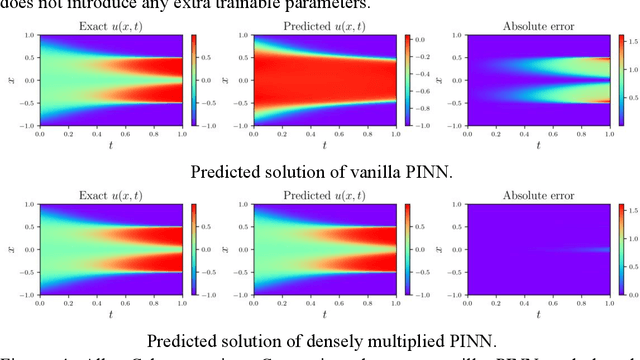

Although physics-informed neural networks (PINNs) have shown great potential in dealing with nonlinear partial differential equations (PDEs), it is common that PINNs will suffer from the problem of insufficient precision or obtaining incorrect outcomes. Unlike most of the existing solutions trying to enhance the ability of PINN by optimizing the training process, this paper improved the neural network architecture to improve the performance of PINN. We propose a densely multiply PINN (DM-PINN) architecture, which multiplies the output of a hidden layer with the outputs of all the behind hidden layers. Without introducing more trainable parameters, this effective mechanism can significantly improve the accuracy of PINNs. The proposed architecture is evaluated on four benchmark examples (Allan-Cahn equation, Helmholtz equation, Burgers equation and 1D convection equation). Comparisons between the proposed architecture and different PINN structures demonstrate the superior performance of the DM-PINN in both accuracy and efficiency.
Schizophrenia detection based on EEG using Recurrent Auto-Encoder framework
Jul 09, 2022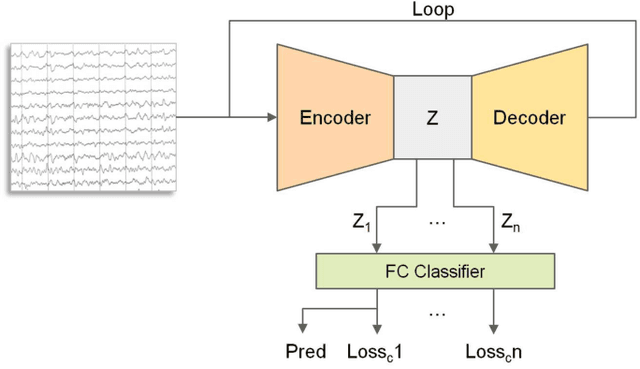
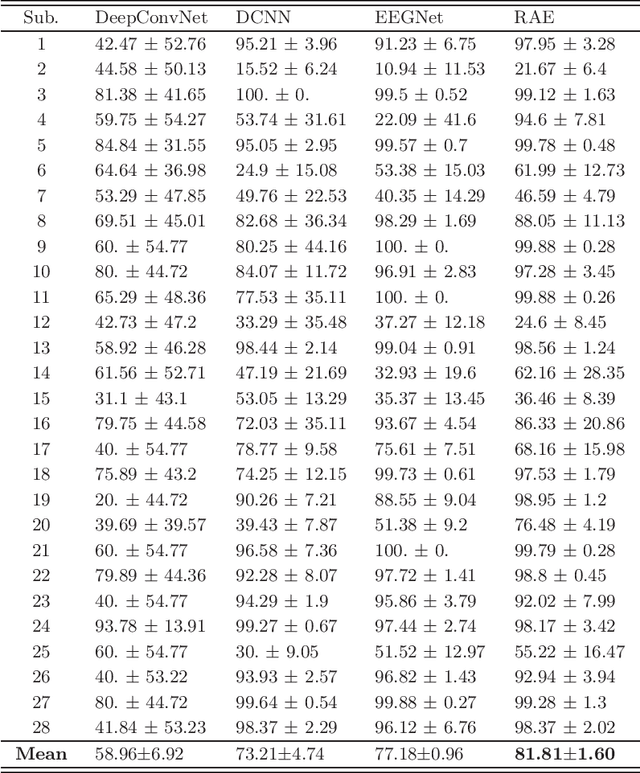
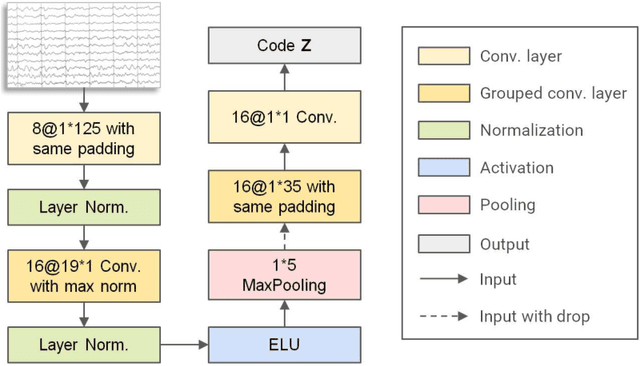
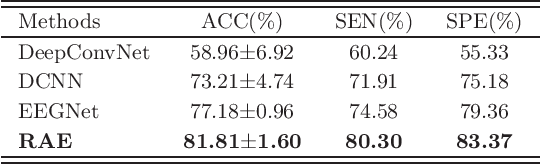
Schizophrenia (SZ) is a serious mental disorder that could seriously affect the patient's quality of life. In recent years, detection of SZ based on deep learning (DL) using electroencephalogram (EEG) has received increasing attention. In this paper, we proposed an end-to-end recurrent auto-encoder (RAE) model to detect SZ. In the RAE model, the raw data was input into one auto-encoder block, and the reconstructed data were recurrently input into the same block. The extracted code by auto-encoder block was simultaneously served as an input of a classifier block to discriminate SZ patients from healthy controls (HC). Evaluated on the dataset containing 14 SZ patients and 14 HC subjects, and the proposed method achieved an average classification accuracy of 81.81% in subject-independent experiment scenario. This study demonstrated that the structure of RAE is able to capture the differential features between SZ patients and HC subjects.
Defocus Blur Detection via Salient Region Detection Prior
Nov 19, 2020
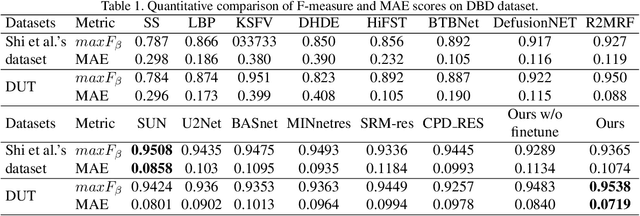


Defocus blur always occurred in photos when people take photos by Digital Single Lens Reflex Camera(DSLR), giving salient region and aesthetic pleasure. Defocus blur Detection aims to separate the out-of-focus and depth-of-field areas in photos, which is an important work in computer vision. Current works for defocus blur detection mainly focus on the designing of networks, the optimizing of the loss function, and the application of multi-stream strategy, meanwhile, these works do not pay attention to the shortage of training data. In this work, to address the above data-shortage problem, we turn to rethink the relationship between two tasks: defocus blur detection and salient region detection. In an image with bokeh effect, it is obvious that the salient region and the depth-of-field area overlap in most cases. So we first train our network on the salient region detection tasks, then transfer the pre-trained model to the defocus blur detection tasks. Besides, we propose a novel network for defocus blur detection. Experiments show that our transfer strategy works well on many current models, and demonstrate the superiority of our network.
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
Apr 22, 2019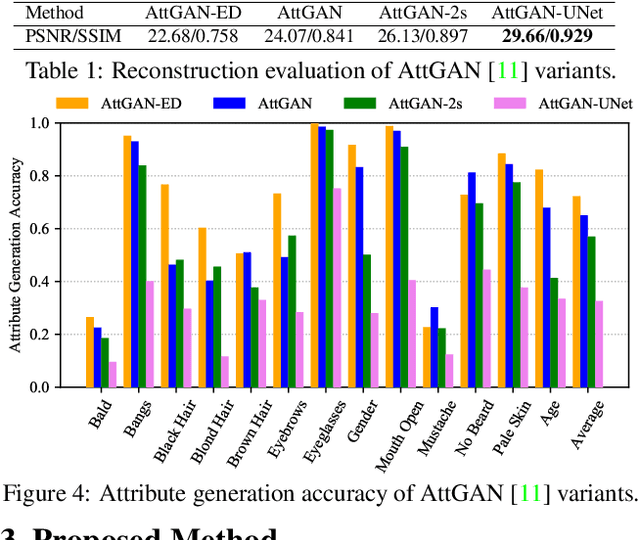



Arbitrary attribute editing generally can be tackled by incorporating encoder-decoder and generative adversarial networks. However, the bottleneck layer in encoder-decoder usually gives rise to blurry and low quality editing result. And adding skip connections improves image quality at the cost of weakened attribute manipulation ability. Moreover, existing methods exploit target attribute vector to guide the flexible translation to desired target domain. In this work, we suggest to address these issues from selective transfer perspective. Considering that specific editing task is certainly only related to the changed attributes instead of all target attributes, our model selectively takes the difference between target and source attribute vectors as input. Furthermore, selective transfer units are incorporated with encoder-decoder to adaptively select and modify encoder feature for enhanced attribute editing. Experiments show that our method (i.e., STGAN) simultaneously improves attribute manipulation accuracy as well as perception quality, and performs favorably against state-of-the-arts in arbitrary facial attribute editing and season translation.