 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Generative Details: Direct Localized Detail Preference Optimization for Video Diffusion Models
Jan 08, 2026Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
OAPT: Offset-Aware Partition Transformer for Double JPEG Artifacts Removal
Aug 21, 2024



Deep learning-based methods have shown remarkable performance in single JPEG artifacts removal task. However, existing methods tend to degrade on double JPEG images, which are prevalent in real-world scenarios. To address this issue, we propose Offset-Aware Partition Transformer for double JPEG artifacts removal, termed as OAPT. We conduct an analysis of double JPEG compression that results in up to four patterns within each 8x8 block and design our model to cluster the similar patterns to remedy the difficulty of restoration. Our OAPT consists of two components: compression offset predictor and image reconstructor. Specifically, the predictor estimates pixel offsets between the first and second compression, which are then utilized to divide different patterns. The reconstructor is mainly based on several Hybrid Partition Attention Blocks (HPAB), combining vanilla window-based self-attention and sparse attention for clustered pattern features. Extensive experiments demonstrate that OAPT outperforms the state-of-the-art method by more than 0.16dB in double JPEG image restoration task. Moreover, without increasing any computation cost, the pattern clustering module in HPAB can serve as a plugin to enhance other transformer-based image restoration methods. The code will be available at https://github.com/QMoQ/OAPT.git .
CPGA: Coding Priors-Guided Aggregation Network for Compressed Video Quality Enhancement
Mar 15, 2024



Recently, numerous approaches have achieved notable success in compressed video quality enhancement (VQE). However, these methods usually ignore the utilization of valuable coding priors inherently embedded in compressed videos, such as motion vectors and residual frames, which carry abundant temporal and spatial information. To remedy this problem, we propose the Coding Priors-Guided Aggregation (CPGA) network to utilize temporal and spatial information from coding priors. The CPGA mainly consists of an inter-frame temporal aggregation (ITA) module and a multi-scale non-local aggregation (MNA) module. Specifically, the ITA module aggregates temporal information from consecutive frames and coding priors, while the MNA module globally captures spatial information guided by residual frames. In addition, to facilitate research in VQE task, we newly construct the Video Coding Priors (VCP) dataset, comprising 300 videos with various coding priors extracted from corresponding bitstreams. It remedies the shortage of previous datasets on the lack of coding information. Experimental results demonstrate the superiority of our method compared to existing state-of-the-art methods. The code and dataset will be released at https://github.com/CPGA/CPGA.git.
Reconstructed Convolution Module Based Look-Up Tables for Efficient Image Super-Resolution
Jul 17, 2023Look-up table(LUT)-based methods have shown the great efficacy in single image super-resolution (SR) task. However, previous methods ignore the essential reason of restricted receptive field (RF) size in LUT, which is caused by the interaction of space and channel features in vanilla convolution. They can only increase the RF at the cost of linearly increasing LUT size. To enlarge RF with contained LUT sizes, we propose a novel Reconstructed Convolution(RC) module, which decouples channel-wise and spatial calculation. It can be formulated as $n^2$ 1D LUTs to maintain $n\times n$ receptive field, which is obviously smaller than $n\times n$D LUT formulated before. The LUT generated by our RC module reaches less than 1/10000 storage compared with SR-LUT baseline. The proposed Reconstructed Convolution module based LUT method, termed as RCLUT, can enlarge the RF size by 9 times than the state-of-the-art LUT-based SR method and achieve superior performance on five popular benchmark dataset. Moreover, the efficient and robust RC module can be used as a plugin to improve other LUT-based SR methods. The code is available at https://github.com/liuguandu/RC-LUT.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
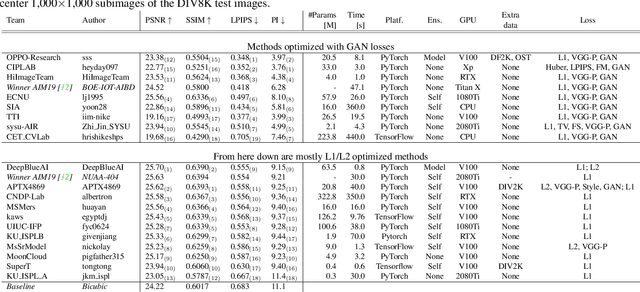

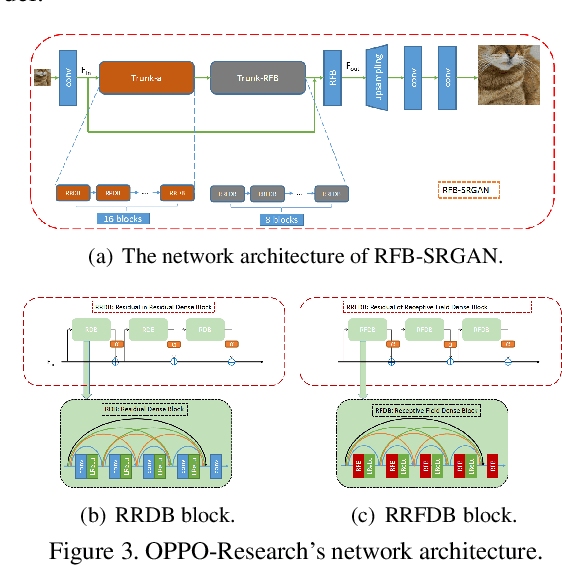
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Dynamic Instance Normalization for Arbitrary Style Transfer
Nov 16, 2019
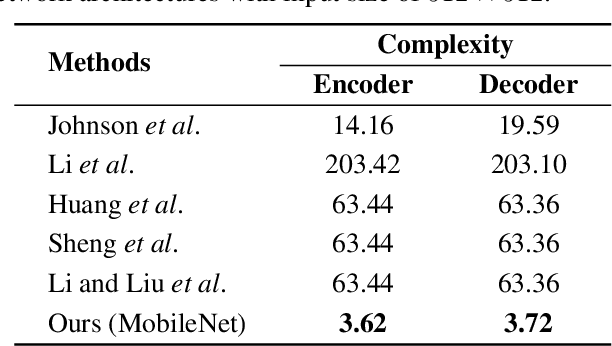

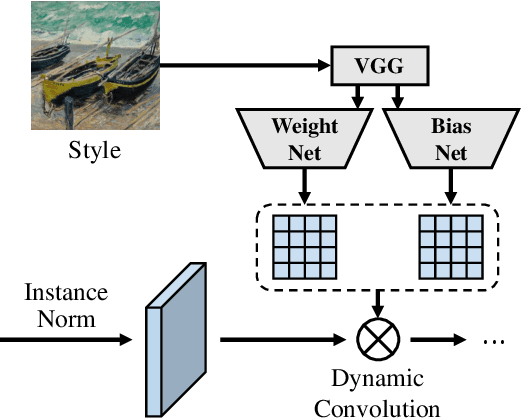
Prior normalization methods rely on affine transformations to produce arbitrary image style transfers, of which the parameters are computed in a pre-defined way. Such manually-defined nature eventually results in the high-cost and shared encoders for both style and content encoding, making style transfer systems cumbersome to be deployed in resource-constrained environments like on the mobile-terminal side. In this paper, we propose a new and generalized normalization module, termed as Dynamic Instance Normalization (DIN), that allows for flexible and more efficient arbitrary style transfers. Comprising an instance normalization and a dynamic convolution, DIN encodes a style image into learnable convolution parameters, upon which the content image is stylized. Unlike conventional methods that use shared complex encoders to encode content and style, the proposed DIN introduces a sophisticated style encoder, yet comes with a compact and lightweight content encoder for fast inference. Experimental results demonstrate that the proposed approach yields very encouraging results on challenging style patterns and, to our best knowledge, for the first time enables an arbitrary style transfer using MobileNet-based lightweight architecture, leading to a reduction factor of more than twenty in computational cost as compared to existing approaches. Furthermore, the proposed DIN provides flexible support for state-of-the-art convolutional operations, and thus triggers novel functionalities, such as uniform-stroke placement for non-natural images and automatic spatial-stroke control.
Adapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution
May 07, 2019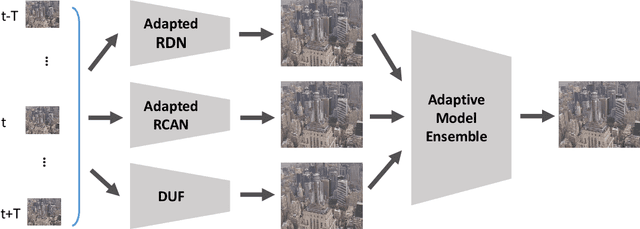
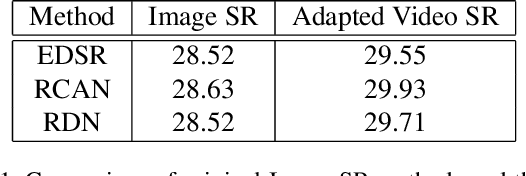
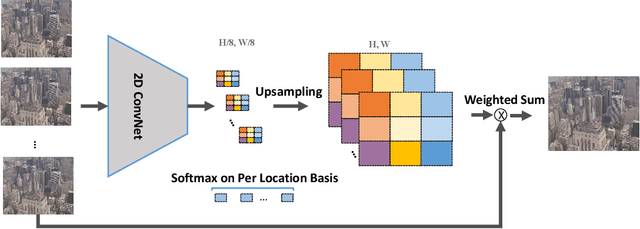

Recently, image super-resolution has been widely studied and achieved significant progress by leveraging the power of deep convolutional neural networks. However, there has been limited advancement in video super-resolution (VSR) due to the complex temporal patterns in videos. In this paper, we investigate how to adapt state-of-the-art methods of image super-resolution for video super-resolution. The proposed adapting method is straightforward. The information among successive frames is well exploited, while the overhead on the original image super-resolution method is negligible. Furthermore, we propose a learning-based method to ensemble the outputs from multiple super-resolution models. Our methods show superior performance and rank second in the NTIRE2019 Video Super-Resolution Challenge Track 1.
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
Apr 22, 2019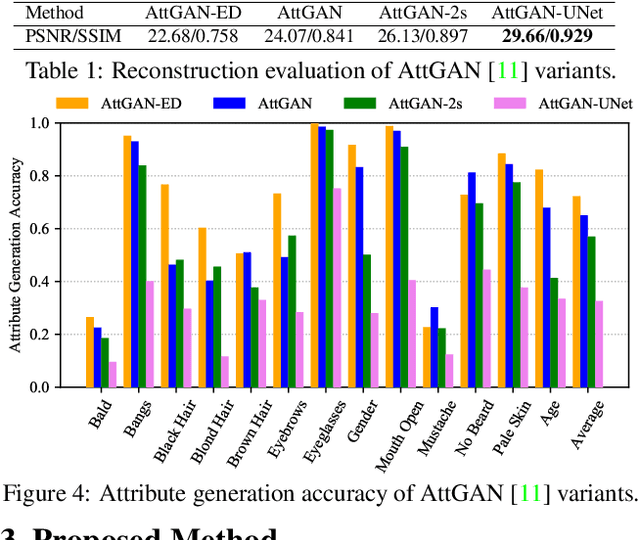



Arbitrary attribute editing generally can be tackled by incorporating encoder-decoder and generative adversarial networks. However, the bottleneck layer in encoder-decoder usually gives rise to blurry and low quality editing result. And adding skip connections improves image quality at the cost of weakened attribute manipulation ability. Moreover, existing methods exploit target attribute vector to guide the flexible translation to desired target domain. In this work, we suggest to address these issues from selective transfer perspective. Considering that specific editing task is certainly only related to the changed attributes instead of all target attributes, our model selectively takes the difference between target and source attribute vectors as input. Furthermore, selective transfer units are incorporated with encoder-decoder to adaptively select and modify encoder feature for enhanced attribute editing. Experiments show that our method (i.e., STGAN) simultaneously improves attribute manipulation accuracy as well as perception quality, and performs favorably against state-of-the-arts in arbitrary facial attribute editing and season translation.
Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation
May 01, 2017
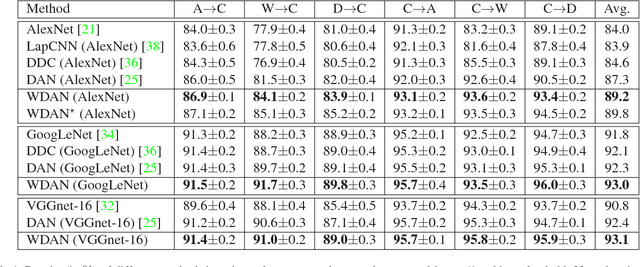


In domain adaptation, maximum mean discrepancy (MMD) has been widely adopted as a discrepancy metric between the distributions of source and target domains. However, existing MMD-based domain adaptation methods generally ignore the changes of class prior distributions, i.e., class weight bias across domains. This remains an open problem but ubiquitous for domain adaptation, which can be caused by changes in sample selection criteria and application scenarios. We show that MMD cannot account for class weight bias and results in degraded domain adaptation performance. To address this issue, a weighted MMD model is proposed in this paper. Specifically, we introduce class-specific auxiliary weights into the original MMD for exploiting the class prior probability on source and target domains, whose challenge lies in the fact that the class label in target domain is unavailable. To account for it, our proposed weighted MMD model is defined by introducing an auxiliary weight for each class in the source domain, and a classification EM algorithm is suggested by alternating between assigning the pseudo-labels, estimating auxiliary weights and updating model parameters. Extensive experiments demonstrate the superiority of our weighted MMD over conventional MMD for domain adaptation.