 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantViR: Real-Time Video Inverse Problem Solver with Distilled Diffusion Prior
Nov 18, 2025Video inverse problems are fundamental to streaming, telepresence, and AR/VR, where high perceptual quality must coexist with tight latency constraints. Diffusion-based priors currently deliver state-of-the-art reconstructions, but existing approaches either adapt image diffusion models with ad hoc temporal regularizers - leading to temporal artifacts - or rely on native video diffusion models whose iterative posterior sampling is far too slow for real-time use. We introduce InstantViR, an amortized inference framework for ultra-fast video reconstruction powered by a pre-trained video diffusion prior. We distill a powerful bidirectional video diffusion model (teacher) into a causal autoregressive student that maps a degraded video directly to its restored version in a single forward pass, inheriting the teacher's strong temporal modeling while completely removing iterative test-time optimization. The distillation is prior-driven: it only requires the teacher diffusion model and known degradation operators, and does not rely on externally paired clean/noisy video data. To further boost throughput, we replace the video-diffusion backbone VAE with a high-efficiency LeanVAE via an innovative teacher-space regularized distillation scheme, enabling low-latency latent-space processing. Across streaming random inpainting, Gaussian deblurring and super-resolution, InstantViR matches or surpasses the reconstruction quality of diffusion-based baselines while running at over 35 FPS on NVIDIA A100 GPUs, achieving up to 100 times speedups over iterative video diffusion solvers. These results show that diffusion-based video reconstruction is compatible with real-time, interactive, editable, streaming scenarios, turning high-quality video restoration into a practical component of modern vision systems.
HPGN: Hybrid Priors-Guided Network for Compressed Low-Light Image Enhancement
Apr 03, 2025In practical applications, conventional methods generate large volumes of low-light images that require compression for efficient storage and transmission. However, most existing methods either disregard the removal of potential compression artifacts during the enhancement process or fail to establish a unified framework for joint task enhancement of images with varying compression qualities. To solve this problem, we propose the hybrid priors-guided network (HPGN), which enhances compressed low-light images by integrating both compression and illumination priors. Our approach fully utilizes the JPEG quality factor (QF) and DCT quantization matrix (QM) to guide the design of efficient joint task plug-and-play modules. Additionally, we employ a random QF generation strategy to guide model training, enabling a single model to enhance images across different compression levels. Experimental results confirm the superiority of our proposed method.
Visual Autoregressive Modeling for Image Super-Resolution
Jan 31, 2025



Image Super-Resolution (ISR) has seen significant progress with the introduction of remarkable generative models. However, challenges such as the trade-off issues between fidelity and realism, as well as computational complexity, have also posed limitations on their application. Building upon the tremendous success of autoregressive models in the language domain, we propose \textbf{VARSR}, a novel visual autoregressive modeling for ISR framework with the form of next-scale prediction. To effectively integrate and preserve semantic information in low-resolution images, we propose using prefix tokens to incorporate the condition. Scale-aligned Rotary Positional Encodings are introduced to capture spatial structures and the diffusion refiner is utilized for modeling quantization residual loss to achieve pixel-level fidelity. Image-based Classifier-free Guidance is proposed to guide the generation of more realistic images. Furthermore, we collect large-scale data and design a training process to obtain robust generative priors. Quantitative and qualitative results show that VARSR is capable of generating high-fidelity and high-realism images with more efficiency than diffusion-based methods. Our codes will be released at https://github.com/qyp2000/VARSR.
Plug-and-Play Tri-Branch Invertible Block for Image Rescaling
Dec 18, 2024High-resolution (HR) images are commonly downscaled to low-resolution (LR) to reduce bandwidth, followed by upscaling to restore their original details. Recent advancements in image rescaling algorithms have employed invertible neural networks (INNs) to create a unified framework for downscaling and upscaling, ensuring a one-to-one mapping between LR and HR images. Traditional methods, utilizing dual-branch based vanilla invertible blocks, process high-frequency and low-frequency information separately, often relying on specific distributions to model high-frequency components. However, processing the low-frequency component directly in the RGB domain introduces channel redundancy, limiting the efficiency of image reconstruction. To address these challenges, we propose a plug-and-play tri-branch invertible block (T-InvBlocks) that decomposes the low-frequency branch into luminance (Y) and chrominance (CbCr) components, reducing redundancy and enhancing feature processing. Additionally, we adopt an all-zero mapping strategy for high-frequency components during upscaling, focusing essential rescaling information within the LR image. Our T-InvBlocks can be seamlessly integrated into existing rescaling models, improving performance in both general rescaling tasks and scenarios involving lossy compression. Extensive experiments confirm that our method advances the state of the art in HR image reconstruction.
OAPT: Offset-Aware Partition Transformer for Double JPEG Artifacts Removal
Aug 21, 2024



Deep learning-based methods have shown remarkable performance in single JPEG artifacts removal task. However, existing methods tend to degrade on double JPEG images, which are prevalent in real-world scenarios. To address this issue, we propose Offset-Aware Partition Transformer for double JPEG artifacts removal, termed as OAPT. We conduct an analysis of double JPEG compression that results in up to four patterns within each 8x8 block and design our model to cluster the similar patterns to remedy the difficulty of restoration. Our OAPT consists of two components: compression offset predictor and image reconstructor. Specifically, the predictor estimates pixel offsets between the first and second compression, which are then utilized to divide different patterns. The reconstructor is mainly based on several Hybrid Partition Attention Blocks (HPAB), combining vanilla window-based self-attention and sparse attention for clustered pattern features. Extensive experiments demonstrate that OAPT outperforms the state-of-the-art method by more than 0.16dB in double JPEG image restoration task. Moreover, without increasing any computation cost, the pattern clustering module in HPAB can serve as a plugin to enhance other transformer-based image restoration methods. The code will be available at https://github.com/QMoQ/OAPT.git .
PTM-VQA: Efficient Video Quality Assessment Leveraging Diverse PreTrained Models from the Wild
May 28, 2024

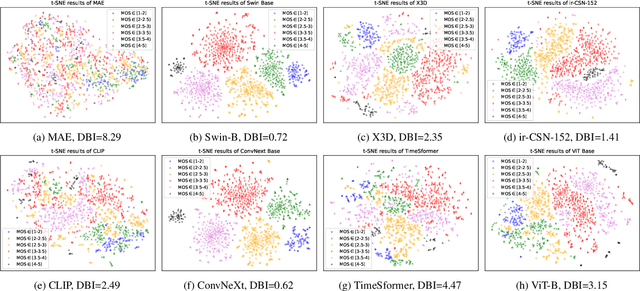

Video quality assessment (VQA) is a challenging problem due to the numerous factors that can affect the perceptual quality of a video, \eg, content attractiveness, distortion type, motion pattern, and level. However, annotating the Mean opinion score (MOS) for videos is expensive and time-consuming, which limits the scale of VQA datasets, and poses a significant obstacle for deep learning-based methods. In this paper, we propose a VQA method named PTM-VQA, which leverages PreTrained Models to transfer knowledge from models pretrained on various pre-tasks, enabling benefits for VQA from different aspects. Specifically, we extract features of videos from different pretrained models with frozen weights and integrate them to generate representation. Since these models possess various fields of knowledge and are often trained with labels irrelevant to quality, we propose an Intra-Consistency and Inter-Divisibility (ICID) loss to impose constraints on features extracted by multiple pretrained models. The intra-consistency constraint ensures that features extracted by different pretrained models are in the same unified quality-aware latent space, while the inter-divisibility introduces pseudo clusters based on the annotation of samples and tries to separate features of samples from different clusters. Furthermore, with a constantly growing number of pretrained models, it is crucial to determine which models to use and how to use them. To address this problem, we propose an efficient scheme to select suitable candidates. Models with better clustering performance on VQA datasets are chosen to be our candidates. Extensive experiments demonstrate the effectiveness of the proposed method.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024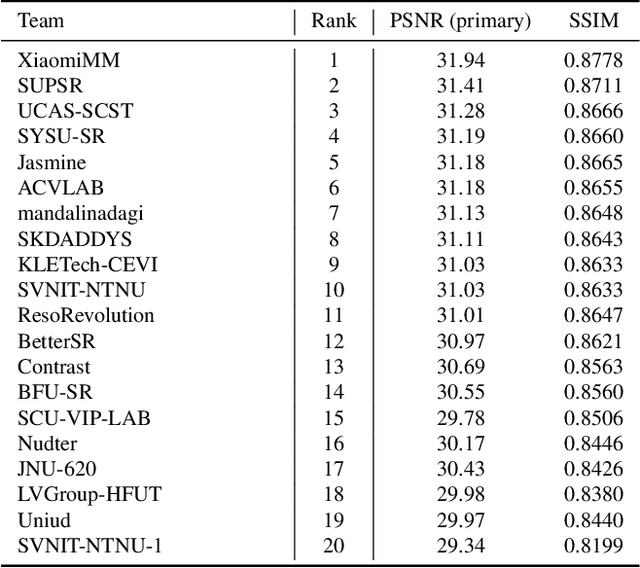
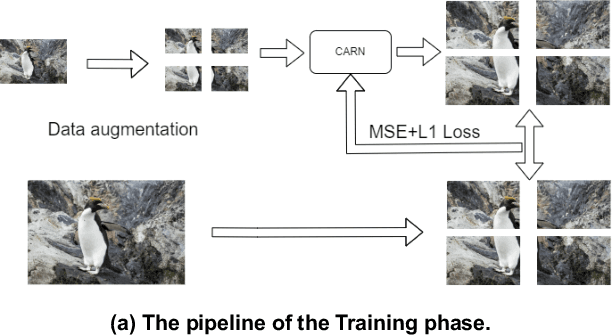
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.
CPGA: Coding Priors-Guided Aggregation Network for Compressed Video Quality Enhancement
Mar 15, 2024



Recently, numerous approaches have achieved notable success in compressed video quality enhancement (VQE). However, these methods usually ignore the utilization of valuable coding priors inherently embedded in compressed videos, such as motion vectors and residual frames, which carry abundant temporal and spatial information. To remedy this problem, we propose the Coding Priors-Guided Aggregation (CPGA) network to utilize temporal and spatial information from coding priors. The CPGA mainly consists of an inter-frame temporal aggregation (ITA) module and a multi-scale non-local aggregation (MNA) module. Specifically, the ITA module aggregates temporal information from consecutive frames and coding priors, while the MNA module globally captures spatial information guided by residual frames. In addition, to facilitate research in VQE task, we newly construct the Video Coding Priors (VCP) dataset, comprising 300 videos with various coding priors extracted from corresponding bitstreams. It remedies the shortage of previous datasets on the lack of coding information. Experimental results demonstrate the superiority of our method compared to existing state-of-the-art methods. The code and dataset will be released at https://github.com/CPGA/CPGA.git.
XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution
Mar 08, 2024
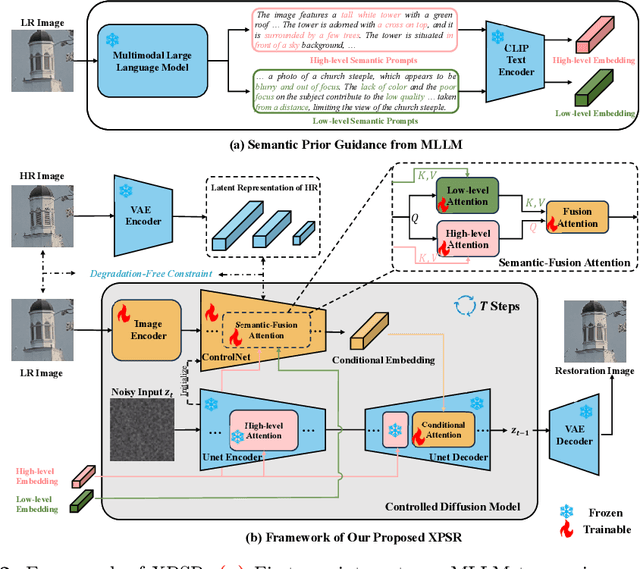
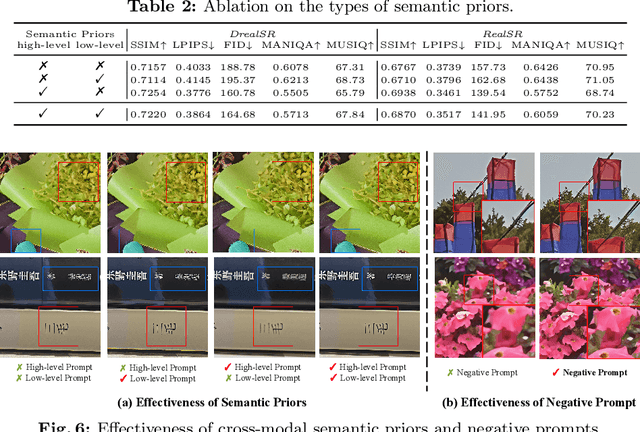
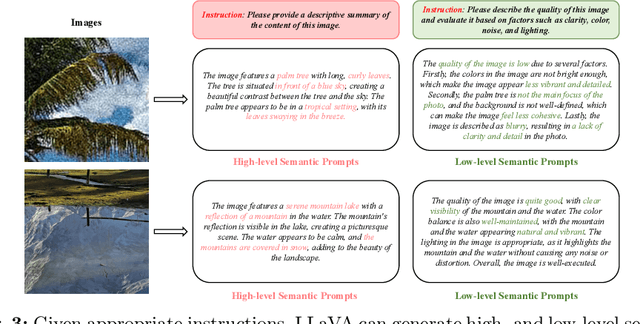
Diffusion-based methods, endowed with a formidable generative prior, have received increasing attention in Image Super-Resolution (ISR) recently. However, as low-resolution (LR) images often undergo severe degradation, it is challenging for ISR models to perceive the semantic and degradation information, resulting in restoration images with incorrect content or unrealistic artifacts. To address these issues, we propose a \textit{Cross-modal Priors for Super-Resolution (XPSR)} framework. Within XPSR, to acquire precise and comprehensive semantic conditions for the diffusion model, cutting-edge Multimodal Large Language Models (MLLMs) are utilized. To facilitate better fusion of cross-modal priors, a \textit{Semantic-Fusion Attention} is raised. To distill semantic-preserved information instead of undesired degradations, a \textit{Degradation-Free Constraint} is attached between LR and its high-resolution (HR) counterpart. Quantitative and qualitative results show that XPSR is capable of generating high-fidelity and high-realism images across synthetic and real-world datasets. Codes will be released at \url{https://github.com/qyp2000/XPSR}.