 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
Feb 06, 2025Model merging aggregates Large Language Models (LLMs) finetuned on different tasks into a stronger one. However, parameter conflicts between models leads to performance degradation in averaging. While model routing addresses this issue by selecting individual models during inference, it imposes excessive storage and compute costs, and fails to leverage the common knowledge from different models. In this work, we observe that different layers exhibit varying levels of parameter conflicts. Building on this insight, we average layers with minimal parameter conflicts and use a novel task-level expert routing for layers with significant conflicts. To further reduce storage costs, inspired by task arithmetic sparsity, we decouple multiple fine-tuned experts into a dense expert and several sparse experts. Considering the out-of-distribution samples, we select and merge appropriate experts based on the task uncertainty of the input data. We conduct extensive experiments on both LLaMA and Qwen with varying parameter scales, and evaluate on real-world reasoning tasks. Results demonstrate that our method consistently achieves significant performance improvements while requiring less system cost compared to existing methods.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023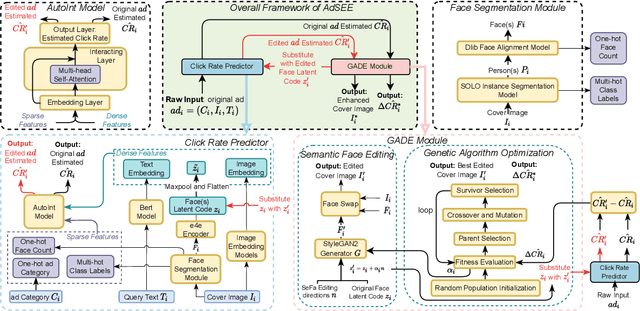


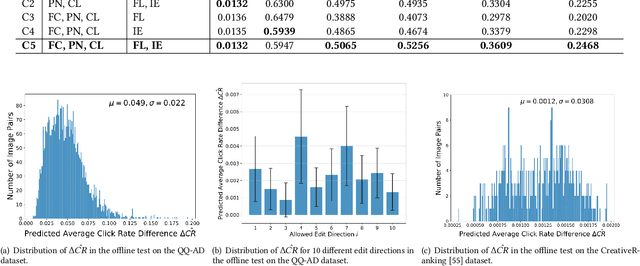
Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
Deep Point Set Resampling via Gradient Fields
Nov 03, 2021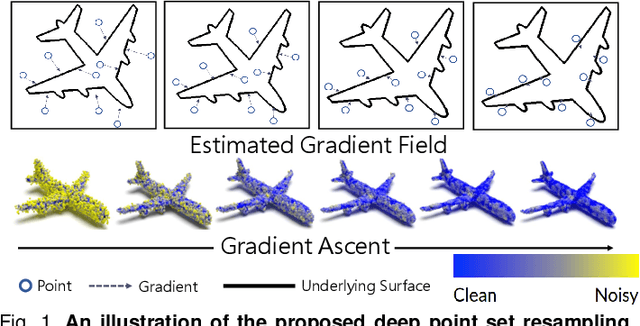
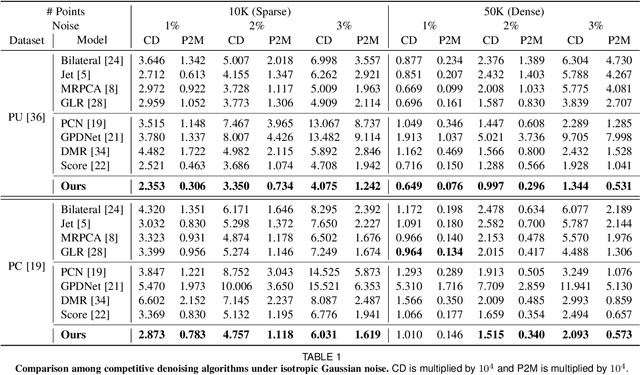
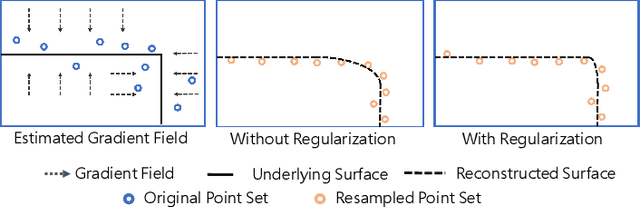
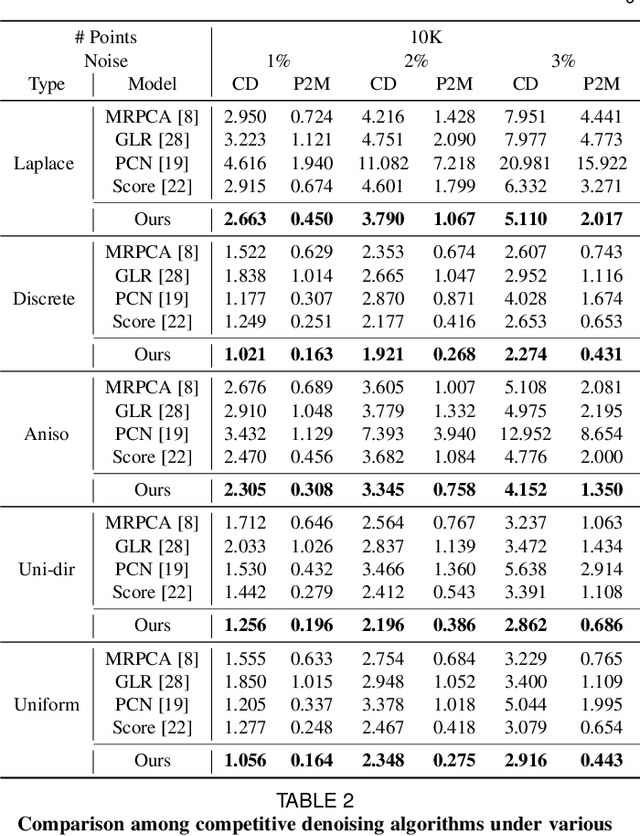
3D point clouds acquired by scanning real-world objects or scenes have found a wide range of applications including immersive telepresence, autonomous driving, surveillance, etc. They are often perturbed by noise or suffer from low density, which obstructs downstream tasks such as surface reconstruction and understanding. In this paper, we propose a novel paradigm of point set resampling for restoration, which learns continuous gradient fields of point clouds that converge points towards the underlying surface. In particular, we represent a point cloud via its gradient field -- the gradient of the log-probability density function, and enforce the gradient field to be continuous, thus guaranteeing the continuity of the model for solvable optimization. Based on the continuous gradient fields estimated via a proposed neural network, resampling a point cloud amounts to performing gradient-based Markov Chain Monte Carlo (MCMC) on the input noisy or sparse point cloud. Further, we propose to introduce regularization into the gradient-based MCMC during point cloud restoration, which essentially refines the intermediate resampled point cloud iteratively and accommodates various priors in the resampling process. Extensive experimental results demonstrate that the proposed point set resampling achieves the state-of-the-art performance in representative restoration tasks including point cloud denoising and upsampling.
QBSUM: a Large-Scale Query-Based Document Summarization Dataset from Real-world Applications
Oct 28, 2020
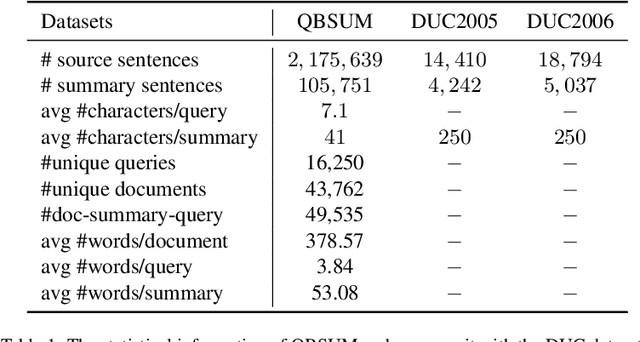
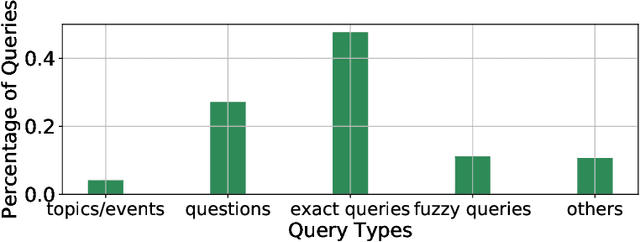

Query-based document summarization aims to extract or generate a summary of a document which directly answers or is relevant to the search query. It is an important technique that can be beneficial to a variety of applications such as search engines, document-level machine reading comprehension, and chatbots. Currently, datasets designed for query-based summarization are short in numbers and existing datasets are also limited in both scale and quality. Moreover, to the best of our knowledge, there is no publicly available dataset for Chinese query-based document summarization. In this paper, we present QBSUM, a high-quality large-scale dataset consisting of 49,000+ data samples for the task of Chinese query-based document summarization. We also propose multiple unsupervised and supervised solutions to the task and demonstrate their high-speed inference and superior performance via both offline experiments and online A/B tests. The QBSUM dataset is released in order to facilitate future advancement of this research field.
Asking Questions the Human Way: Scalable Question-Answer Generation from Text Corpus
Mar 05, 2020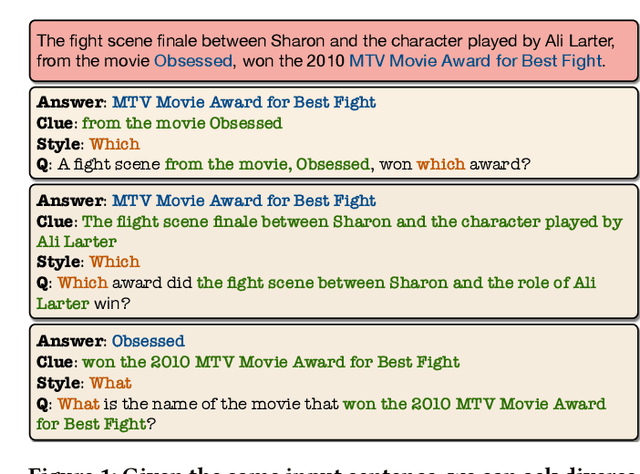
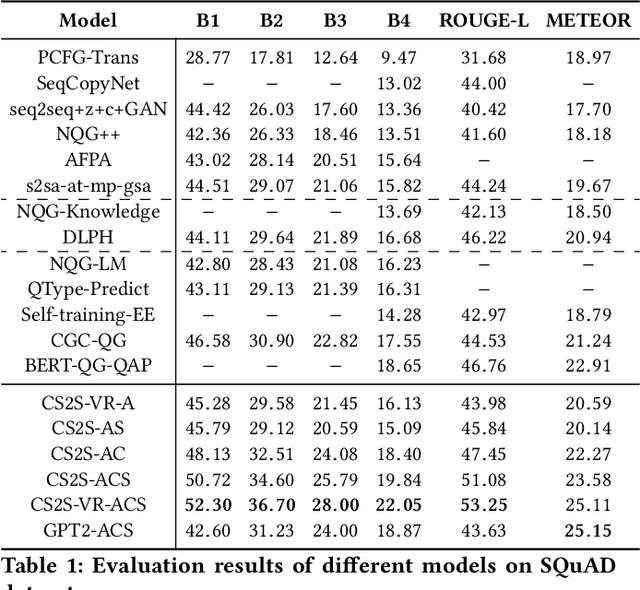
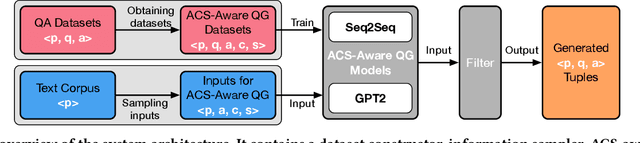
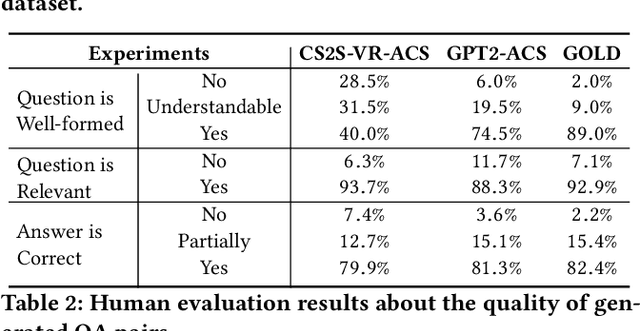
The ability to ask questions is important in both human and machine intelligence. Learning to ask questions helps knowledge acquisition, improves question-answering and machine reading comprehension tasks, and helps a chatbot to keep the conversation flowing with a human. Existing question generation models are ineffective at generating a large amount of high-quality question-answer pairs from unstructured text, since given an answer and an input passage, question generation is inherently a one-to-many mapping. In this paper, we propose Answer-Clue-Style-aware Question Generation (ACS-QG), which aims at automatically generating high-quality and diverse question-answer pairs from unlabeled text corpus at scale by imitating the way a human asks questions. Our system consists of: i) an information extractor, which samples from the text multiple types of assistive information to guide question generation; ii) neural question generators, which generate diverse and controllable questions, leveraging the extracted assistive information; and iii) a neural quality controller, which removes low-quality generated data based on text entailment. We compare our question generation models with existing approaches and resort to voluntary human evaluation to assess the quality of the generated question-answer pairs. The evaluation results suggest that our system dramatically outperforms state-of-the-art neural question generation models in terms of the generation quality, while being scalable in the meantime. With models trained on a relatively smaller amount of data, we can generate 2.8 million quality-assured question-answer pairs from a million sentences found in Wikipedia.