 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAJL: A Model-Agnostic Joint Learning Framework for Music Source Separation and Pitch Estimation
Jan 07, 2025



Music source separation and pitch estimation are two vital tasks in music information retrieval. Typically, the input of pitch estimation is obtained from the output of music source separation. Therefore, existing methods have tried to perform these two tasks simultaneously, so as to leverage the mutually beneficial relationship between both tasks. However, these methods still face two critical challenges that limit the improvement of both tasks: the lack of labeled data and joint learning optimization. To address these challenges, we propose a Model-Agnostic Joint Learning (MAJL) framework for both tasks. MAJL is a generic framework and can use variant models for each task. It includes a two-stage training method and a dynamic weighting method named Dynamic Weights on Hard Samples (DWHS), which addresses the lack of labeled data and joint learning optimization, respectively. Experimental results on public music datasets show that MAJL outperforms state-of-the-art methods on both tasks, with significant improvements of 0.92 in Signal-to-Distortion Ratio (SDR) for music source separation and 2.71% in Raw Pitch Accuracy (RPA) for pitch estimation. Furthermore, comprehensive studies not only validate the effectiveness of each component of MAJL, but also indicate the great generality of MAJL in adapting to different model architectures.
Unveiling and Consulting Core Experts in Retrieval-Augmented MoE-based LLMs
Oct 20, 2024Retrieval-Augmented Generation (RAG) significantly improved the ability of Large Language Models (LLMs) to solve knowledge-intensive tasks. While existing research seeks to enhance RAG performance by retrieving higher-quality documents or designing RAG-specific LLMs, the internal mechanisms within LLMs that contribute to the effectiveness of RAG systems remain underexplored. In this paper, we aim to investigate these internal mechanisms within the popular Mixture-of-Expert (MoE)-based LLMs and demonstrate how to improve RAG by examining expert activations in these LLMs. Our controlled experiments reveal that several core groups of experts are primarily responsible for RAG-related behaviors. The activation of these core experts can signify the model's inclination towards external/internal knowledge and adjust its behavior. For instance, we identify core experts that can (1) indicate the sufficiency of the model's internal knowledge, (2) assess the quality of retrieved documents, and (3) enhance the model's ability to utilize context. Based on these findings, we propose several strategies to enhance RAG's efficiency and effectiveness through expert activation. Experimental results across various datasets and MoE-based LLMs show the effectiveness of our method.
SongTrans: An unified song transcription and alignment method for lyrics and notes
Sep 22, 2024



The quantity of processed data is crucial for advancing the field of singing voice synthesis. While there are tools available for lyric or note transcription tasks, they all need pre-processed data which is relatively time-consuming (e.g., vocal and accompaniment separation). Besides, most of these tools are designed to address a single task and struggle with aligning lyrics and notes (i.e., identifying the corresponding notes of each word in lyrics). To address those challenges, we first design a pipeline by optimizing existing tools and annotating numerous lyric-note pairs of songs. Then, based on the annotated data, we train a unified SongTrans model that can directly transcribe lyrics and notes while aligning them simultaneously, without requiring pre-processing songs. Our SongTrans model consists of two modules: (1) the \textbf{Autoregressive module} predicts the lyrics, along with the duration and note number corresponding to each word in a lyric. (2) the \textbf{Non-autoregressive module} predicts the pitch and duration of the notes. Our experiments demonstrate that SongTrans achieves state-of-the-art (SOTA) results in both lyric and note transcription tasks. Furthermore, it is the first model capable of aligning lyrics with notes. Experimental results demonstrate that the SongTrans model can effectively adapt to different types of songs (e.g., songs with accompaniment), showcasing its versatility for real-world applications.
BEYOND DIALOGUE: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model
Aug 21, 2024The rapid advancement of large language models (LLMs) has revolutionized role-playing, enabling the development of general role-playing models. However, current role-playing training has two significant issues: (I) Using a predefined role profile to prompt dialogue training for specific scenarios usually leads to inconsistencies and even conflicts between the dialogue and the profile, resulting in training biases. (II) The model learns to imitate the role based solely on the profile, neglecting profile-dialogue alignment at the sentence level. In this work, we propose a simple yet effective framework called BEYOND DIALOGUE, designed to overcome these hurdles. This framework innovatively introduces "beyond dialogue" tasks to align dialogue with profile traits based on each specific scenario, thereby eliminating biases during training. Furthermore, by adopting an innovative prompting mechanism that generates reasoning outcomes for training, the framework allows the model to achieve fine-grained alignment between profile and dialogue at the sentence level. The aforementioned methods are fully automated and low-cost. Additionally, the integration of automated dialogue and objective evaluation methods forms a comprehensive framework, paving the way for general role-playing. Experimental results demonstrate that our model excels in adhering to and reflecting various dimensions of role profiles, outperforming most proprietary general and specialized role-playing baselines. All code and datasets are available at https://github.com/yuyouyu32/BeyondDialogue.
Qwen2-Audio Technical Report
Jul 15, 2024We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community.
DJCM: A Deep Joint Cascade Model for Singing Voice Separation and Vocal Pitch Estimation
Jan 08, 2024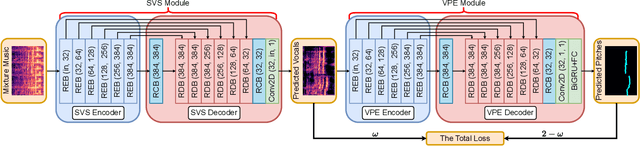



Singing voice separation and vocal pitch estimation are pivotal tasks in music information retrieval. Existing methods for simultaneous extraction of clean vocals and vocal pitches can be classified into two categories: pipeline methods and naive joint learning methods. However, the efficacy of these methods is limited by the following problems: On the one hand, pipeline methods train models for each task independently, resulting a mismatch between the data distributions at the training and testing time. On the other hand, naive joint learning methods simply add the losses of both tasks, possibly leading to a misalignment between the distinct objectives of each task. To solve these problems, we propose a Deep Joint Cascade Model (DJCM) for singing voice separation and vocal pitch estimation. DJCM employs a novel joint cascade model structure to concurrently train both tasks. Moreover, task-specific weights are used to align different objectives of both tasks. Experimental results show that DJCM achieves state-of-the-art performance on both tasks, with great improvements of 0.45 in terms of Signal-to-Distortion Ratio (SDR) for singing voice separation and 2.86% in terms of Overall Accuracy (OA) for vocal pitch estimation. Furthermore, extensive ablation studies validate the effectiveness of each design of our proposed model. The code of DJCM is available at https://github.com/Dream-High/DJCM .
RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music
Jun 28, 2023Vocal pitch is an important high-level feature in music audio processing. However, extracting vocal pitch in polyphonic music is more challenging due to the presence of accompaniment. To eliminate the influence of the accompaniment, most previous methods adopt music source separation models to obtain clean vocals from polyphonic music before predicting vocal pitches. As a result, the performance of vocal pitch estimation is affected by the music source separation models. To address this issue and directly extract vocal pitches from polyphonic music, we propose a robust model named RMVPE. This model can extract effective hidden features and accurately predict vocal pitches from polyphonic music. The experimental results demonstrate the superiority of RMVPE in terms of raw pitch accuracy (RPA) and raw chroma accuracy (RCA). Additionally, experiments conducted with different types of noise show that RMVPE is robust across all signal-to-noise ratio (SNR) levels. The code of RMVPE is available at https://github.com/Dream-High/RMVPE.
JEPOO: Highly Accurate Joint Estimation of Pitch, Onset and Offset for Music Information Retrieval
Jun 02, 2023Melody extraction is a core task in music information retrieval, and the estimation of pitch, onset and offset are key sub-tasks in melody extraction. Existing methods have limited accuracy, and work for only one type of data, either single-pitch or multipitch. In this paper, we propose a highly accurate method for joint estimation of pitch, onset and offset, named JEPOO. We address the challenges of joint learning optimization and handling both single-pitch and multi-pitch data through novel model design and a new optimization technique named Pareto modulated loss with loss weight regularization. This is the first method that can accurately handle both single-pitch and multi-pitch music data, and even a mix of them. A comprehensive experimental study on a wide range of real datasets shows that JEPOO outperforms state-ofthe-art methods by up to 10.6%, 8.3% and 10.3% for the prediction of Pitch, Onset and Offset, respectively, and JEPOO is robust for various types of data and instruments. The ablation study shows the effectiveness of each component of JEPOO.
Asking Questions the Human Way: Scalable Question-Answer Generation from Text Corpus
Mar 05, 2020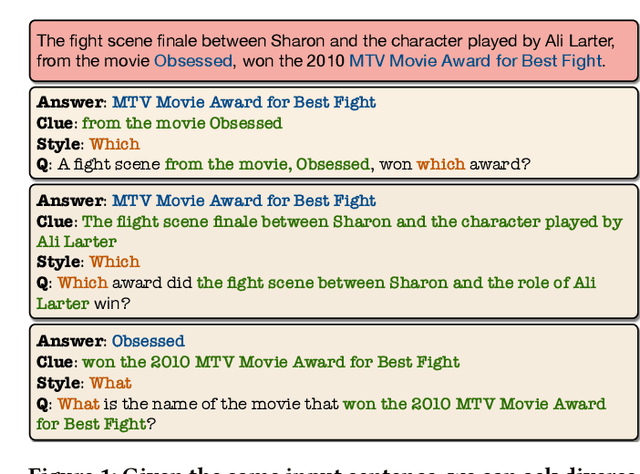
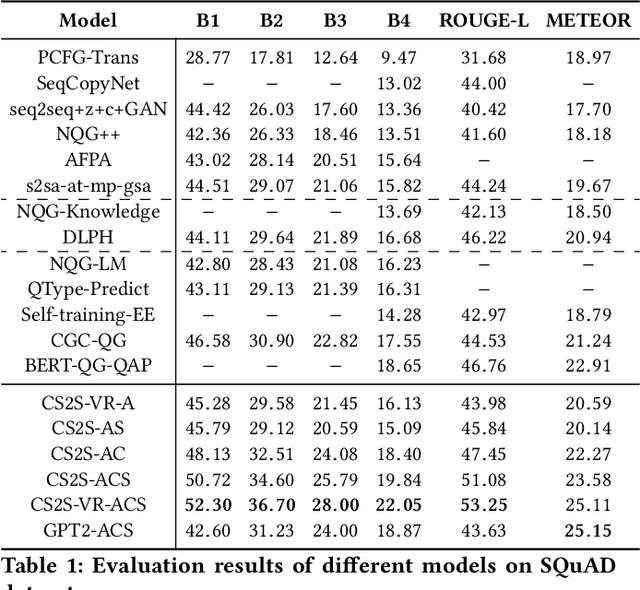
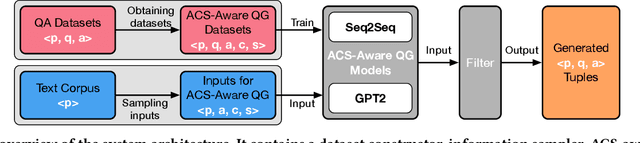
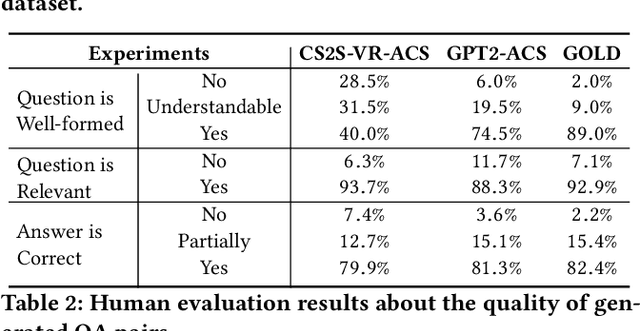
The ability to ask questions is important in both human and machine intelligence. Learning to ask questions helps knowledge acquisition, improves question-answering and machine reading comprehension tasks, and helps a chatbot to keep the conversation flowing with a human. Existing question generation models are ineffective at generating a large amount of high-quality question-answer pairs from unstructured text, since given an answer and an input passage, question generation is inherently a one-to-many mapping. In this paper, we propose Answer-Clue-Style-aware Question Generation (ACS-QG), which aims at automatically generating high-quality and diverse question-answer pairs from unlabeled text corpus at scale by imitating the way a human asks questions. Our system consists of: i) an information extractor, which samples from the text multiple types of assistive information to guide question generation; ii) neural question generators, which generate diverse and controllable questions, leveraging the extracted assistive information; and iii) a neural quality controller, which removes low-quality generated data based on text entailment. We compare our question generation models with existing approaches and resort to voluntary human evaluation to assess the quality of the generated question-answer pairs. The evaluation results suggest that our system dramatically outperforms state-of-the-art neural question generation models in terms of the generation quality, while being scalable in the meantime. With models trained on a relatively smaller amount of data, we can generate 2.8 million quality-assured question-answer pairs from a million sentences found in Wikipedia.
Learning to Generate Questions by Learning What not to Generate
Feb 27, 2019


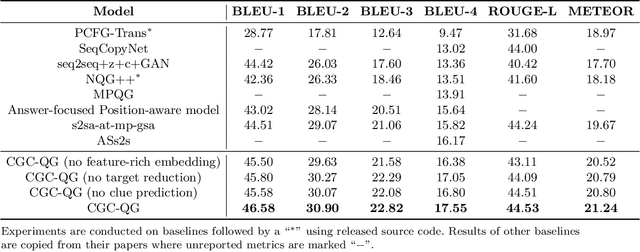
Automatic question generation is an important technique that can improve the training of question answering, help chatbots to start or continue a conversation with humans, and provide assessment materials for educational purposes. Existing neural question generation models are not sufficient mainly due to their inability to properly model the process of how each word in the question is selected, i.e., whether repeating the given passage or being generated from a vocabulary. In this paper, we propose our Clue Guided Copy Network for Question Generation (CGC-QG), which is a sequence-to-sequence generative model with copying mechanism, yet employing a variety of novel components and techniques to boost the performance of question generation. In CGC-QG, we design a multi-task labeling strategy to identify whether a question word should be copied from the input passage or be generated instead, guiding the model to learn the accurate boundaries between copying and generation. Furthermore, our input passage encoder takes as input, among a diverse range of other features, the prediction made by a clue word predictor, which helps identify whether each word in the input passage is a potential clue to be copied into the target question. The clue word predictor is designed based on a novel application of Graph Convolutional Networks onto a syntactic dependency tree representation of each passage, thus being able to predict clue words only based on their context in the passage and their relative positions to the answer in the tree. We jointly train the clue prediction as well as question generation with multi-task learning and a number of practical strategies to reduce the complexity. Extensive evaluations show that our model significantly improves the performance of question generation and out-performs all previous state-of-the-art neural question generation models by a substantial margin.