 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Composed Image Retrieval Benchmarks Require Multimodal Composition?
May 14, 2026Composed Image Retrieval (CIR) is a multimodal retrieval task where a query consists of a reference image and a textual modification, and the goal is to retrieve a target image satisfying both. In principle, strong performance on CIR benchmarks is assumed to require multimodal composition, i.e., combining complementary information from reference image and textual modification. In this work, we show that this assumption does not always hold. Across four widely used CIR benchmarks and eleven Generalist Multimodal Embedding models, a large fraction of queries can be solved using a single modality (from 32.2% to 83.6%), revealing pervasive unimodal shortcuts. Thus, high CIR performance can arise from unimodal signals rather than true multimodal composition. To better understand this issue, we perform a two-stage audit. First, we identify shortcut-solvable queries through cross-model analysis. Second, we conduct human validation on 4,741 shortcut-free queries, of which only 1,689 are well-formed, with common issues including ambiguous edits and mismatched targets. Re-evaluating models on this validated subset reveals qualitatively different behaviour: queries can no longer be solved with a single modality, and successful retrieval requires combining both inputs. While accuracy decreases, reliance on multimodal information increases. Overall, current CIR benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries, leading to an overestimation of model capability in multimodal composition.
Rethinking the Harmonic Loss via Non-Euclidean Distance Layers
Mar 12, 2026Cross-entropy loss has long been the standard choice for training deep neural networks, yet it suffers from interpretability limitations, unbounded weight growth, and inefficiencies that can contribute to costly training dynamics. The harmonic loss is a distance-based alternative grounded in Euclidean geometry that improves interpretability and mitigates phenomena such as grokking, or delayed generalization on the test set. However, the study of harmonic loss remains narrow: only Euclidean distance is explored, and no systematic evaluation of computational efficiency or sustainability was conducted. We extend harmonic loss by systematically investigating a broad spectrum of distance metrics as replacements for the Euclidean distance. We comprehensively evaluate distance-tailored harmonic losses on both vision backbones and large language models. Our analysis is framed around a three-way evaluation of model performance, interpretability, and sustainability. On vision tasks, cosine distances provide the most favorable trade-off, consistently improving accuracy while lowering carbon emissions, whereas Bray-Curtis and Mahalanobis further enhance interpretability at varying efficiency costs. On language models, cosine-based harmonic losses improve gradient and learning stability, strengthen representation structure, and reduce emissions relative to cross-entropy and Euclidean heads. Our code is available at: https://anonymous.4open.science/r/rethinking-harmonic-loss-5BAB/.
Process-Supervised Multi-Agent Reinforcement Learning for Reliable Clinical Reasoning
Feb 15, 2026Clinical decision-making requires nuanced reasoning over heterogeneous evidence and traceable justifications. While recent LLM multi-agent systems (MAS) show promise, they largely optimise for outcome accuracy while overlooking process-grounded reasoning aligned with clinical standards. One critical real-world case of this is gene-disease validity curation, where experts must determine whether a gene is causally implicated in a disease by synthesising diverse biomedical evidence. We introduce an agent-as-tool reinforcement learning framework for this task with two objectives: (i) process-level supervision to ensure reasoning follows valid clinical pathways, and (ii) efficient coordination via a hierarchical multi-agent system. Our evaluation on the ClinGen dataset shows that with outcome-only rewards, MAS with a GRPO-trained Qwen3-4B supervisor agent substantially improves final outcome accuracy from 0.195 with a base model supervisor to 0.732, but results in poor process alignment (0.392 F1). Conversely, with process + outcome rewards, MAS with GRPO-trained supervisor achieves higher outcome accuracy (0.750) while significantly improving process fidelity to 0.520 F1. Our code is available at https://github.com/chaeeunlee-io/GeneDiseaseCurationAgents.
Same Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
Agentic Uncertainty Reveals Agentic Overconfidence
Feb 06, 2026Can AI agents predict whether they will succeed at a task? We study agentic uncertainty by eliciting success probability estimates before, during, and after task execution. All results exhibit agentic overconfidence: some agents that succeed only 22% of the time predict 77% success. Counterintuitively, pre-execution assessment with strictly less information tends to yield better discrimination than standard post-execution review, though differences are not always significant. Adversarial prompting reframing assessment as bug-finding achieves the best calibration.
Enhancing Long Document Long Form Summarisation with Self-Planning
Dec 19, 2025We introduce a novel approach for long context summarisation, highlight-guided generation, that leverages sentence-level information as a content plan to improve the traceability and faithfulness of generated summaries. Our framework applies self-planning methods to identify important content and then generates a summary conditioned on the plan. We explore both an end-to-end and two-stage variants of the approach, finding that the two-stage pipeline performs better on long and information-dense documents. Experiments on long-form summarisation datasets demonstrate that our method consistently improves factual consistency while preserving relevance and overall quality. On GovReport, our best approach has improved ROUGE-L by 4.1 points and achieves about 35% gains in SummaC scores. Qualitative analysis shows that highlight-guided summarisation helps preserve important details, leading to more accurate and insightful summaries across domains.
Low-Rank Compression of Language Models via Differentiable Rank Selection
Dec 14, 2025
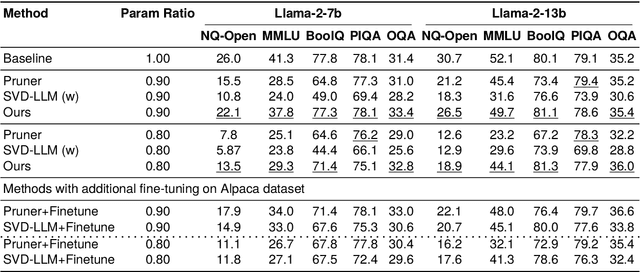
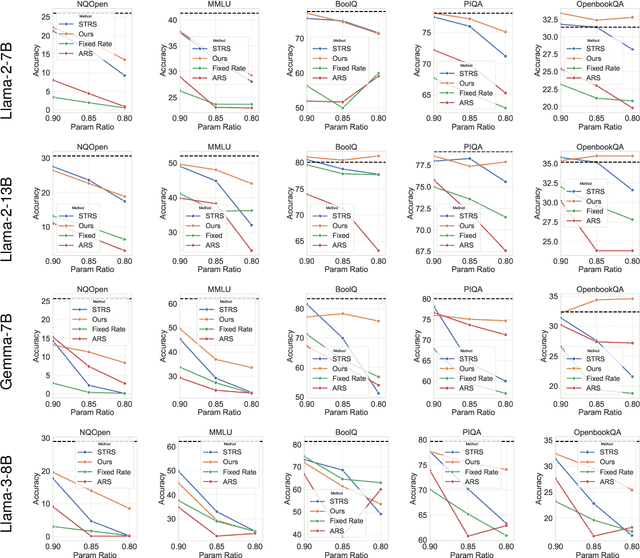
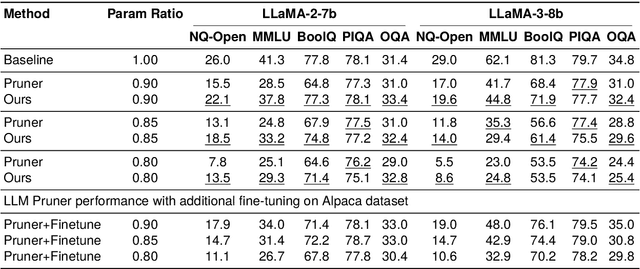
Approaches for compressing large-language models using low-rank decomposition have made strides, particularly with the introduction of activation and loss-aware SVD, which improves the trade-off between decomposition rank and downstream task performance. Despite these advancements, a persistent challenge remains--selecting the optimal ranks for each layer to jointly optimise compression rate and downstream task accuracy. Current methods either rely on heuristics that can yield sub-optimal results due to their limited discrete search space or are gradient-based but are not as performant as heuristic approaches without post-compression fine-tuning. To address these issues, we propose Learning to Low-Rank Compress (LLRC), a gradient-based approach which directly learns the weights of masks that select singular values in a fine-tuning-free setting. Using a calibration dataset, we train only the mask weights to select fewer and fewer singular values while minimising the divergence of intermediate activations from the original model. Our approach outperforms competing ranking selection methods that similarly require no post-compression fine-tuning across various compression rates on common-sense reasoning and open-domain question-answering tasks. For instance, with a compression rate of 20% on Llama-2-13B, LLRC outperforms the competitive Sensitivity-based Truncation Rank Searching (STRS) on MMLU, BoolQ, and OpenbookQA by 12%, 3.5%, and 4.4%, respectively. Compared to other compression techniques, our approach consistently outperforms fine-tuning-free variants of SVD-LLM and LLM-Pruner across datasets and compression rates. Our fine-tuning-free approach also performs competitively with the fine-tuning variant of LLM-Pruner.
Fast and Expressive Multi-Token Prediction with Probabilistic Circuits
Nov 14, 2025Multi-token prediction (MTP) is a prominent strategy to significantly speed up generation in large language models (LLMs), including byte-level LLMs, which are tokeniser-free but prohibitively slow. However, existing MTP methods often sacrifice expressiveness by assuming independence between future tokens. In this work, we investigate the trade-off between expressiveness and latency in MTP within the framework of probabilistic circuits (PCs). Our framework, named MTPC, allows one to explore different ways to encode the joint distributions over future tokens by selecting different circuit architectures, generalising classical models such as (hierarchical) mixture models, hidden Markov models and tensor networks. We show the efficacy of MTPC by retrofitting existing byte-level LLMs, such as EvaByte. Our experiments show that, when combined with speculative decoding, MTPC significantly speeds up generation compared to MTP with independence assumptions, while guaranteeing to retain the performance of the original verifier LLM. We also rigorously study the optimal trade-off between expressiveness and latency when exploring the possible parameterisations of MTPC, such as PC architectures and partial layer sharing between the verifier and draft LLMs.
PiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
Neurosymbolic Reasoning Shortcuts under the Independence Assumption
Jul 15, 2025The ubiquitous independence assumption among symbolic concepts in neurosymbolic (NeSy) predictors is a convenient simplification: NeSy predictors use it to speed up probabilistic reasoning. Recent works like van Krieken et al. (2024) and Marconato et al. (2024) argued that the independence assumption can hinder learning of NeSy predictors and, more crucially, prevent them from correctly modelling uncertainty. There is, however, scepticism in the NeSy community around the scenarios in which the independence assumption actually limits NeSy systems (Faronius and Dos Martires, 2025). In this work, we settle this question by formally showing that assuming independence among symbolic concepts entails that a model can never represent uncertainty over certain concept combinations. Thus, the model fails to be aware of reasoning shortcuts, i.e., the pathological behaviour of NeSy predictors that predict correct downstream tasks but for the wrong reasons.