 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
PiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models
Jan 30, 2024



Large language models (LLMs) are increasingly relied upon for complex multi-turn conversations across diverse real-world applications. However, existing benchmarks predominantly focus on single-turn evaluations, overlooking the models' capabilities in multi-turn interactions. To address this gap, we introduce MT-Eval, a comprehensive benchmark designed to evaluate multi-turn conversational abilities. By analyzing human-LLM conversations, we categorize interaction patterns into four types: recollection, expansion, refinement, and follow-up. We construct multi-turn queries for each category either by augmenting existing datasets or by creating new examples with GPT-4 to avoid data leakage. To study the factors impacting multi-turn abilities, we create single-turn versions of the 1170 multi-turn queries and compare performance. Our evaluation of 11 well-known LLMs shows that while closed-source models generally surpass open-source ones, certain open-source models exceed GPT-3.5-Turbo in specific tasks. We observe significant performance degradation in multi-turn settings compared to single-turn settings in most models, which is not correlated with the models' fundamental capabilities. Moreover, we identify the distance to relevant content and susceptibility to error propagation as the key factors influencing multi-turn performance. MT-Eval is released publicly to encourage future research towards more robust conversational models.
M4LE: A Multi-Ability Multi-Range Multi-Task Multi-Domain Long-Context Evaluation Benchmark for Large Language Models
Oct 30, 2023



Managing long sequences has become an important and necessary feature for large language models (LLMs). However, it is still an open question of how to comprehensively and systematically evaluate the long-sequence capability of LLMs. One of the reasons is that conventional and widely-used benchmarks mainly consist of short sequences. In this paper, we propose M4LE, a Multi-ability, Multi-range, Multi-task, Multi-domain benchmark for Long-context Evaluation. M4LE is based on a diverse NLP task pool comprising 36 NLP datasets, 11 task types and 12 domains. To alleviate the scarcity of tasks with naturally long sequences and incorporate multiple-ability assessment, we propose an automatic approach (but with negligible human annotations) to convert short-sequence tasks into a unified long-sequence scenario where LLMs have to identify single or multiple relevant spans in long contexts based on explicit or semantic hints. Specifically, the scenario includes five different types of abilities: (1) explicit single-span; (2) semantic single-span; (3) explicit multiple-span; (4) semantic multiple-span; and (5) global context understanding. The resulting samples in M4LE are evenly distributed from 1k to 8k input length. We conducted a systematic evaluation on 11 well-established LLMs, especially those optimized for long-sequence inputs. Our results reveal that: 1) Current LLMs struggle to understand long context, particularly when tasks require multiple-span attention. 2) Semantic retrieval task is more difficult for competent LLMs. 3) Models fine-tuned on longer text with position interpolation have comparable performance to those using Neural Tangent Kernel (NTK) aware scaling methods without fine-tuning. We make our benchmark publicly available to encourage future research in this challenging area.
Large Language Models as Source Planner for Personalized Knowledge-grounded Dialogue
Oct 13, 2023



Open-domain dialogue system usually requires different sources of knowledge to generate more informative and evidential responses. However, existing knowledge-grounded dialogue systems either focus on a single knowledge source or overlook the dependency between multiple sources of knowledge, which may result in generating inconsistent or even paradoxical responses. To incorporate multiple knowledge sources and dependencies between them, we propose SAFARI, a novel framework that leverages the exceptional capabilities of large language models (LLMs) in planning, understanding, and incorporating under both supervised and unsupervised settings. Specifically, SAFARI decouples the knowledge grounding into multiple sources and response generation, which allows easy extension to various knowledge sources including the possibility of not using any sources. To study the problem, we construct a personalized knowledge-grounded dialogue dataset \textit{\textbf{K}nowledge \textbf{B}ehind \textbf{P}ersona}~(\textbf{KBP}), which is the first to consider the dependency between persona and implicit knowledge. Experimental results on the KBP dataset demonstrate that the SAFARI framework can effectively produce persona-consistent and knowledge-enhanced responses.
Dialog Action-Aware Transformer for Dialog Policy Learning
Sep 05, 2023Recent works usually address Dialog policy learning DPL by training a reinforcement learning (RL) agent to determine the best dialog action. However, existing works on deep RL require a large volume of agent-user interactions to achieve acceptable performance. In this paper, we propose to make full use of the plain text knowledge from the pre-trained language model to accelerate the RL agent's learning speed. Specifically, we design a dialog action-aware transformer encoder (DaTrans), which integrates a new fine-tuning procedure named masked last action task to encourage DaTrans to be dialog-aware and distils action-specific features. Then, DaTrans is further optimized in an RL setting with ongoing interactions and evolves through exploration in the dialog action space toward maximizing long-term accumulated rewards. The effectiveness and efficiency of the proposed model are demonstrated with both simulator evaluation and human evaluation.
JoTR: A Joint Transformer and Reinforcement Learning Framework for Dialog Policy Learning
Sep 01, 2023Dialogue policy learning (DPL) is a crucial component of dialogue modelling. Its primary role is to determine the appropriate abstract response, commonly referred to as the "dialogue action". Traditional DPL methodologies have treated this as a sequential decision problem, using pre-defined action candidates extracted from a corpus. However, these incomplete candidates can significantly limit the diversity of responses and pose challenges when dealing with edge cases, which are scenarios that occur only at extreme operating parameters. To address these limitations, we introduce a novel framework, JoTR. This framework is unique as it leverages a text-to-text Transformer-based model to generate flexible dialogue actions. Unlike traditional methods, JoTR formulates a word-level policy that allows for a more dynamic and adaptable dialogue action generation, without the need for any action templates. This setting enhances the diversity of responses and improves the system's ability to handle edge cases effectively. In addition, JoTR employs reinforcement learning with a reward-shaping mechanism to efficiently finetune the word-level dialogue policy, which allows the model to learn from its interactions, improving its performance over time. We conducted an extensive evaluation of JoTR to assess its effectiveness. Our extensive evaluation shows that JoTR achieves state-of-the-art performance on two benchmark dialogue modelling tasks, as assessed by both user simulators and human evaluators.
CoAD: Automatic Diagnosis through Symptom and Disease Collaborative Generation
Jul 17, 2023



Automatic diagnosis (AD), a critical application of AI in healthcare, employs machine learning techniques to assist doctors in gathering patient symptom information for precise disease diagnosis. The Transformer-based method utilizes an input symptom sequence, predicts itself through auto-regression, and employs the hidden state of the final symptom to determine the disease. Despite its simplicity and superior performance demonstrated, a decline in disease diagnosis accuracy is observed caused by 1) a mismatch between symptoms observed during training and generation, and 2) the effect of different symptom orders on disease prediction. To address the above obstacles, we introduce the CoAD, a novel disease and symptom collaborative generation framework, which incorporates several key innovations to improve AD: 1) aligning sentence-level disease labels with multiple possible symptom inquiry steps to bridge the gap between training and generation; 2) expanding symptom labels for each sub-sequence of symptoms to enhance annotation and eliminate the effect of symptom order; 3) developing a repeated symptom input schema to effectively and efficiently learn the expanded disease and symptom labels. We evaluate the CoAD framework using four datasets, including three public and one private, and demonstrate that it achieves an average 2.3% improvement over previous state-of-the-art results in automatic disease diagnosis. For reproducibility, we release the code and data at https://github.com/KwanWaiChung/coad.
Towards Robust Personalized Dialogue Generation via Order-Insensitive Representation Regularization
May 22, 2023



Generating persona consistent dialogue response is important for developing an intelligent conversational agent. Recent works typically fine-tune large-scale pre-trained models on this task by concatenating persona texts and dialogue history as a single input sequence to generate the target response. While simple and effective, our analysis shows that this popular practice is seriously affected by order sensitivity where different input orders of persona sentences significantly impact the quality and consistency of generated response, resulting in severe performance fluctuations (i.e., 29.4% on GPT2 and 83.2% on BART). To mitigate the order sensitivity problem, we propose a model-agnostic framework, ORder Insensitive Generation (ORIG), which enables dialogue models to learn robust representation under different persona orders and improve the consistency of response generation. Experiments on the Persona-Chat dataset justify the effectiveness and superiority of our method with two dominant pre-trained models (GPT2 and BART).
A Survey on Recent Advances and Challenges in Reinforcement LearningMethods for Task-Oriented Dialogue Policy Learning
Feb 28, 2022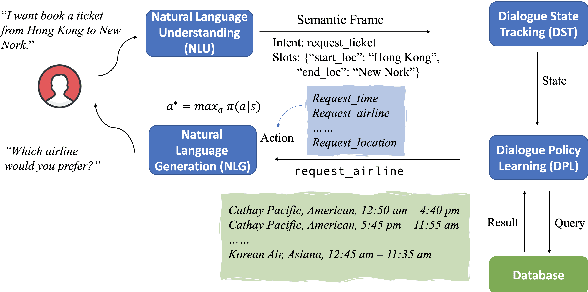
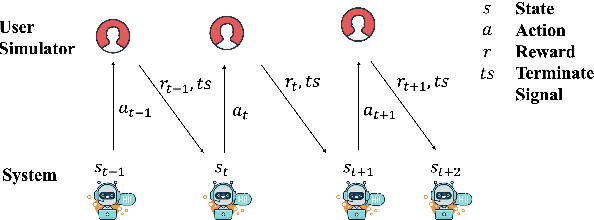
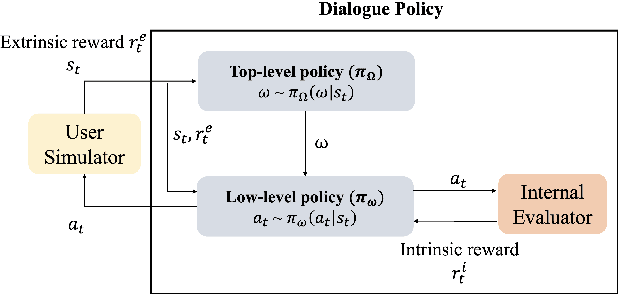
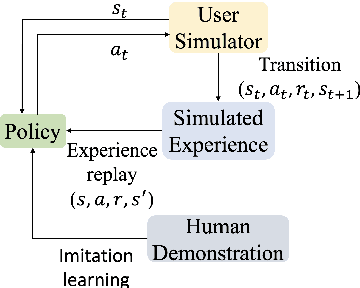
Dialogue Policy Learning is a key component in a task-oriented dialogue system (TDS) that decides the next action of the system given the dialogue state at each turn. Reinforcement Learning (RL) is commonly chosen to learn the dialogue policy, regarding the user as the environment and the system as the agent. Many benchmark datasets and algorithms have been created to facilitate the development and evaluation of dialogue policy based on RL. In this paper, we survey recent advances and challenges in dialogue policy from the prescriptive of RL. More specifically, we identify the major problems and summarize corresponding solutions for RL-based dialogue policy learning. Besides, we provide a comprehensive survey of applying RL to dialogue policy learning by categorizing recent methods into basic elements in RL. We believe this survey can shed a light on future research in dialogue management.