 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
RESTRAIN: Reinforcement Learning-Based Secure Framework for Trigger-Action IoT Environment
Mar 12, 2025Internet of Things (IoT) platforms with trigger-action capability allow event conditions to trigger actions in IoT devices autonomously by creating a chain of interactions. Adversaries exploit this chain of interactions to maliciously inject fake event conditions into IoT hubs, triggering unauthorized actions on target IoT devices to implement remote injection attacks. Existing defense mechanisms focus mainly on the verification of event transactions using physical event fingerprints to enforce the security policies to block unsafe event transactions. These approaches are designed to provide offline defense against injection attacks. The state-of-the-art online defense mechanisms offer real-time defense, but extensive reliability on the inference of attack impacts on the IoT network limits the generalization capability of these approaches. In this paper, we propose a platform-independent multi-agent online defense system, namely RESTRAIN, to counter remote injection attacks at runtime. RESTRAIN allows the defense agent to profile attack actions at runtime and leverages reinforcement learning to optimize a defense policy that complies with the security requirements of the IoT network. The experimental results show that the defense agent effectively takes real-time defense actions against complex and dynamic remote injection attacks and maximizes the security gain with minimal computational overhead.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
UniRetriever: Multi-task Candidates Selection for Various Context-Adaptive Conversational Retrieval
Feb 28, 2024
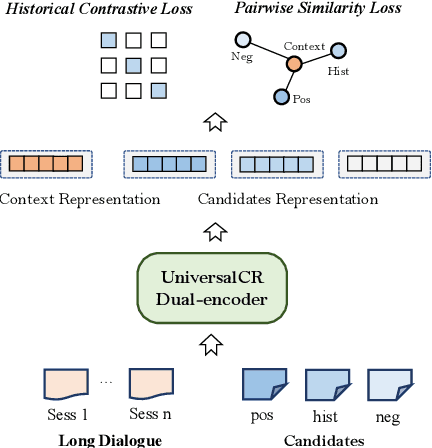
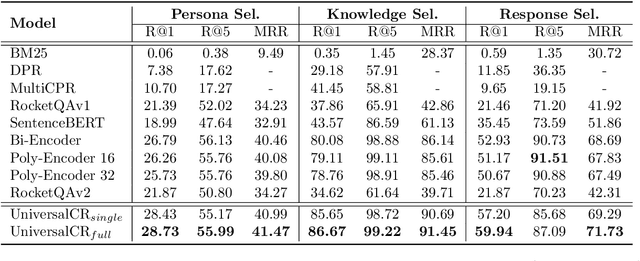
Conversational retrieval refers to an information retrieval system that operates in an iterative and interactive manner, requiring the retrieval of various external resources, such as persona, knowledge, and even response, to effectively engage with the user and successfully complete the dialogue. However, most previous work trained independent retrievers for each specific resource, resulting in sub-optimal performance and low efficiency. Thus, we propose a multi-task framework function as a universal retriever for three dominant retrieval tasks during the conversation: persona selection, knowledge selection, and response selection. To this end, we design a dual-encoder architecture consisting of a context-adaptive dialogue encoder and a candidate encoder, aiming to attention to the relevant context from the long dialogue and retrieve suitable candidates by simply a dot product. Furthermore, we introduce two loss constraints to capture the subtle relationship between dialogue context and different candidates by regarding historically selected candidates as hard negatives. Extensive experiments and analysis establish state-of-the-art retrieval quality both within and outside its training domain, revealing the promising potential and generalization capability of our model to serve as a universal retriever for different candidate selection tasks simultaneously.
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Feb 21, 2024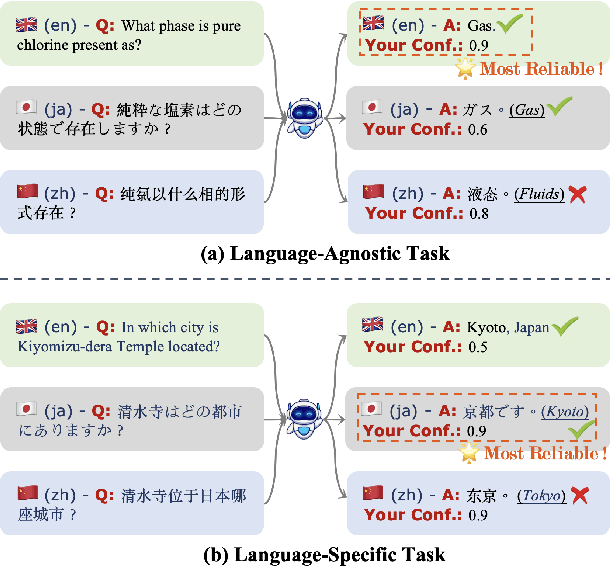
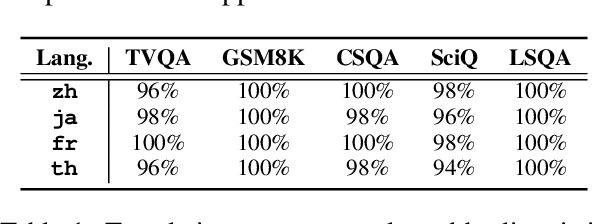
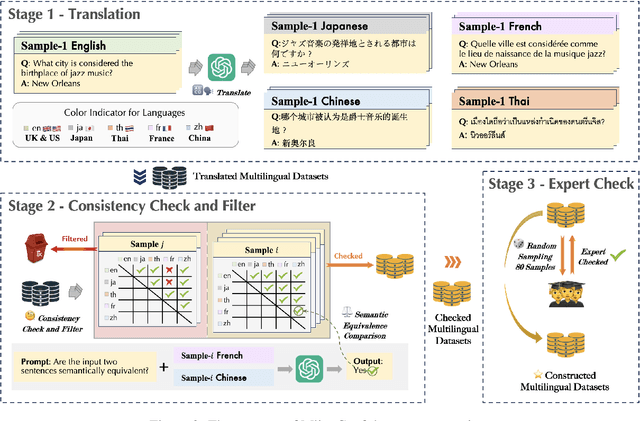

The tendency of Large Language Models to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of Multi-lingual confidence estimation (MlingConf) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Second, we delve into the performance of confidence estimations and examine how these confidence scores can enhance LLM performance through self-refinement across diverse languages. Finally, we propose a cross-lingual confidence estimation method to achieve more precise confidence scores. The experimental results showcase the performance of various confidence estimation methods across different languages as well as present that our proposed cross-lingual confidence estimation technique significantly enhances confidence estimation and outperforms several baseline methods.
Improving Factual Consistency for Knowledge-Grounded Dialogue Systems via Knowledge Enhancement and Alignment
Oct 16, 2023Pretrained language models (PLMs) based knowledge-grounded dialogue systems are prone to generate responses that are factually inconsistent with the provided knowledge source. In such inconsistent responses, the dialogue models fail to accurately express the external knowledge they rely upon. Inspired by previous work which identified that feed-forward networks (FFNs) within Transformers are responsible for factual knowledge expressions, we investigate two methods to efficiently improve the factual expression capability {of FFNs} by knowledge enhancement and alignment respectively. We first propose \textsc{K-Dial}, which {explicitly} introduces {extended FFNs in Transformers to enhance factual knowledge expressions} given the specific patterns of knowledge-grounded dialogue inputs. Additionally, we apply the reinforcement learning for factual consistency (RLFC) method to implicitly adjust FFNs' expressions in responses by aligning with gold knowledge for the factual consistency preference. To comprehensively assess the factual consistency and dialogue quality of responses, we employ extensive automatic measures and human evaluations including sophisticated fine-grained NLI-based metrics. Experimental results on WoW and CMU\_DoG datasets demonstrate that our methods efficiently enhance the ability of the FFN module to convey factual knowledge, validating the efficacy of improving factual consistency for knowledge-grounded dialogue systems.
Large Language Models as Source Planner for Personalized Knowledge-grounded Dialogue
Oct 13, 2023



Open-domain dialogue system usually requires different sources of knowledge to generate more informative and evidential responses. However, existing knowledge-grounded dialogue systems either focus on a single knowledge source or overlook the dependency between multiple sources of knowledge, which may result in generating inconsistent or even paradoxical responses. To incorporate multiple knowledge sources and dependencies between them, we propose SAFARI, a novel framework that leverages the exceptional capabilities of large language models (LLMs) in planning, understanding, and incorporating under both supervised and unsupervised settings. Specifically, SAFARI decouples the knowledge grounding into multiple sources and response generation, which allows easy extension to various knowledge sources including the possibility of not using any sources. To study the problem, we construct a personalized knowledge-grounded dialogue dataset \textit{\textbf{K}nowledge \textbf{B}ehind \textbf{P}ersona}~(\textbf{KBP}), which is the first to consider the dependency between persona and implicit knowledge. Experimental results on the KBP dataset demonstrate that the SAFARI framework can effectively produce persona-consistent and knowledge-enhanced responses.
SELF: Language-Driven Self-Evolution for Large Language Model
Oct 07, 2023



Large Language Models (LLMs) have showcased remarkable versatility across diverse domains. However, the pathway toward autonomous model development, a cornerstone for achieving human-level learning and advancing autonomous AI, remains largely uncharted. We introduce an innovative approach, termed "SELF" (Self-Evolution with Language Feedback). This methodology empowers LLMs to undergo continual self-evolution. Furthermore, SELF employs language-based feedback as a versatile and comprehensive evaluative tool, pinpointing areas for response refinement and bolstering the stability of self-evolutionary training. Initiating with meta-skill learning, SELF acquires foundational meta-skills with a focus on self-feedback and self-refinement. These meta-skills are critical, guiding the model's subsequent self-evolution through a cycle of perpetual training with self-curated data, thereby enhancing its intrinsic abilities. Given unlabeled instructions, SELF equips the model with the capability to autonomously generate and interactively refine responses. This synthesized training data is subsequently filtered and utilized for iterative fine-tuning, enhancing the model's capabilities. Experimental results on representative benchmarks substantiate that SELF can progressively advance its inherent abilities without the requirement of human intervention, thereby indicating a viable pathway for autonomous model evolution. Additionally, SELF can employ online self-refinement strategy to produce responses of superior quality. In essence, the SELF framework signifies a progressive step towards autonomous LLM development, transforming the LLM from a mere passive recipient of information into an active participant in its own evolution.
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
Mar 20, 2023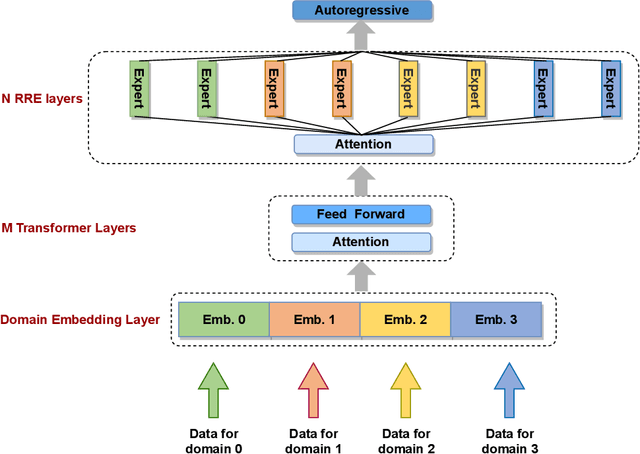

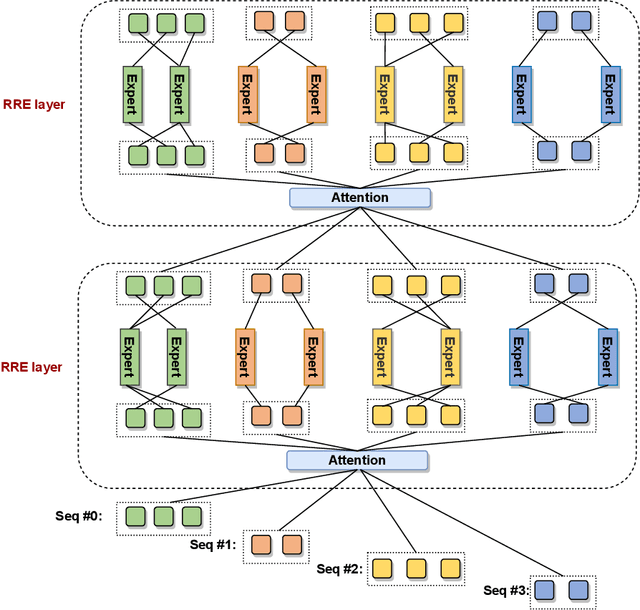
The scaling of large language models has greatly improved natural language understanding, generation, and reasoning. In this work, we develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework, and present the language model with 1.085T parameters named PanGu-{\Sigma}. With parameter inherent from PanGu-{\alpha}, we extend the dense Transformer model to sparse one with Random Routed Experts (RRE), and efficiently train the model over 329B tokens by using Expert Computation and Storage Separation(ECSS). This resulted in a 6.3x increase in training throughput through heterogeneous computing. Our experimental findings show that PanGu-{\Sigma} provides state-of-the-art performance in zero-shot learning of various Chinese NLP downstream tasks. Moreover, it demonstrates strong abilities when fine-tuned in application data of open-domain dialogue, question answering, machine translation and code generation.