 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Paper and Code
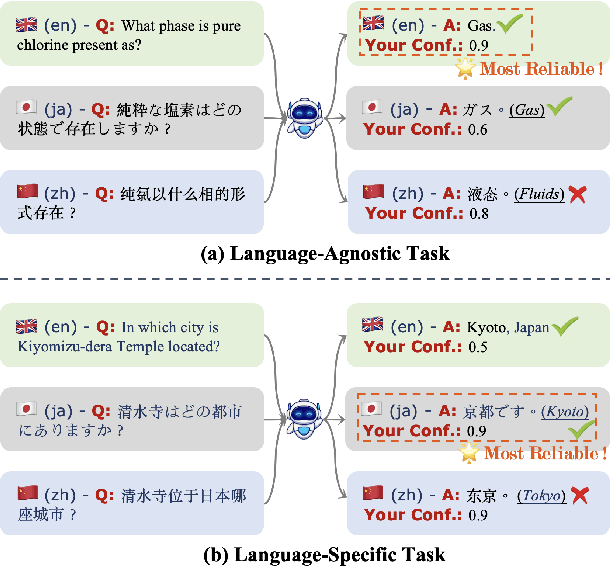
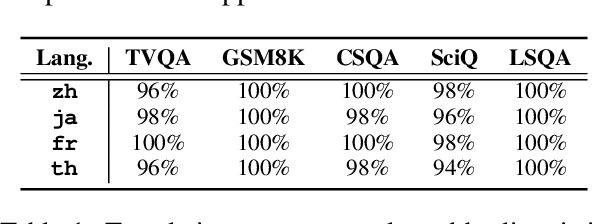
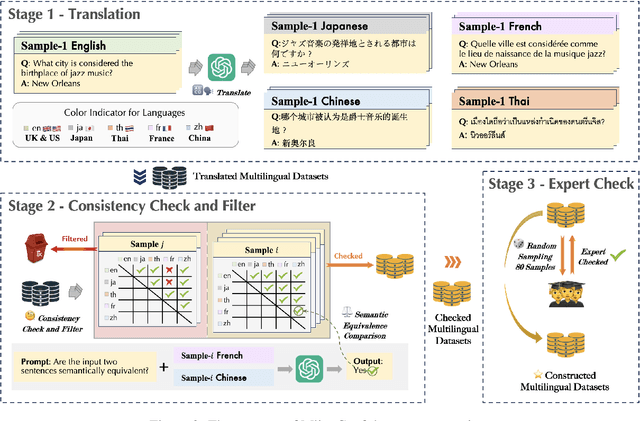

The tendency of Large Language Models to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of Multi-lingual confidence estimation (MlingConf) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Second, we delve into the performance of confidence estimations and examine how these confidence scores can enhance LLM performance through self-refinement across diverse languages. Finally, we propose a cross-lingual confidence estimation method to achieve more precise confidence scores. The experimental results showcase the performance of various confidence estimation methods across different languages as well as present that our proposed cross-lingual confidence estimation technique significantly enhances confidence estimation and outperforms several baseline methods.