 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiralFormer: Looped Transformers Can Learn Hierarchical Dependencies via Multi-Resolution Recursion
Feb 12, 2026Recursive (looped) Transformers decouple computational depth from parameter depth by repeatedly applying shared layers, providing an explicit architectural primitive for iterative refinement and latent reasoning. However, early looped Transformers often underperform non-recursive baselines of equal compute. While recent literature has introduced more effective recursion mechanisms to mitigate this gap, existing architectures still operate at a fixed, full-token resolution, neglecting the potential efficiency of computing over compressed latent representations. In this paper, we propose SpiralFormer, a looped Transformer that executes recurrence under a multi-resolution recursion schedule. We provide probing evidence that multi-resolution recursion enables the model to learn hierarchical dependencies by inducing iteration-wise functional specialization across different scales. Empirically, SpiralFormer achieves better parameter and compute efficiency than both looped and non-looped baselines across model scales from 160M to 1.4B, establishing sequence resolution as a potential axis for scaling recursive architectures.
MeSH: Memory-as-State-Highways for Recursive Transformers
Oct 09, 2025Recursive transformers reuse parameters and iterate over hidden states multiple times, decoupling compute depth from parameter depth. However, under matched compute, recursive models with fewer parameters often lag behind non-recursive counterparts. By probing hidden states, we trace this performance gap to two primary bottlenecks: undifferentiated computation, where the core is forced to adopt a similar computational pattern at every iteration, and information overload, where long-lived and transient information must coexist in a single hidden state. To address the issues, we introduce a Memory-as-State-Highways (MeSH) scheme, which externalizes state management into an explicit memory buffer and employs lightweight routers to dynamically diversify computation across iterations. Probing visualizations confirm that MeSH successfully resolves the pathologies by inducing functional specialization across iterations. On the Pythia suite (160M-1.4B), MeSH-enhanced recursive transformers consistently improve over recursive baselines and outperforms its larger non-recursive counterpart at the 1.4B scale, improving average downstream accuracy by +1.06% with 33% fewer non-embedding parameters. Our analysis establishes MeSH as a scalable and principled architecture for building stronger recursive models.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025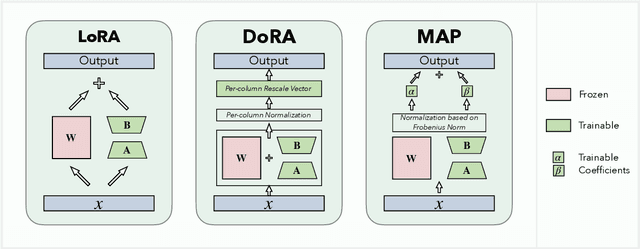
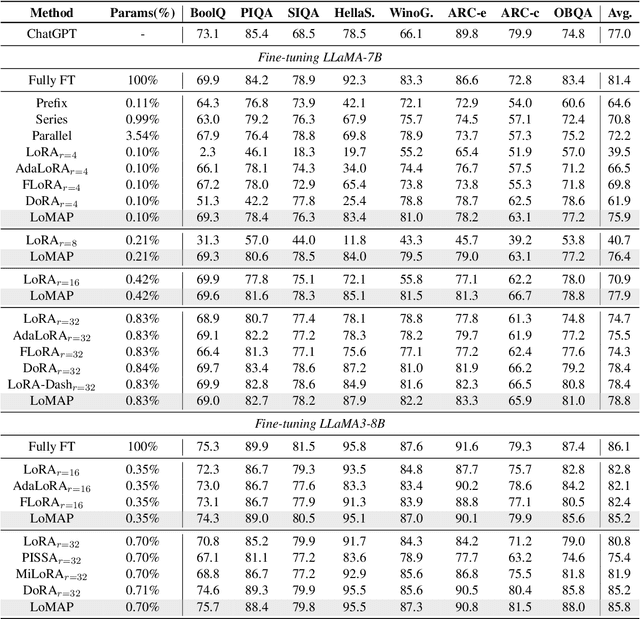
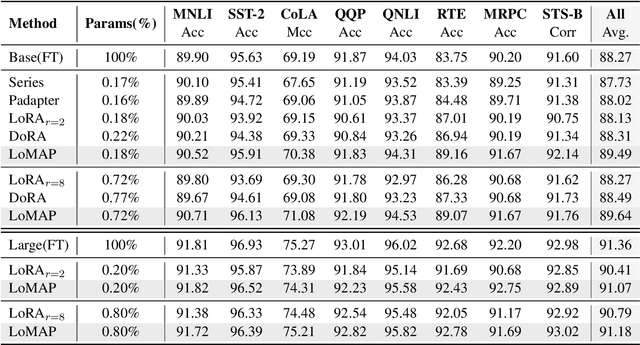

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
Weight Spectra Induced Efficient Model Adaptation
May 29, 2025Large-scale foundation models have demonstrated remarkable versatility across a wide range of downstream tasks. However, fully fine-tuning these models incurs prohibitive computational costs, motivating the development of Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, which introduces low-rank updates to pre-trained weights. Despite their empirical success, the underlying mechanisms by which PEFT modifies model parameters remain underexplored. In this work, we present a systematic investigation into the structural changes of weight matrices during fully fine-tuning. Through singular value decomposition (SVD), we reveal that fine-tuning predominantly amplifies the top singular values while leaving the remainder largely intact, suggesting that task-specific knowledge is injected into a low-dimensional subspace. Furthermore, we find that the dominant singular vectors are reoriented in task-specific directions, whereas the non-dominant subspace remains stable. Building on these insights, we propose a novel method that leverages learnable rescaling of top singular directions, enabling precise modulation of the most influential components without disrupting the global structure. Our approach achieves consistent improvements over strong baselines across multiple tasks, highlighting the efficacy of structurally informed fine-tuning.
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging
May 22, 2025Model merging offers a training-free alternative to multi-task learning by combining independently fine-tuned models into a unified one without access to raw data. However, existing approaches often rely on heuristics to determine the merging coefficients, limiting their scalability and generality. In this work, we revisit model merging through the lens of least-squares optimization and show that the optimal merging weights should scale with the amount of task-specific information encoded in each model. Based on this insight, we propose NAN, a simple yet effective method that estimates model merging coefficients via the inverse of parameter norm. NAN is training-free, plug-and-play, and applicable to a wide range of merging strategies. Extensive experiments on show that NAN consistently improves performance of baseline methods.
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
Mar 20, 2023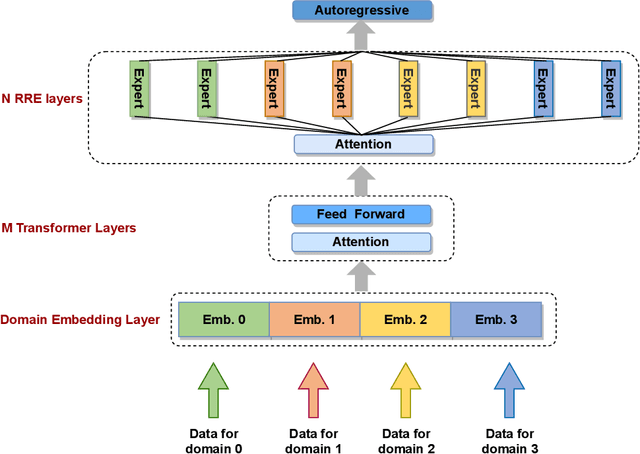

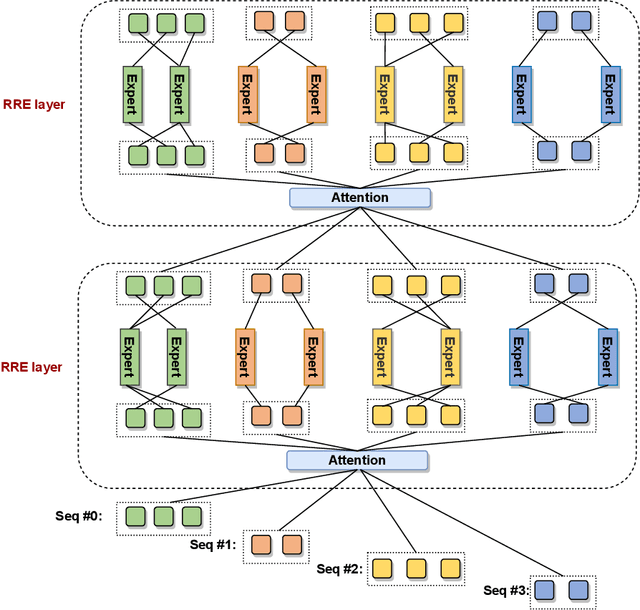
The scaling of large language models has greatly improved natural language understanding, generation, and reasoning. In this work, we develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework, and present the language model with 1.085T parameters named PanGu-{\Sigma}. With parameter inherent from PanGu-{\alpha}, we extend the dense Transformer model to sparse one with Random Routed Experts (RRE), and efficiently train the model over 329B tokens by using Expert Computation and Storage Separation(ECSS). This resulted in a 6.3x increase in training throughput through heterogeneous computing. Our experimental findings show that PanGu-{\Sigma} provides state-of-the-art performance in zero-shot learning of various Chinese NLP downstream tasks. Moreover, it demonstrates strong abilities when fine-tuned in application data of open-domain dialogue, question answering, machine translation and code generation.
Sparse Structure Search for Parameter-Efficient Tuning
Jun 15, 2022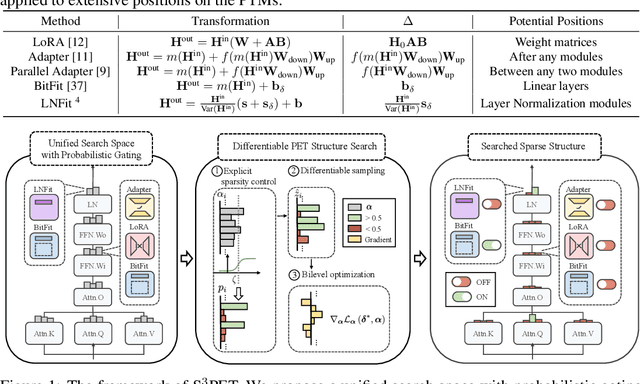
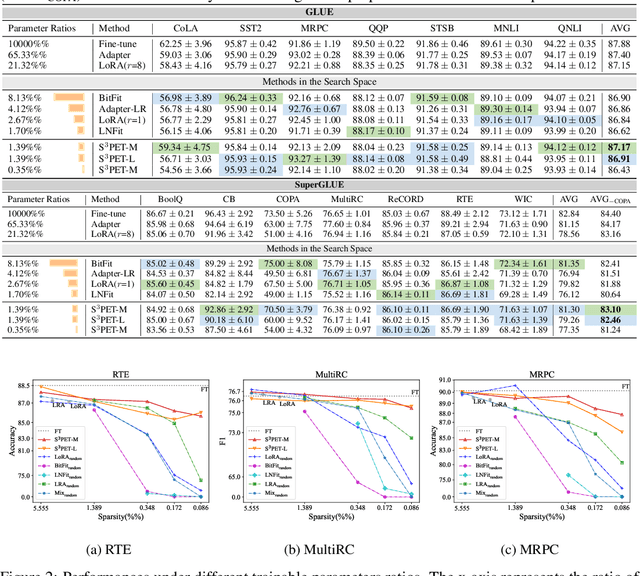
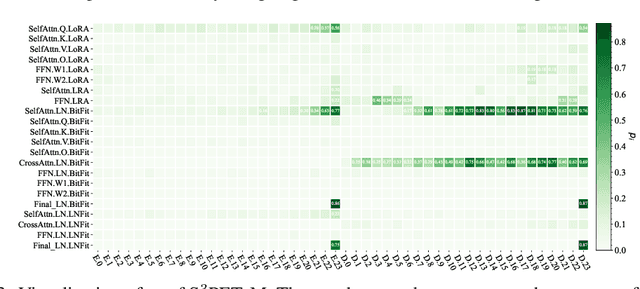
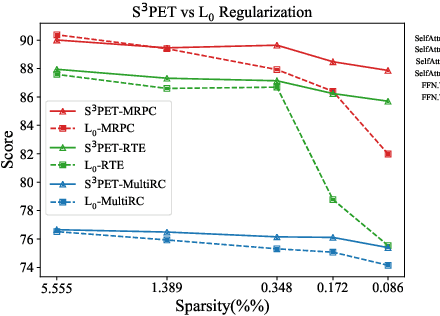
Adapting large pre-trained models (PTMs) through fine-tuning imposes prohibitive computational and storage burdens. Recent studies of parameter-efficient tuning (PET) find that only optimizing a small portion of parameters conditioned on PTMs could yield on-par performance compared to conventional fine-tuning. Generally, PET methods exquisitely design parameter-efficient modules (PET modules) which could be applied to arbitrary fine-grained positions inside PTMs. However, the effectiveness of these fine-grained positions largely relies on sophisticated manual designation, thereby usually producing sub-optimal results. In contrast to the manual designation, we explore constructing PET modules in an automatic manner. We automatically \textbf{S}earch for the \textbf{S}parse \textbf{S}tructure of \textbf{P}arameter-\textbf{E}fficient \textbf{T}uning (S$^3$PET). Based on a unified framework of various PET methods, S$^3$PET conducts the differentiable PET structure search through bi-level optimization and proposes shifted global sigmoid method to explicitly control the number of trainable parameters. Extensive experiments show that S$^3$PET surpasses manual and random structures with less trainable parameters. The searched structures preserve more than 99\% fine-tuning performance with 0.01\% trainable parameters. Moreover, the advantage of S$^3$PET is amplified with extremely low trainable parameters budgets (0.0009\%$\sim$0.01\%). The searched structures are transferable and explainable, providing suggestions and guidance for the future design of PET methods.
HyperPELT: Unified Parameter-Efficient Language Model Tuning for Both Language and Vision-and-Language Tasks
Mar 08, 2022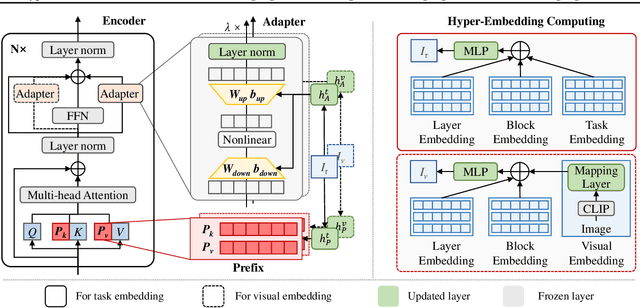
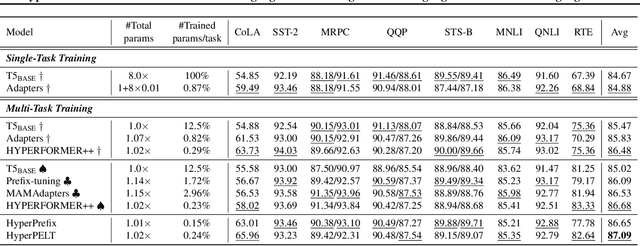
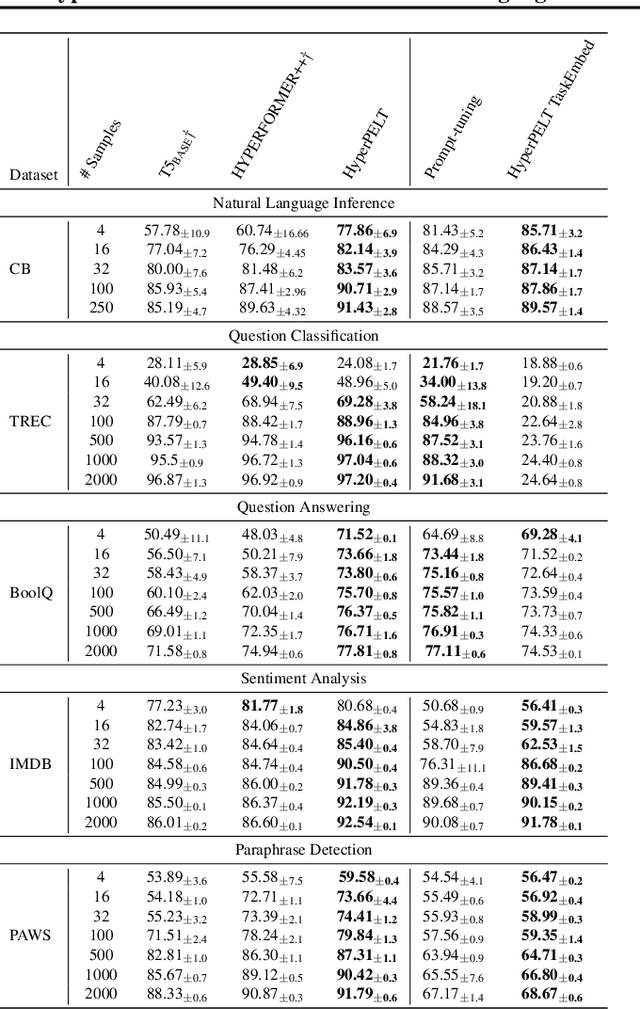
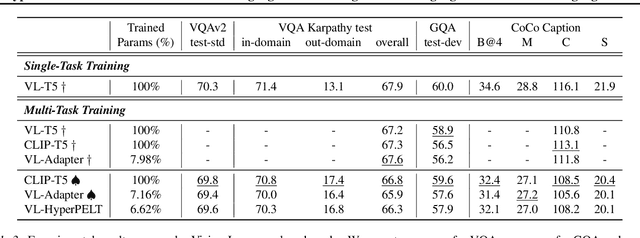
The workflow of pretraining and fine-tuning has emerged as a popular paradigm for solving various NLP and V&L (Vision-and-Language) downstream tasks. With the capacity of pretrained models growing rapidly, how to perform parameter-efficient fine-tuning has become fairly important for quick transfer learning and deployment. In this paper, we design a novel unified parameter-efficient transfer learning framework that works effectively on both pure language and V&L tasks. In particular, we use a shared hypernetwork that takes trainable hyper-embeddings as input, and outputs weights for fine-tuning different small modules in a pretrained language model, such as tuning the parameters inserted into multi-head attention blocks (i.e., prefix-tuning) and feed-forward blocks (i.e., adapter-tuning). We define a set of embeddings (e.g., layer, block, task and visual embeddings) as the key components to calculate hyper-embeddings, which thus can support both pure language and V&L tasks. Our proposed framework adds fewer trainable parameters in multi-task learning while achieving superior performances and transfer ability compared to state-of-the-art methods. Empirical results on the GLUE benchmark and multiple V&L tasks confirm the effectiveness of our framework on both textual and visual modalities.