 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom "What" to "How": Constrained Reasoning for Autoregressive Image Generation
Mar 03, 2026Autoregressive image generation has seen recent improvements with the introduction of chain-of-thought and reinforcement learning. However, current methods merely specify "What" details to depict by rewriting the input prompt, yet fundamentally fail to reason about "How" to structure the overall image. This inherent limitation gives rise to persistent issues, such as spatial ambiguity directly causing unrealistic object overlaps. To bridge this gap, we propose CoR-Painter, a novel framework that pioneers a "How-to-What" paradigm by introducing Constrained Reasoning to guide the autoregressive generation. Specifically, it first deduces "How to draw" by deriving a set of visual constraints from the input prompt, which explicitly govern spatial relationships, key attributes, and compositional rules. These constraints steer the subsequent generation of a detailed description "What to draw", providing a structurally sound and coherent basis for accurate visual synthesis. Additionally, we introduce a Dual-Objective GRPO strategy that specifically optimizes the textual constrained reasoning and visual projection processes to ensure the coherence and quality of the entire generation pipeline. Extensive experiments on T2I-CompBench, GenEval, and WISE demonstrate that our method achieves state-of-the-art performance, with significant improvements in spatial metrics (e.g., +5.41% on T2I-CompBench).
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
ProDS: Preference-oriented Data Selection for Instruction Tuning
May 19, 2025Instruction data selection aims to identify a high-quality subset from the training set that matches or exceeds the performance of the full dataset on target tasks. Existing methods focus on the instruction-to-response mapping, but neglect the human preference for diverse responses. In this paper, we propose Preference-oriented Data Selection method (ProDS) that scores training samples based on their alignment with preferences observed in the target set. Our key innovation lies in shifting the data selection criteria from merely estimating features for accurate response generation to explicitly aligning training samples with human preferences in target tasks. Specifically, direct preference optimization (DPO) is employed to estimate human preferences across diverse responses. Besides, a bidirectional preference synthesis strategy is designed to score training samples according to both positive preferences and negative preferences. Extensive experimental results demonstrate our superiority to existing task-agnostic and targeted methods.
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
Apr 06, 2022Procedural Multimodal Documents (PMDs) organize textual instructions and corresponding images step by step. Comprehending PMDs and inducing their representations for the downstream reasoning tasks is designated as Procedural MultiModal Machine Comprehension (M3C). In this study, we approach Procedural M3C at a fine-grained level (compared with existing explorations at a document or sentence level), that is, entity. With delicate consideration, we model entity both in its temporal and cross-modal relation and propose a novel Temporal-Modal Entity Graph (TMEG). Specifically, graph structure is formulated to capture textual and visual entities and trace their temporal-modal evolution. In addition, a graph aggregation module is introduced to conduct graph encoding and reasoning. Comprehensive experiments across three Procedural M3C tasks are conducted on a traditional dataset RecipeQA and our new dataset CraftQA, which can better evaluate the generalization of TMEG.
HyperPELT: Unified Parameter-Efficient Language Model Tuning for Both Language and Vision-and-Language Tasks
Mar 08, 2022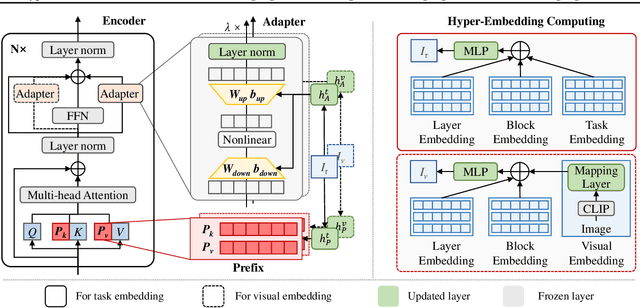
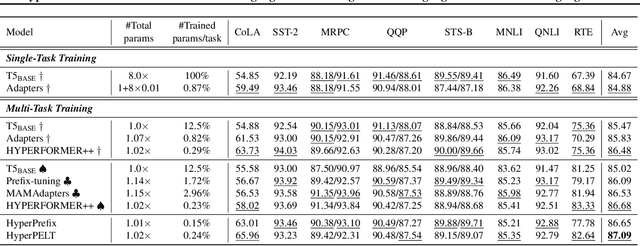
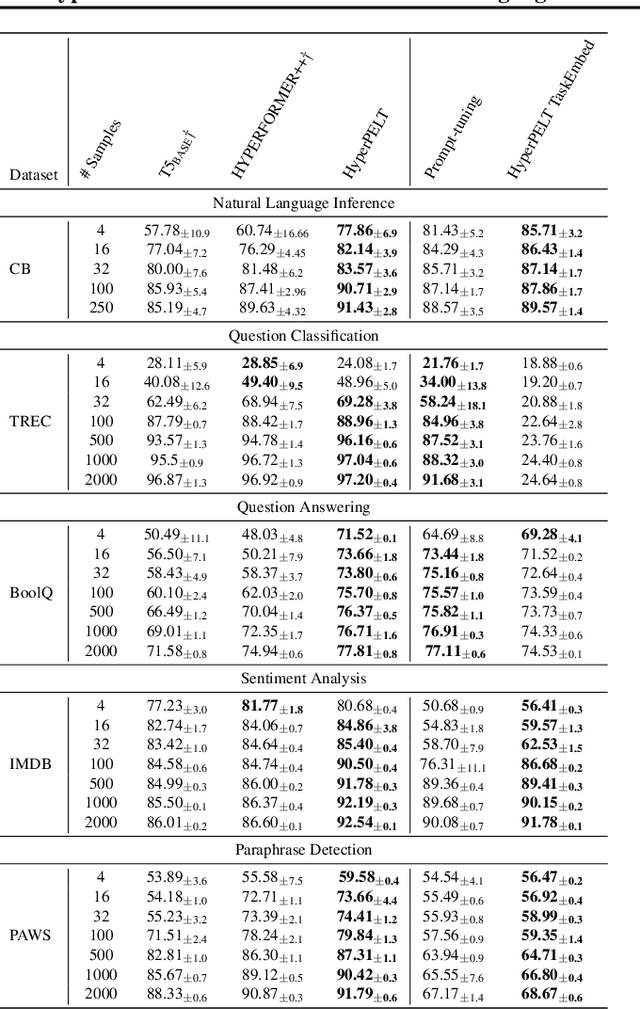
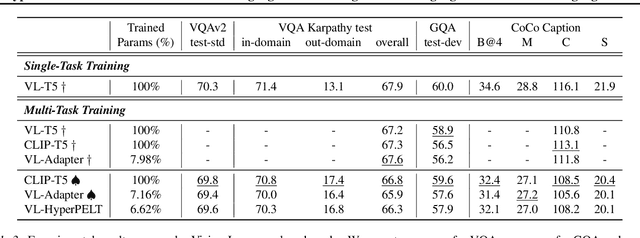
The workflow of pretraining and fine-tuning has emerged as a popular paradigm for solving various NLP and V&L (Vision-and-Language) downstream tasks. With the capacity of pretrained models growing rapidly, how to perform parameter-efficient fine-tuning has become fairly important for quick transfer learning and deployment. In this paper, we design a novel unified parameter-efficient transfer learning framework that works effectively on both pure language and V&L tasks. In particular, we use a shared hypernetwork that takes trainable hyper-embeddings as input, and outputs weights for fine-tuning different small modules in a pretrained language model, such as tuning the parameters inserted into multi-head attention blocks (i.e., prefix-tuning) and feed-forward blocks (i.e., adapter-tuning). We define a set of embeddings (e.g., layer, block, task and visual embeddings) as the key components to calculate hyper-embeddings, which thus can support both pure language and V&L tasks. Our proposed framework adds fewer trainable parameters in multi-task learning while achieving superior performances and transfer ability compared to state-of-the-art methods. Empirical results on the GLUE benchmark and multiple V&L tasks confirm the effectiveness of our framework on both textual and visual modalities.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
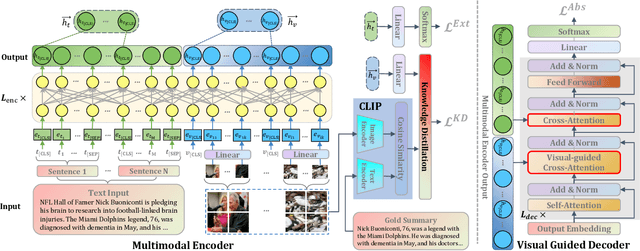
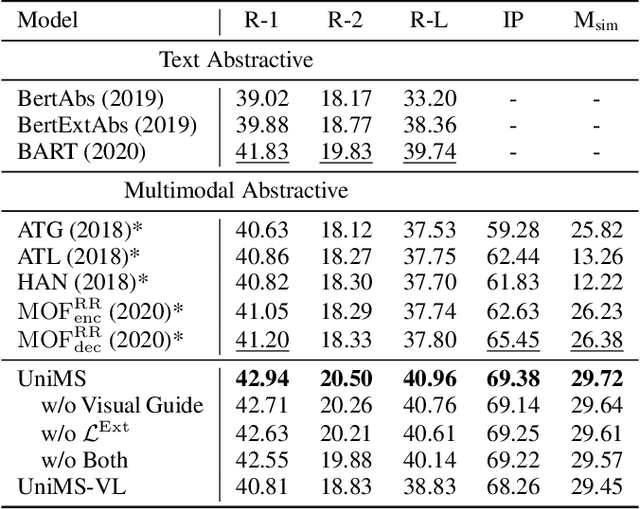
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.