 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom "What" to "How": Constrained Reasoning for Autoregressive Image Generation
Mar 03, 2026Autoregressive image generation has seen recent improvements with the introduction of chain-of-thought and reinforcement learning. However, current methods merely specify "What" details to depict by rewriting the input prompt, yet fundamentally fail to reason about "How" to structure the overall image. This inherent limitation gives rise to persistent issues, such as spatial ambiguity directly causing unrealistic object overlaps. To bridge this gap, we propose CoR-Painter, a novel framework that pioneers a "How-to-What" paradigm by introducing Constrained Reasoning to guide the autoregressive generation. Specifically, it first deduces "How to draw" by deriving a set of visual constraints from the input prompt, which explicitly govern spatial relationships, key attributes, and compositional rules. These constraints steer the subsequent generation of a detailed description "What to draw", providing a structurally sound and coherent basis for accurate visual synthesis. Additionally, we introduce a Dual-Objective GRPO strategy that specifically optimizes the textual constrained reasoning and visual projection processes to ensure the coherence and quality of the entire generation pipeline. Extensive experiments on T2I-CompBench, GenEval, and WISE demonstrate that our method achieves state-of-the-art performance, with significant improvements in spatial metrics (e.g., +5.41% on T2I-CompBench).
A Comprehensive Survey on Video Scene Parsing:Advances, Challenges, and Prospects
Jun 16, 2025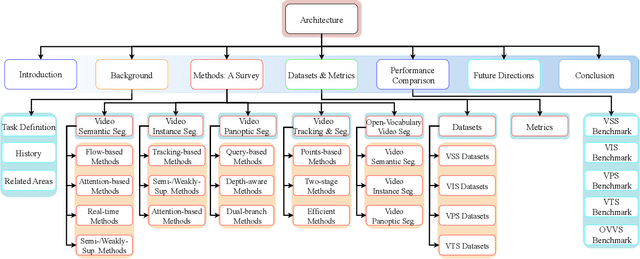



Video Scene Parsing (VSP) has emerged as a cornerstone in computer vision, facilitating the simultaneous segmentation, recognition, and tracking of diverse visual entities in dynamic scenes. In this survey, we present a holistic review of recent advances in VSP, covering a wide array of vision tasks, including Video Semantic Segmentation (VSS), Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), as well as Video Tracking and Segmentation (VTS), and Open-Vocabulary Video Segmentation (OVVS). We systematically analyze the evolution from traditional hand-crafted features to modern deep learning paradigms -- spanning from fully convolutional networks to the latest transformer-based architectures -- and assess their effectiveness in capturing both local and global temporal contexts. Furthermore, our review critically discusses the technical challenges, ranging from maintaining temporal consistency to handling complex scene dynamics, and offers a comprehensive comparative study of datasets and evaluation metrics that have shaped current benchmarking standards. By distilling the key contributions and shortcomings of state-of-the-art methodologies, this survey highlights emerging trends and prospective research directions that promise to further elevate the robustness and adaptability of VSP in real-world applications.
ProDS: Preference-oriented Data Selection for Instruction Tuning
May 19, 2025Instruction data selection aims to identify a high-quality subset from the training set that matches or exceeds the performance of the full dataset on target tasks. Existing methods focus on the instruction-to-response mapping, but neglect the human preference for diverse responses. In this paper, we propose Preference-oriented Data Selection method (ProDS) that scores training samples based on their alignment with preferences observed in the target set. Our key innovation lies in shifting the data selection criteria from merely estimating features for accurate response generation to explicitly aligning training samples with human preferences in target tasks. Specifically, direct preference optimization (DPO) is employed to estimate human preferences across diverse responses. Besides, a bidirectional preference synthesis strategy is designed to score training samples according to both positive preferences and negative preferences. Extensive experimental results demonstrate our superiority to existing task-agnostic and targeted methods.
BiDeV: Bilateral Defusing Verification for Complex Claim Fact-Checking
Feb 22, 2025

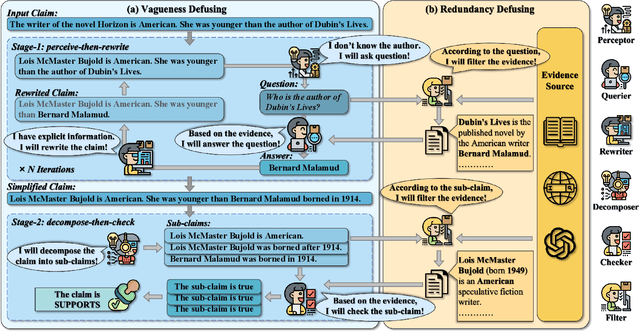
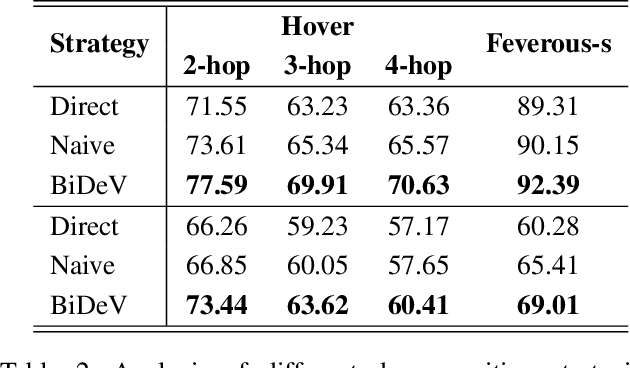
Complex claim fact-checking performs a crucial role in disinformation detection. However, existing fact-checking methods struggle with claim vagueness, specifically in effectively handling latent information and complex relations within claims. Moreover, evidence redundancy, where nonessential information complicates the verification process, remains a significant issue. To tackle these limitations, we propose Bilateral Defusing Verification (BiDeV), a novel fact-checking working-flow framework integrating multiple role-played LLMs to mimic the human-expert fact-checking process. BiDeV consists of two main modules: Vagueness Defusing identifies latent information and resolves complex relations to simplify the claim, and Redundancy Defusing eliminates redundant content to enhance the evidence quality. Extensive experimental results on two widely used challenging fact-checking benchmarks (Hover and Feverous-s) demonstrate that our BiDeV can achieve the best performance under both gold and open settings. This highlights the effectiveness of BiDeV in handling complex claims and ensuring precise fact-checking
AoM: Detecting Aspect-oriented Information for Multimodal Aspect-Based Sentiment Analysis
May 31, 2023Multimodal aspect-based sentiment analysis (MABSA) aims to extract aspects from text-image pairs and recognize their sentiments. Existing methods make great efforts to align the whole image to corresponding aspects. However, different regions of the image may relate to different aspects in the same sentence, and coarsely establishing image-aspect alignment will introduce noise to aspect-based sentiment analysis (i.e., visual noise). Besides, the sentiment of a specific aspect can also be interfered by descriptions of other aspects (i.e., textual noise). Considering the aforementioned noises, this paper proposes an Aspect-oriented Method (AoM) to detect aspect-relevant semantic and sentiment information. Specifically, an aspect-aware attention module is designed to simultaneously select textual tokens and image blocks that are semantically related to the aspects. To accurately aggregate sentiment information, we explicitly introduce sentiment embedding into AoM, and use a graph convolutional network to model the vision-text and text-text interaction. Extensive experiments demonstrate the superiority of AoM to existing methods. The source code is publicly released at https://github.com/SilyRab/AoM.
HyperPELT: Unified Parameter-Efficient Language Model Tuning for Both Language and Vision-and-Language Tasks
Mar 08, 2022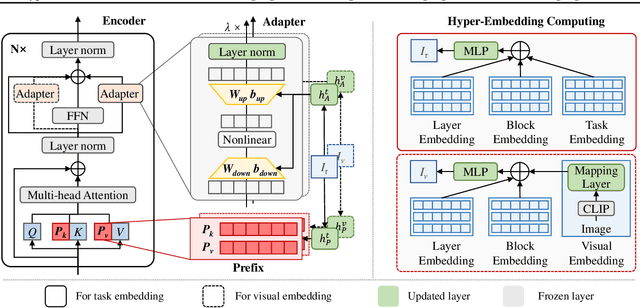
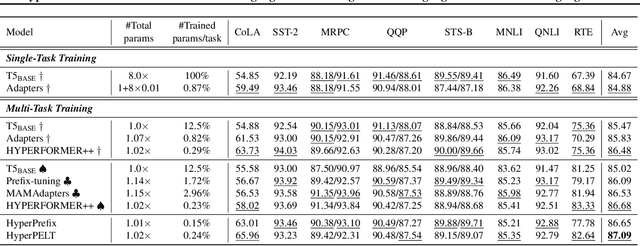
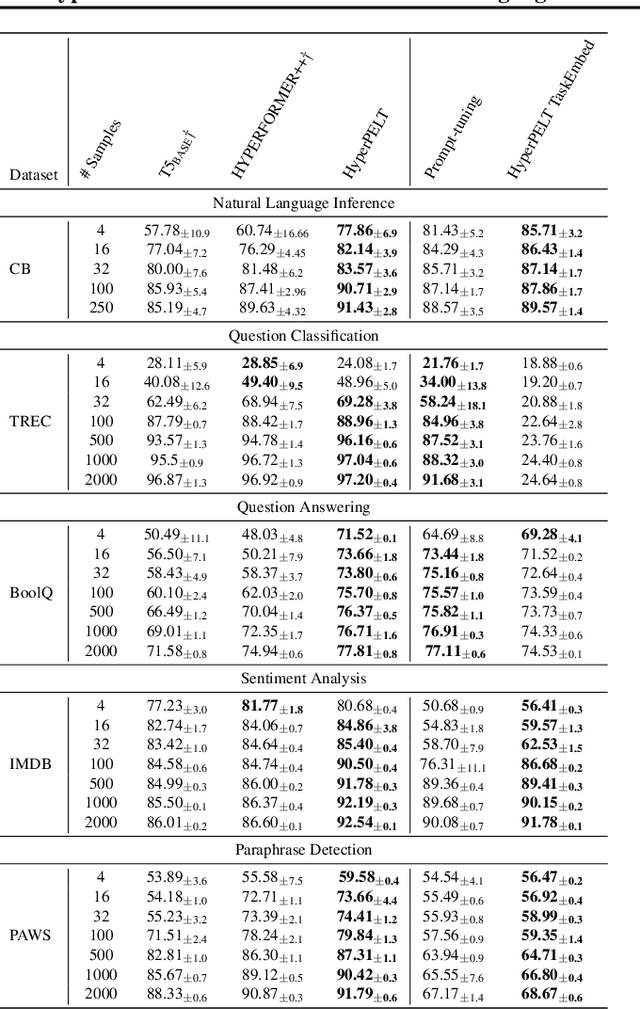
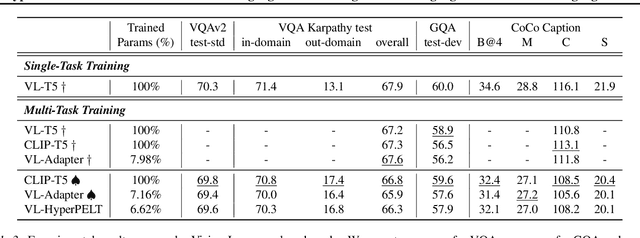
The workflow of pretraining and fine-tuning has emerged as a popular paradigm for solving various NLP and V&L (Vision-and-Language) downstream tasks. With the capacity of pretrained models growing rapidly, how to perform parameter-efficient fine-tuning has become fairly important for quick transfer learning and deployment. In this paper, we design a novel unified parameter-efficient transfer learning framework that works effectively on both pure language and V&L tasks. In particular, we use a shared hypernetwork that takes trainable hyper-embeddings as input, and outputs weights for fine-tuning different small modules in a pretrained language model, such as tuning the parameters inserted into multi-head attention blocks (i.e., prefix-tuning) and feed-forward blocks (i.e., adapter-tuning). We define a set of embeddings (e.g., layer, block, task and visual embeddings) as the key components to calculate hyper-embeddings, which thus can support both pure language and V&L tasks. Our proposed framework adds fewer trainable parameters in multi-task learning while achieving superior performances and transfer ability compared to state-of-the-art methods. Empirical results on the GLUE benchmark and multiple V&L tasks confirm the effectiveness of our framework on both textual and visual modalities.